Blog
식스티헤르츠의
기술과 가치에 대해 전합니다
All
Tech
Insight
People & Culture
Impact


Tech
[개발자 인터뷰 ①] “기술에 얽매이지 않고 현실 문제 해결에 집중하는 실용적인 개발을 하고 싶어요.” / Tech Lead 최성원 님
본인 소개 부탁드립니다.
안녕하세요. 개발 조직을 리드하고 있는 최성원입니다.
입사한 지는 약 3년 정도 되었고, 서비스 개발을 중심으로 다양한 업무를 수행해왔어요. 특히 기술과 비즈니스를 함께 이해하는 경험을 통해 개발자의 시선에서 서비스의 방향과 가치를 고민하고 있습니다.
식스티헤르츠 합류 전 성원님의 커리어를 소개해주세요.
2009년쯤, 아이폰이 막 출시되면서 ‘앱스토어’라는 새로운 플랫폼이 등장했어요. 대학 선배와 함께 “우리도 직접 앱을 만들어보자”는 이야기를 하게 됐고, ‘쓰임epub’라는 회사를 창업해서 저는 CTO 역할로 합류했어요. 사회적으로 의미 있게 쓰이는 서비스를 만들면 좋겠다는 마음을 담은 회사였죠.
이후 회사가 점차 커지면서 한 콘텐츠 회사로 합류하게 되었는데, 그 회사가 지금의 카카오엔터테인먼트에요. 처음에는 iOS 개발자로 시작했고, 이후 웹 개발로 영역을 넓혀 2017년부터는 프론트엔드 개발자로 일을 하였지요. 카카오엔터테인먼트에서의 재직 기간은 약 10년 정도였는데, 그 중 3년 정도는 팀장을 맡아 개발 조직을 이끌었어요.
식스티헤르츠 합류 스토리도 궁금해요.
식스티헤르츠에서 먼저 제안을 주셨고, 당시 저는 카카오엔터테인먼트에서 팀장으로 일하며 큰 프로젝트를 맡고 있어서 처음 제안은 고사했어요. 그런데 신기하게도, 그 프로젝트가 마무리될 즈음 다시 연락이 왔어요. (웃음)
그 시점에 제가 고민하던 게 하나 있었어요. 기술이 상향 평준화되면서, 사람들이 플랫폼을 선택하는 기준이 ‘기술’보다는 ‘콘텐츠’나 ‘도메인 가치’로 옮겨가고 있다는 느낌이었거든요. 점점 내가 기술로 만들어낼 수 있는 임팩트가 줄어든다는 생각도 들었고요. 그때 식스티헤르츠의 ‘재생에너지’라는 도메인이 새롭고 매력적으로 다가왔어요. 아직 제가 경험해보지 못한 분야였고, 성장 가능성과 사회적 임팩트가 분명한 영역이라고 느껴졌기 때문이죠.
재생에너지 도메인은 실제로 와서 보니 어땠나요?
기존에 경험했던 콘텐츠 플랫폼과는 정말 달랐어요. 솔직히 말하면, 기술 환경만 놓고 보면 다소 낙후되어 있다고 말할 수 있고, 최신 기술과 트렌드 자체를 즐기는 개발자라면 처음엔 아쉬울 수도 있는 환경이었던 것이죠.
그런데 저는 결국 중요한 건 내가 가진 기술을 어디에, 어떻게 쓰느냐라고 생각해요. 그래서 그러한 환경이 제약으로 느껴지지는 않았어요. 특히 요즘은 AI 기술이 빠르게 발전하면서, 특정 기술의 난이도보다는 전체 구조를 이해하고 문제를 정의하는 역량이 더 중요해지고 있잖아요. 그런 점에서 보면 이러한 환경이 오히려 시대와 잘 맞는다고 느끼기도 해요. 특정 기술 스택이나 환경에 얽매이지 않고, 현실의 문제 해결에 집중하고 싶은 개발자라면 충분히 의미 있는 도메인이라고 생각해요.
방금 살짝 말씀하신 것 같은데 성원님은 어떤 개발자라고 생각하시나요?
“기술의 깊이보다 문제 해결의 깊이를 더 중요하게 생각합니다.”
저는 고객의 문제를 해결하고, 실제로 결과를 만들어내는 걸 좋아하는 개발자입니다. 팀에서도 늘 “우리는 실용적으로 가자”라는 이야기를 자주 해요.
예전에 학부 시절 근로장학생으로 일하면서 표절 검사용 텍스트 분절 프로그램을 만들어달라는 요청을 받은 적이 있어요. 당시 저는 윈도우 프로그램을 만들 줄 몰랐고, 그래서 콘솔 프로그램으로 간단히 구현했는데 그걸 오랫동안 잘 쓰시더라고요. 만약 그때 “이건 제가 못 해요”, “이 기술은 몰라요”라고 했다면 문제는 해결되지 않았겠죠. 저는 요구사항의 본질에 집중해서, 가능한 방식으로 빠르게 문제를 해결한 거예요.
고객은 ‘왜 필요한지’보다는 ‘무엇이 필요한지’만 이야기하는 경우가 많아요. 그럴 때 개발자가 한 발 더 나서서 문제를 정의하고, 현실적인 해결책을 제안해야 한다고 생각해요. 재생에너지 분야에서도 기본적인 태도는 크게 다르지 않다고 봐요.
성원님과 함께 일하는 식스티헤르츠 개발자들은 어떤 분들인가요?
사업에 관심이 많은 개발자들이 꽤 있어요. 개발자 입장에서는 사업의 전체 맥락을 모르면 혼란스러울 수 있는데, 이를 개발자의 언어로 설명해주는 경우는 많지 않거든요. 저는 개발과 사업 양쪽을 경험해왔기 때문에 제가 개발자의 시선에서 사업 이야기를 공유하면 팀원들이 정말 흥미롭게 듣고 또 서로 의견을 주고받고 있어요.
아 테크 리드들이요? 테크 리드 분들도 정말 자랑스럽죠. 기본적인 개발 역량도 뛰어나지만, 문제가 생기면 어떻게든 파고들어 해결하려는 사람들이에요. 답이 바로 보이지 않아도 결국 답을 만들어내는 사람들, 그래서 신뢰할 수 있는 사람들! 이러한 서로간의 신뢰가 우리팀의 가장 큰 강점이라고 생각해요.
개발팀의 조직 분위기는 어떤가요?
새로운 개발자가 들어오면 항상 하는 이야기가 있어요. “코드와 너무 사랑에 빠지지 말자.”
그래서 ‘코드가 곧 나다’라는 분위기는 없어요. 코드 리뷰에서도 직급과 상관없이 누구나 합리적인 의견을 낼 수 있고, 의견이 갈리면 다른 사람을 더 참여시켜 논의하죠. 그래도 판단이 어려우면, 굳이 내 의견을 끝까지 관철하기보다는 동료의 의견을 존중하자고 이야기해요. 결과가 비슷하다면 팀워크가 더 중요하니까요. 덕분에 지금까지 서로간의 관계로 인한 문제는 거의 없었어요.
앞으로 우리 개발팀이 어떤 팀이 되었으면 하나요?
AI 활용을 더 적극적으로 장려하고 싶어요. 이미 회사 차원에서 여러 도구를 지원하고 있고, 내부적으로도 AI를 활용해 산출물을 만드는 도구를 개발하고 있는데, 앞으로는 이런 흐름을 더 자연스럽게 조직문화에 반영하고 싶어요.
또 하나는 예측 가능한 팀이 되는 것이에요. 회사도 팀도 빠르게 성장하다 보니 조직 안정화가 숙제였는데, 이제는 성과와 결과를 조금 더 예측할 수 있는 팀이 되고 싶어요.
어떤 분이 팀에 합류하면 좋을까요?
고객이 진짜로 해결하고 싶은 문제가 무엇인지 질문하고, 본질을 파악하려는 분이었으면 좋겠어요. “이건 내 문제가 아니다”가 아니라, “내가 해결해보자”라고 생각하는 사람. 스스로를 문제 해결사라고 생각하고, 안 되는 이유를 찾기보다는 어떻게든 해결하려고 노력하는 분과 함께하고 싶어요.
마지막으로, 관심 있는 분들을 위해 성원님은 면접에서 어떤 걸 가장 중요하게 보시는지 알려주세요.
저는 정답이 없는 질문을 많이 해요. 예를 들면 개발자로서의 커리어 방향 같은 질문이요. 저는 개발을 하나의 도구라고 생각하기 때문에, 반드시 정해진 목표가 있어야 한다고 보지는 않아요. 다만 그 사람이 어디까지 바라보며 일하는지, 어떤 고민을 하고 있는지를 알고 싶어요. 그래서 특정한 답을 기대하기보다는, 평소 생각을 솔직하게 이야기해주시는 게 가장 좋아요.
—-------------------
식스티헤르츠는 지금 성장의 다음 단계를 함께 만들어갈 동료를 찾고 있습니다.
“내가 가진 기술로 세상의 문제를 해결하고 싶다면, 식스티헤르츠에 지원하세요.”
🌟 식스티헤르츠 채용공고 보러가기 (click!)
🌟 이메일 지원: recruit@60hz.io
2025년 12월 29일

Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
: PVlib 벡터라이제이션과 데이터 구조 단순화로 이룬 식스티헤르츠의 스케일업
📂서론 | 15만 개의 발전소, 하나의 계산
식스티헤르츠(60Hertz)는 전국 15만 개 이상의 중소규모 재생에너지 발전소로부터 데이터를 수집하고, 이를 기반으로 발전량을 실시간 예측하는 시스템을 운영합니다. 전력망의 안정성을 지키기 위해, 이 예측값은 빠르고 정확하게 계산되어야 합니다.
대부분의 사람들이 ‘발전량 예측’이라고 하면 머신러닝 모델의 정확도를 떠올립니다. 하지만 예측 대상의 규모가 15만 개 정도 수준이 되면 모델의 정확도 뿐만 아니라 “이 계산을 어떻게 제 시간에 끝낼 것인가”도 중요한 문제가 됩니다. 정확도가 아무리 좋다고 하더라도 문제의 규모가 커졌다고 제시간에 답이 나오지 않는 시스템은 전혀 실용적이지 않겠지요. 이런 측면에서 식스티헤르츠의 기존에 사용하던 시스템(이하 v1)은 하루 발전량 예측 계산에 1시간 이상이 소요되었지만, 다음의 철학을 통해 효율적인 스케일업을 이루어냈습니다.
💡 코드 병렬화보다 중요한 것은, 데이터를 한 번에 계산할 수 있는 단순한 구조로 만드는 것.
v1과 달리, 개선한 시스템(이하 v2)은 데이터를 벡터화하고 구조를 단순화하여 동일한 작업을 단 3~5분 만에 끝냅니다. 본 포스트는 어떻게 식스트헤르츠가 위 성과를 이루어낼 수 있었는지를 데이터 엔지니어링 관점에서 설명하고 있습니다.
📂문제 정의 | 15만 번의 루프, 15만 번의 병목
v1에서의 파이프라인은 Apache Airflow를 기반으로 동작합니다. Airflow란 복잡한 데이터 파이프라인을 스케줄링하고 모니터링하는 워크플로우 관리 플랫폼을 말하며, 이를 이용해 15만 개 발전소들의 발전량 예측 작업을 여러 Task로 나누어 관리해왔습니다.
각 Task는 발전소의 메타 데이터와 기상 데이터를 조합해 python의 태양광 발전 시뮬레이션 라이브러리인 PVlib의 ModelChain API를 반복 호출하는 방식을 통해 이루어집니다. ModelChain은 PVlib에서 제공하고 있는 고수준 API로, 태양광 발전 시스템의 물리적 특성(모듈, 인버터 등)과 기상 데이터를 기반으로 발전량을 계산하는 과정을 캡슐화한 객체입니다. 위 API는 단일 발전소에 대한 시뮬레이션을 쉽게 수행할 수 있도록 설계되었으며, 발전량 예측 과정은 다음과 같이 시각화할 수 있습니다.
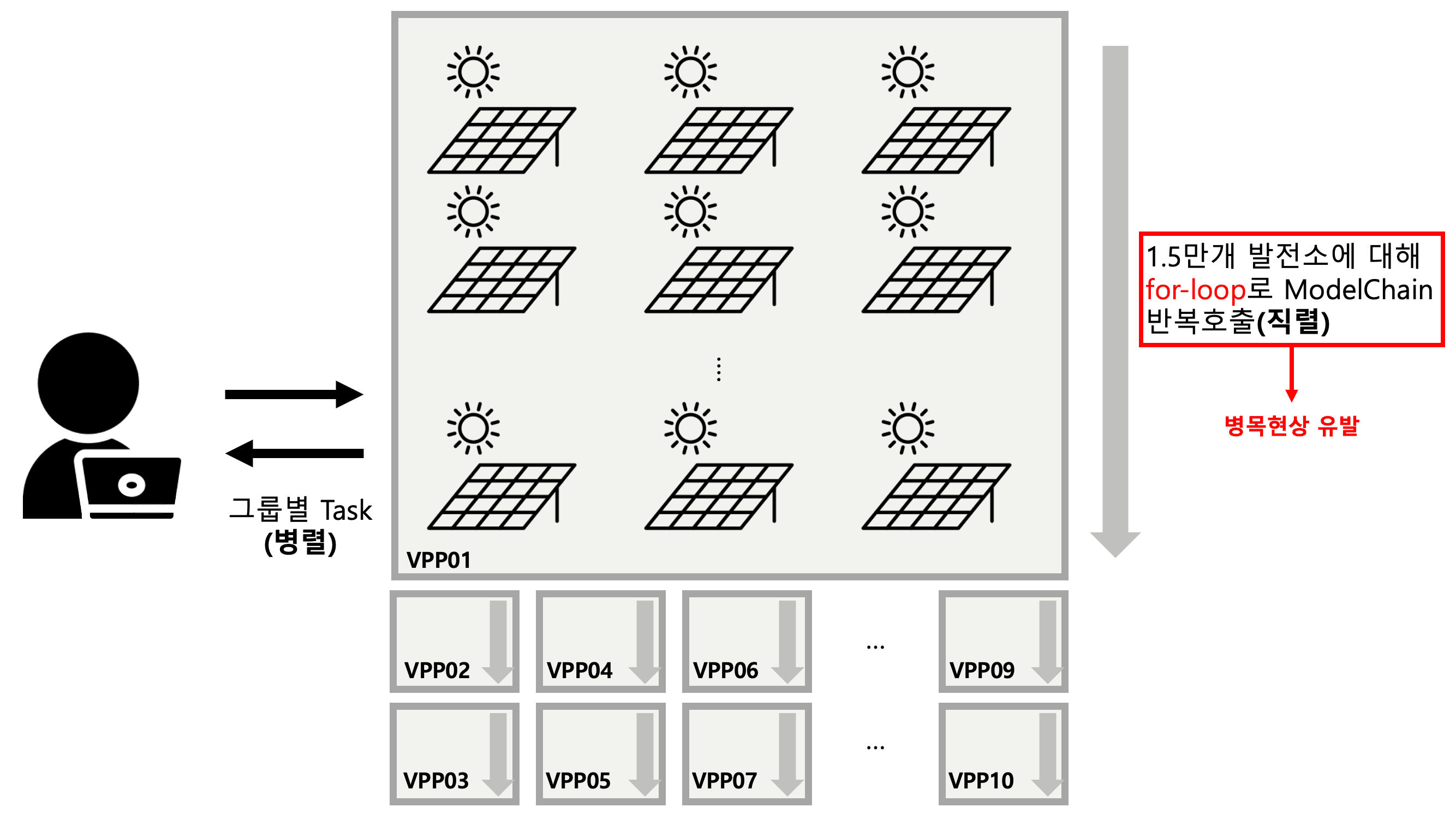
먼저 15만개의 발전소들을 10개의 그룹으로 만들어 각 그룹별로 Task가 병렬로 이루어지도록 합니다. 각 그룹 내에서는 1.5만개 발전소를 for-loop로 순회하며 직렬 형태로 ModelChain을 반복호출하게 됩니다. 즉, 병렬처럼 보여도 실상은 루프의 반복이 전체 시간을 지배했습니다. 위 아키텍쳐에서 병목 현상을 유발한 요인은 다음과 같이 정리할 수 있습니다.
계산 과정에서의 병목
데이터 관점에서 병목
데이터 I/O 관점에서 병목
이제 이 각각의 요인들이 어떻게 병목현상을 야기했는지, 그리고 어떻게 기술적으로 해결했는지 하나씩 살펴보도록 하겠습니다.
a. 계산 과정에서의 병목: 고수준 API인 ModelChain 을 변환하다
PVlib은 태양광 발전 시뮬레이션 표준 라이브러리로, 고수준 API(ModelChain)와 저수준 API 두 가지를 제공합니다. 각각의 API는 아래 표와 같이 정리할 수 있습니다.
고수준 API | 저수준 API | |
적용된 시스템 | v1 | v2 |
특징 | 태양광 발전 시스템 전체를 시뮬레이션 하는데 필요한 세부 단계들을 캡슐화하여 | 시뮬레이션의 각 세부 단계들을 구성하는 |
적합한 문제 | 단일 발전소 발전량 예측에 적합 | 대규모 발전소 발전량 예측에 적합 |
PVlib 내 | ModelChain | pvlib.irradiance |
장점 | 사용이 간편하며, 기본적인 시뮬레이션을 | 세밀한 제어가 가능하고, 대규모 데이터 |
단점 | 내부 로직이 숨겨져 있어 세부적인 제어가 | 사용자가 직접 시뮬레이션의 모든 단계를 |
고수준 API인 ModelChain은 단일 발전소 발전량 예측에 적합하지만, 15만개 발전소를 처리할 때는 15만 번의 객체 생성이 필요하여 지속적인 오버헤드를 유발합니다. 고수준 API 기반의 코드 예시는 다음과 같으며, python-level에서의 for loop을 중점적으로 사용하는 것을 확인할 수 있습니다.
results_v1 = [] for plant in plant_meta: mc = pvlib.modelchain.ModelChain(plant.system, plant.location) weather = weather_data_map[plant.id] mc.run_model(weather) results_v1.append(mc.results.ac)
반면 단순한 수학 함수로 구성된 저수준 API는 배열 전체를 한 번에 처리할 수 있어 대규모 데이터 처리에 적합합니다. 아래 코드를 비교해보시면 아시겠지만, python에서의 for-loop문이 완전히 사라진 것을 확인할 수 있습니다. python에서의 for-loop는 다음 단락에서 설명할 벡터화 연산의 이점을 이용할 수 없기 때문에 태생적으로 느릴 수 밖에 없습니다. 1.44억(=15 만개의 발전소 x 96 번)번의 연산이 저수준 API를 통해 벡터라이제이션됨으로써 C-level에서의 벡터화가 적용되어 빠르게 처리됨을 의미합니다.
tilt = plant_meta['tilt'].to_numpy() azimuth = plant_meta['azimuth'].to_numpy() dni = weather_data['dni'].reshape(150000, 96) ghi = weather_data['ghi'].reshape(150000, 96) tilt_b = tilt[:, np.newaxis] azimuth_b = azimuth[:, np.newaxis] total_irrad = pvlib.irradiance.get_total_irradiance( surface_tilt=tilt_b, surface_azimuth=azimuth_b, dni=dni, ghi=ghi ) final_ac_power = pvlib.pvsystem.sapm( effective_irradiance=total_irrad )
b. 데이터 관점에서의 병목: 벡터화를 통한 데이터 처리속도 향상
Pandas와 NumPy는 내부적으로 C언어 수준(이하 C-level)의 벡터 연산을 사용하여 빠른 계산 성능을 제공하며, groupby 역시 이에 최적화된 연산입니다. 하지만 v1에서는 발전소들을 묶는 과정에서 agg(list)를 사용해 데이터를 리스트화했습니다. 이로 인해 메모리상에 동일한 변수형이 연속적으로 배치되어야 하는 NumPy 배열의 구조적 장점이 깨지게 되었습니다. 그 결과 배열 내 값들이 불가피하게 object 타입으로 변환되면서 벡터화의 이 점을 완전히 잃게 되었습니다.
데이터가 벡터화로 구성이 되면 다음의 이유로 성능이 매우 빨라지게 됩니다.
먼저 데이터 형식이 동일하면, SIMD(Single Instruction, Multiple Data) 기술을 활용하여 CPU가 단 한 번의 명령어로 여러 데이터(레지스터 단위)를 동시에 처리하여 물리적인 연산 속도를 획기적으로 높입니다.
또한, Python 인터프리터는 동적 타이핑 언어 특성상, 반복문을 돌 때마다 변수의 타입을 확인하고 적절한 연산 함수를 찾는 과정인 Dispatching을 거칩니다. 반면, 벡터화된 NumPy 배열은 생성 시점에서 동일한 변수형이 보장이 되기 대문에 연산을 시작하기 전에 한 번만 타입을 검사하며, 이후에는 별도의 확인작업 없이 기계어 레벨에서 값을 밀어넣기 때문에 오버헤드가 0에 수렴합니다.
마지막으로 데이터가 메모리에 연속적으로 배치되기 때문에 v1처럼 주소(Pointer)를 따라 여기저기 메모리를 찾아다는 비용인 Dereferencing cost가 줄어들고, CPU 캐시 적중률이 극대화되며, 컴파일러가 자동으로 병렬화 최적화를 수행할 수 있습니다.
다음은 v1에서 사용한 예제 코드입니다.
# v1: C-level 연산을 포기하게 만드는 코드 grouped = df.groupby('plant_id')['ghi'].agg(list) print(grouped.dtype) # dtype('O') → object 타입
C-level에서의 연산은 데이터가 동일한 타입의 데이터가 연속된 메모리 블록에 저장되어 있을 때 가능합니다. 예를 들어, int64 로 구성된 배열은 실제값들이 빈틈없이 붙어있는 형태이며, 첫 번째 값의 주소만 알면 “여기서 부터 1000개의 값을 더해라”와 같은 명령을 단 한 번의 CPU 명령어로 처리할 수 있습니다.
하지만 object 타입으로 구성된 배열은 데이터가 아닌 데이터의 주소를 저장하게 됩니다. 실제 데이터는 메모리 여기저기에 흩어진 상태이며, 각 데이터의 타입도 제각각일 수 있습니다. 이렇게 되면 C-level 연산이 어려워져 속도가 느린 Python 인터프리터가 개입하게 되고, 이로 인해 비효율적인 연산 방식을 수행하게 됩니다.
v1의 경험이 남긴 교훈은 단순했습니다.
복잡한 병렬 처리로 비효율적인 구조를 보완하려 하지 말라. 데이터를 단순하게 만들어라.
이를 기반으로 새로 개선한 v2의 철학은 세 가지였습니다.
루프 제거: Python for 루프를 없앤다.
벡터화: NumPy 브로드캐스팅을 활용한다.
구조 단순화: 중첩 list 대신 2D long-form 구조 사용.
v1이 “15만 개 발전소 객체”를 다뤘다면, v2는 “15만 개의 발전소 정보가 동일한 형태로 줄지어 저장된 tilt, azimuth 배열”을 다룹니다. 데이터 중심의 설계로 전환하면서 코드 구조가 근본적으로 달라지게 된 것입니다.
c. 데이터 I/O 관점에서의 병목: CPU보다 느린 건 데이터였다
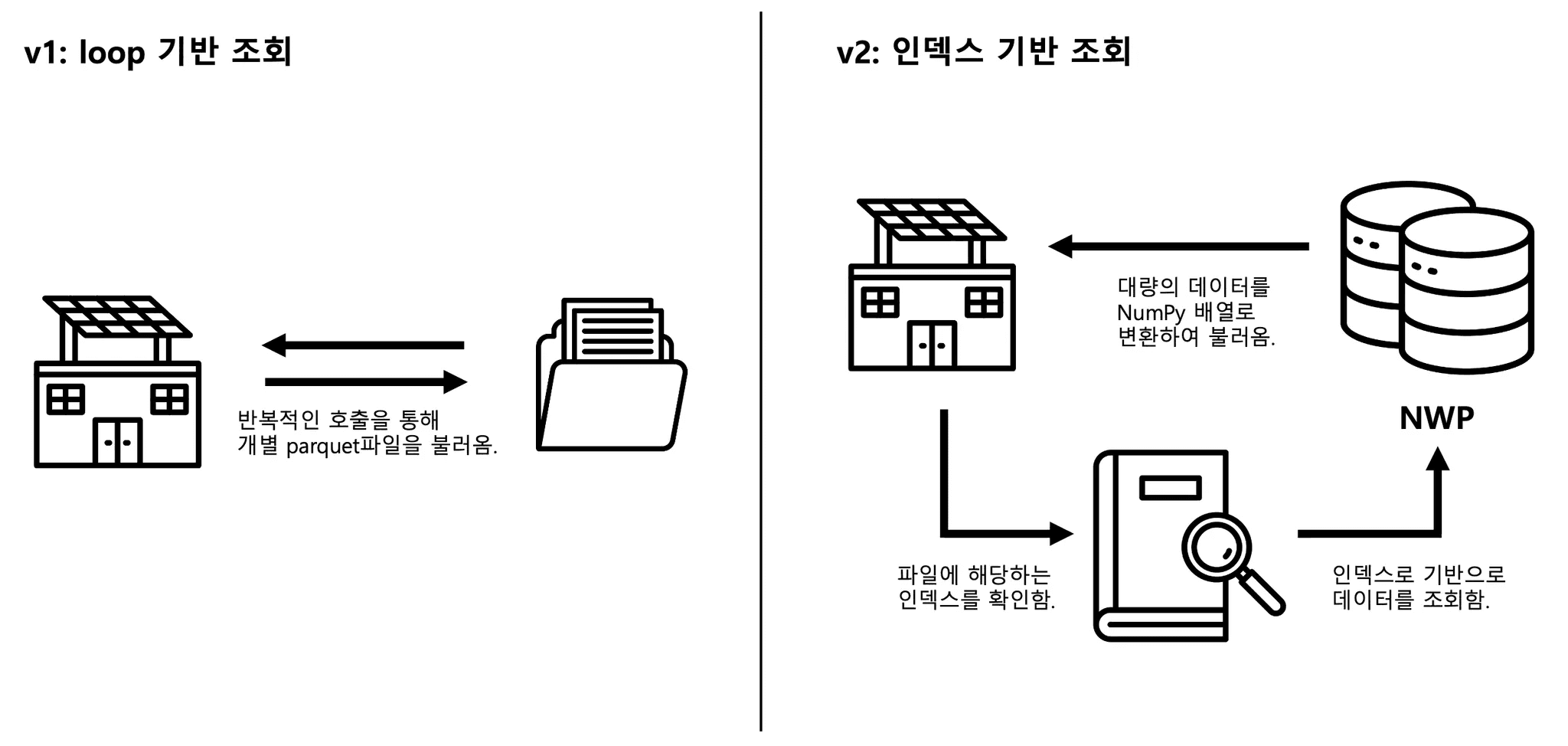
저수준 API를 통해 엄청난 속도의 발전을 이루었지만, 데이터 I/O에서의 문제가 남아있었습니다. 기존 v1 방식은 각 발전소 루프마다 필요한 기상예보데이터(NWP; Numerical Weather Prediction)를 개별 Parquet 파일에서 읽어왔습니다. 15만 개의 발전소가 10개의 Task로 나뉘어져 있어도, 각 Task 내에서는 1.5만 번의 파일 접근을 시도하여, 엄청난 I/O 병목을 유발하였습니다. 쉽게 설명하자면 택배로 보낼 물품 1.5만개를 한 대의 오토바이 퀵서비스로 반복적으로 보내고 받는 것과 다르지 않습니다. v2방식은 1) 인덱스 기반 조회와 2) 대량 데이터 전송(예: fetch_df_all()) 방식을 통해 택배차 한 대가 1000개의 택배를 한꺼번에 운송하는 방식과 비슷하게 문제를 해결했습니다.
먼저 모든 NWP 기상 데이터를 Oracle DB에 저장한 뒤, 15만 개 발전소의 위치 인덱스를 활용해 단일 SQL 쿼리에서 필요한 데이터를 한 번에 조회할 수 있도록 구조를 개선했습니다. 이를 통해 쿼리 단위를 통합해 네트워크 왕복 횟수를 최소화하고 I/O 과정에서의 효율을 크게 높였습니다.
또한, execute() 나 executemany() 등의 대용량 데이터 I/O에 적합하지 않은 표준 Python DB-API 방식 대신, Apache Arrow 기반의 python-oracledb DataFrame API를 사용했습니다. 이 방식은 DB에서 읽어온 대량의 데이터를 즉시 NumPy 배열로 변환하여, Python 객체 생성 오버헤드를 건너뛰고 제로카피에 가까운 메모리 효율을 달성합니다. 위 과정을 시각화하면 다음과 같습니다.
📂숫자로 증명된 구조의 힘
위의 세 병목 현상을 해결하여 v2방식은 데이터 로딩 속도만 수십 배 향상시켰고, 이는 전체 파이프라인 처리 시간 단축에 결정적으로 기여했습니다. 데이터 처리 방식을 v1에서 v2로 바꾸면서, 다음의 성능을 달성했습니다.
구분 | 방식 | 처리 시간 | 코드 라인 수 |
|---|---|---|---|
v1 | 발전소별 Python for-loop | 1시간 이상 | ~1200 |
v2 | 벡터 연산에 최적화된 데이터 구조 | 3분 내외 | ~400 |
v2는 24 코어를 모두 활용하며 3분 만에 계산을 완료함으로써 약 20배의 성능 향상을 달성했습니다. 하지만 여기서 더 주목해야 하는 것은 코드 라인의 수입니다. 복잡한 병렬처리, 예외 처리, 데이터 파편화로 가득했던 1,200개 라인의 코드가, 데이터 구조를 단순화하자 400개 라인의 명료한 벡터 연산 코드로 바뀌었습니다. 성능과 유지보수성, 두 마리 토끼를 모두 잡은 것 입니다.
📂이런 문제를 풀고 싶으시다면..
현장에서는 서비스가 어떻게 돌아가는지 뿐만 아니라 얼마나 잘 돌아가는지도 중요합니다. 그리고 상품화의 대상 및 문제 공간이 확대가 되면서 폭넓은 통찰 또한 필요합니다. 이러한 흐름 속에서 식스티헤르츠는,
단순한 데이터 수집이나 ML 모델을 학습시키는 것이 아닌, 문제의 본질을 이해하는 엔지니어를 원합니다.
15만 개의 수준의 거대한 데이터를 다룰 때 어떤 방식이 더 빠르고 효율적인지, 그 근본적인 원리를 이해하고 최적의 구조를 선택할 수 있는 분을 찾습니다.
단순히 데이터를 불러오는 것에 그치지 않고, 어떻게 하면 불필요한 네트워크 왕복 횟수를 최소화하여 전체 시스템의 속도를 높일 수 있을지 치열하게 고민하는 분을 원합니다.
여러 작업을 동시에 처리하는 방식과 거대한 데이터를 한 번에 계산하는 방식의 차이를 명확히 이해하고, 상황에 맞게 적절한 해결책을 제시할 수 있는 분과 함께하고 싶습니다.
우리는 코드가 '돌아가는 것'에 만족하지 않고, '왜 이렇게 돌아가야만 하는지', 그리고 ‘현재보다 더 효율적인 방법은 없는지’를 끊임없이 질문하는 엔지니어와 함께 스케일업의 한계를 넘고 싶습니다.
계산 최적화는 왜 중요할까요?
빠른 계산은 곧 효율적인 서버 운영을 의미하고, 효율적인 서버 운영은 에너지 절약으로 이어집니다. 1시간 걸리던 작업을 3분으로 줄이면, 그 차이인 57분만큼의 서버 리소스를 아낄 수 있습니다. 이것이 바로 고도화된 IT 기술과 정교한 데이터 아키텍처가 곧 탄소 효율로 이어지는 방식입니다.
식스티헤르츠는 '데이터로 에너지를 절약하는 회사'입니다. 이 거대하고 의미 있는 계산에 동참하고 싶다면, 지금 바로 식스티헤르츠의 문을 두드려 주시기 바랍니다.

——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2 (방금 읽은 글이에요)
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 12월 10일

Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
: 온프레미스 대규모 데이터 처리 아키텍처 구축기
저희 팀은 최근 전국 15만 개소 이상의 중소규모 재생에너지 발전소로부터 실시간으로 데이터를 수집하고, 이를 기반으로 발전량을 예측하고 모니터링하는 시스템을 온프레미스(On-premises) 환경에 성공적으로 구축했습니다. 클라우드 환경이 대세인 요즘, 고객사의 보안 정책과 데이터 소유권 문제로 인해 온프레미스 환경에 대규모 시스템을 설계하는 것은 저희에게도 큰 과제였습니다.
해결해야 할 과제들
프로젝트의 목표는 안정성과 확장성 두 가지로 압축되었습니다.
안정적인 데이터 수집
15만 개의 RTU(Remote Terminal Unit)는 LoRa, NB-IoT, HTTPS 등 서로 다른 통신망과 프로토콜을 사용합니다. 이를 단일 시스템으로 통합하여 데이터 유실 없이 수집해야 했습니다.
실시간 처리와 스케일 아웃
수집된 데이터는 즉시 처리되어야 하며, 향후 발전소 증가에 유연하게 대응할 수 있도록 모든 컴포넌트는 수평 확장(Scale-out)이 가능한 구조로 설계되어야 했습니다.
복합 분석 기능
단순 수집을 넘어, 외부 기상 데이터와 결합한 발전량 예측 및 실측치 비교를 통한 이상 감지 기능이 요구되었습니다.
보안 및 고가용성(HA)
외부 공격 방어는 물론, 일부 서버 장애 시에도 서비스 연속성을 보장하는 고가용성 아키텍처가 필수였습니다.
기술 스택 선정 - 왜 이 기술들을 선택했을까?
리액티브 스택을 선택한 이유
대규모 IoT 데이터 처리를 앞두고 가장 먼저 고민한 것은 동시성 처리 방식이었습니다. 전통적인 서블릿 기반의 Spring MVC도 충분히 검증된 기술이지만, 15만 개소에서 동시에 쏟아지는 연결을 처리하기에는 스레드 모델의 한계가 명확해 보였습니다.
그래서 저희는 Spring WebFlux를 선택했습니다. 비동기-논블로킹(Asynchronous Non-blocking) 방식으로 동작하는 WebFlux는 적은 수의 스레드로도 대량의 동시 연결을 처리할 수 있었습니다.

WebFlux를 선택한 결정적인 이유는 세 가지였습니다.
이벤트 루프 방식으로 수만 개의 연결을 동시에 처리할 수 있는 높은 동시성.
Reactor의 Flux/Mono를 통해 데이터 생산자와 소비자 간 속도 차이를 자동으로 조절하는 백프레셔(Backpressure) 지원.
스레드 기반 모델보다 더 적은 리소스로 동작하는 메모리 효율성이었습니다.
Kafka를 통한 이벤트 처리
Apache Kafka를 도입한 것은 이번 프로젝트에서 가장 중요한 아키텍처 결정 중 하나였습니다. 15만 개소에서 동시에 쏟아지는 데이터를 안정적으로 받아내기 위해 Kafka를 선택했습니다.
Kafka는 단순한 메시지 큐 이상의 역할을 담당했습니다. 순간적으로 폭증하는 트래픽을 버퍼링하고, 수집 시스템과 처리 시스템을 분리(Decoupling)함으로써 각 컴포넌트가 독립적으로 확장되고 장애에 대응할 수 있게 해줬습니다.
또한, 토픽 설계는 신중하게 진행했습니다. IoT Platform A, B, C, HTTPS 등 프로토콜별로 토픽을 분리해 각 채널의 특성에 맞게 독립적으로 관리할 수 있도록 했습니다. 각 토픽은 6개의 파티션으로 구성하여 병렬 처리 능력을 확보했고, 복제 계수를 3으로 설정하여 브로커 장애 시에도 데이터를 안전하게 보호했습니다. 메시지는 7일간 보관되도록 설정하여, 만약의 장애 상황에서도 충분한 복구 시간을 확보했습니다.
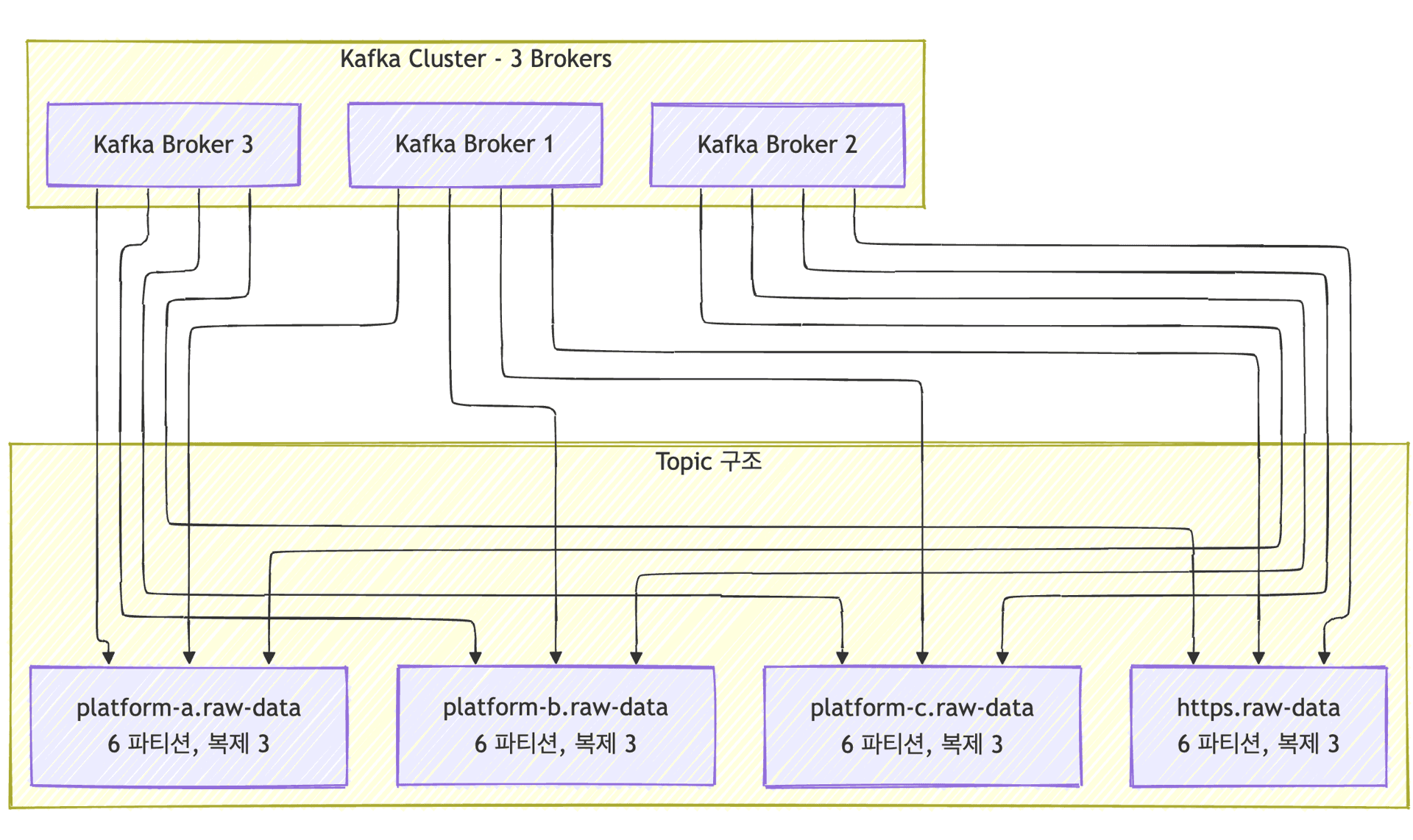
아키텍처 설계 - 데이터는 어떻게 흐르는가?
기술 스택을 정했으니, 이제 이것들을 어떻게 조합할 것인지 고민할 차례였습니다. 저희는 데이터의 흐름을 따라 시스템을 크게 4개 영역으로 나누어 설계했습니다.
1. 데이터 수집 영역
전국 각지에 흩어진 발전소의 RTU 장비에서 보낸 데이터가 시스템으로 유입되는 진입점입니다. 방화벽과 L4 스위치를 거쳐 수집 서버로 전달된 데이터는, 여기서 프로토콜별로 정제되어 Kafka로 발행됩니다.
Data Collector
Spring WebFlux 기반의 비동기 서버로, 다양한 IoT 프로토콜을 표준화된 내부 포맷으로 변환합니다.
reactor-kafka를 사용하여 논블로킹 메시지 발행을 구현했으며, Reactor의 백프레셔 기능을 통해 Kafka 클러스터로 가는 부하를 조절합니다. 컨테이너 기반으로 설계되어 트래픽 증가 시 즉각적인 확장이 가능합니다.

2계층 로드밸런싱: L4 스위치와 Nginx, Docker
클라우드의 관리형 로드밸런서가 없는 온프레미스 환경에서 고가용성과 확장성을 확보하기 위해, 하드웨어 L4 스위치와 소프트웨어 로드밸런서를 계층화하여 유연한 트래픽 분산을 구현했습니다. 외부에서 들어오는 트래픽은 먼저 L4 스위치가 여러 대의 서버로 분산하고, 각 서버 내부에서는 Nginx가 Docker 컨테이너로 패키징된 수집 서버 인스턴스들에게 요청을 분배합니다.
하드웨어 스위치가 네트워크 레벨의 빠른 분산과 헬스체크를 담당하고, Nginx가 애플리케이션 레벨의 세밀한 라우팅을 담당하는 역할 분리가 핵심입니다.
Nginx는 Least Connections 방식으로 현재 활성 연결 수가 가장 적은 인스턴스에 요청을 전달하며, Passive Health Check를 통해 실패한 인스턴스를 자동으로 제외합니다.
upstream collector_api_server1 { least_conn; server collector-api-1:8081 max_fails=3 fail_timeout=30s; server collector-api-2:8081 max_fails=3 fail_timeout
Nginx 설정은 코드로 관리되어 버전 관리가 가능하고, 컨테이너 스케일 아웃 시 설정만 변경하면 됩니다. 이 패턴은 WEB/WAS 서버에도 동일하게 적용했습니다.
2. 이벤트 허브 영역
Kafka 토픽 설계는 단순해 보이지만, 실제로는 많은 고민이 필요한 부분입니다. 저희는 프로토콜별로 토픽을 분리하여 각 채널이 서로 영향을 주지 않도록 격리성을 확보하면서도, 파티셔닝을 통해 확장성도 함께 확보했습니다.
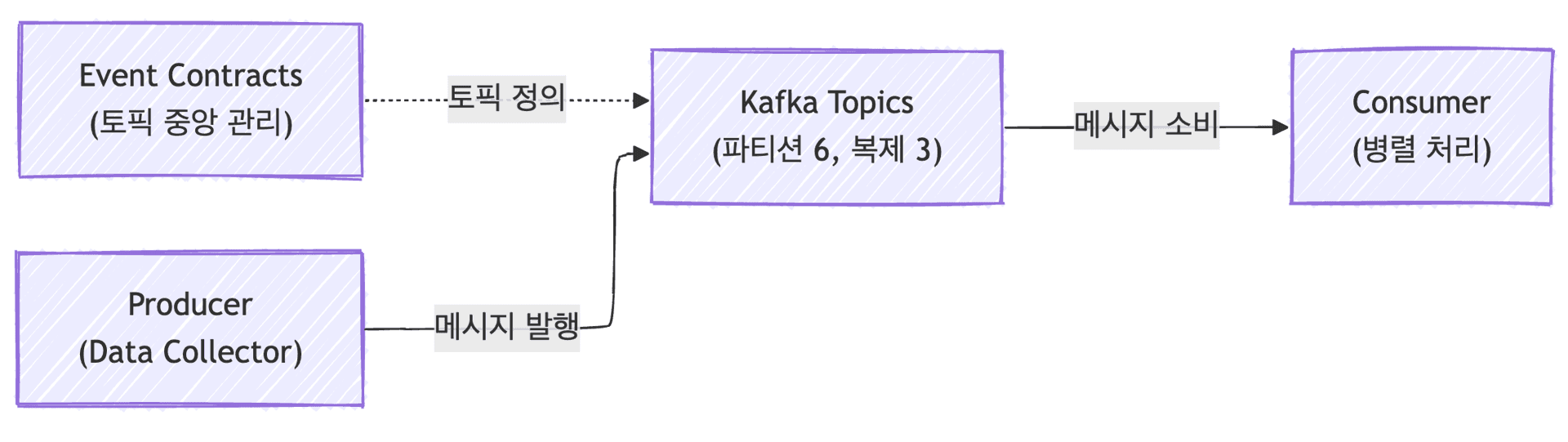
토픽 네이밍은 일관된 컨벤션을 따랐습니다. {namespace}.collector.{platform}.raw-data 형태로 명명하고, Event Contracts 모듈에서 모든 토픽 이름을 상수로 중앙 관리했습니다.
파티셔닝 전략도 중요했습니다. 각 토픽을 6개 파티션으로 나누어 컨슈머가 병렬로 처리할 수 있도록 했습니다. 파티션 리밸런싱 기능 덕분에 컨슈머가 추가되거나 제거될 때도 부하가 자동으로 재분배됩니다.
3. 데이터 중계 및 저장 영역
Kafka에 쌓인 데이터를 이제 안전하게 내부망의 데이터베이스로 옮겨야 합니다. 보안을 위해 DMZ에 중계 서버를 두고, 여기서 Kafka 메시지를 소비해 내부망 DB에 저장하는 구조로 설계했습니다.

컨슈머 처리 로직
컨슈머 모듈은 Kafka 메시지를 소비하여 DB에 저장하는 역할을 합니다. 가장 먼저 집중한 부분은 배치 처리 최적화였습니다. 메시지를 개별적으로 처리하지 않고 배치(Batch) 단위로 묶어서 DB에 저장하도록 했는데, 최대 1,000개 메시지를 한 번에 가져오며 최소 1MB 데이터가 모이거나 3초가 경과하면 배치 처리를 수행합니다. 이 방식으로 DB Insert 성능을 크게 향상시킬 수 있었습니다.
처리량을 극대화하기 위해 컨슈머 그룹도 적극 활용했습니다. 6개의 파티션을 6개의 컨슈머가 병렬로 소비하며, 각 컨슈머는 독립적으로 메시지를 처리합니다.
안정성을 위한 재시도 및 에러 핸들링도 중요했습니다. 일시적인 오류 시에는 1초 간격으로 최대 3번 재시도하며, 배치 저장 실패 시에는 개별 저장으로 fallback하여 가능한 많은 데이터를 보존하도록 했습니다. 그래도 실패하는 데이터는 별도의 오류 테이블에 저장하여 추후 분석할 수 있도록 했습니다.
4. 발전량 예측 및 분석 영역
단순히 데이터를 쌓는 것만으로는 가치를 만들기 어렵습니다. 분석 예측 서버는 수집된 데이터를 분석하고 예측하는 역할을 합니다.
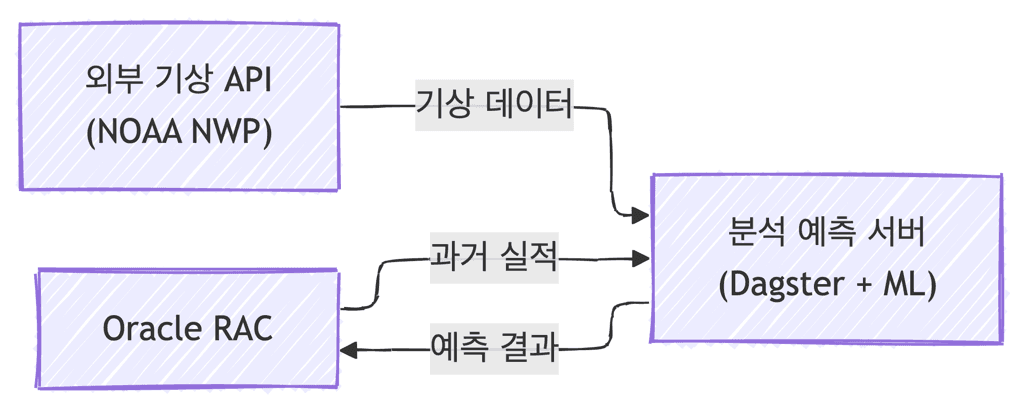
분석 예측 서버는 Dagster 기반 워크플로우 오케스트레이션을 사용합니다. Dagster를 활용해 데이터 파이프라인의 스케줄링과 실행을 관리하며, 데이터 수집, 전처리, 예측 실행을 하나의 워크플로우로 통합했습니다. 파이프라인 실행 이력과 의존성도 체계적으로 관리했습니다.
예측 정확도를 높이기 위해서는 외부 데이터 연동이 필수적이었습니다. Python 분석 파이프라인이 NOAA NWP(수치예보모델)를 통해 기상 예보 데이터를 수집하며, 태양광 발전에 영향을 미치는 기상 요소를 확보했습니다. 발전량 예측 모델은 과거 발전 실적 데이터와 기상 데이터를 결합하여 미래 발전량을 예측하고, 그 결과는 데이터베이스에 저장되어 분석 및 리포팅에 활용됩니다.
5. 웹 서비스 제공 영역
사용자들이 발전소 상태를 모니터링하고 시스템을 제어하는 웹 서비스 영역입니다.

웹 서비스는 전형적인 3-Tier 아키텍처로 구성했습니다. 가장 앞단의 WEB 계층에서는 정적 리소스 서빙과 SSL/TLS 터미네이션을 담당하며, L4 스위치를 통해 2대의 서버로 로드 밸런싱합니다. 들어온 요청은 WAS 서버로 프록시됩니다.
WAS 계층은 3대의 Application Server로 구성되어 고가용성을 확보했습니다. 여기서 동작하는 Business API Service는 Spring Boot 기반의 RESTful API 서버로, 모니터링 서비스의 핵심 비즈니스 로직을 처리합니다. 무중단 서비스는 필수 요구사항이었습니다. Oracle RAC Active-Active 클러스터로 DB를 이중화하고, 모든 계층에서 최소 2대 이상의 서버를 운영하며 L4 로드 밸런싱을 구성했습니다. Docker 기반 구성 덕분에 장애 발생 시에도 빠르게 복구할 수 있습니다.
배치 계층은 Spring Batch를 활용해 정기적인 통계 집계와 리포트 생성 같은 대용량 데이터 처리 작업을 수행합니다.
수집 서버 클러스터 성능 검증: 12,000 TPS 달성
아키텍처 설계가 실제 대규모 트래픽 환경에서 유효한지 검증하기 위해 강도 높은 부하 테스트를 수행했습니다. 단순 산술 계산으로 접근하면 15만 개의 장비가 60초 동안 균등하게 데이터를 전송한다고 가정했을 때, 필요한 처리량은 약 2,500 TPS입니다.
150,000 Requests / 60 Seconds = 2,500 TPS
하지만 실제 환경에서는 장비들이 완벽하게 분산되지 않습니다. 많은 설비들이 동시에 데이터를 전송하는 트래픽 스파이크가 빈번하게 발생하기 때문입니다. 클라이언트 측에 지연 로직이 없다면 서버는 순간적으로 10,000 TPS 이상의 폭주 트래픽을 감당해야 할 수도 있습니다. 저희는 이러한 트래픽 서지(Surge)를 고려하여, 평균 대비 약 4~5배의 예비 용량을 확보하는 것을 목표로 삼았습니다.
Grafana k6를 이용한 부하 테스트 결과 단일 노드 기준 초당 3,000건의 수집 요청(3,000 TPS), 전체 클러스터 기준 초당 12,000건(12,000 TPS)의 수집 요청을 지연 없이 안정적으로 처리하는 것을 확인했습니다. Spring WebFlux의 Non-blocking 구조와 Kafka를 통한 트래픽 버퍼링, 그리고 컨슈머의 Batch Insert 전략이 유기적으로 동작하여, 이론적 피크치를 상회하는 부하 상황에서도 데이터 유실 없이 안정적인 처리가 가능함을 증명했습니다.
회고 - 우리가 배운 것들
비동기-논블로킹의 이점
Spring WebFlux를 실전에 적용하면서 대규모 IoT 환경에서 리액티브 프로그래밍의 장점을 확인할 수 있었습니다. 적은 리소스로 높은 처리량을 달성하는 것은 물론, 백프레셔 제어를 통해 시스템 전체의 안정성을 확보할 수 있었습니다.
Kafka는 단순한 메시지 큐가 아니다
Kafka를 도입하면서 이벤트 스트리밍 플랫폼의 진가를 알게 되었습니다. 단순히 메시지를 전달하는 것을 넘어, 시스템 간 결합도를 낮추고 장애 격리를 가능하게 하며, 데이터를 일정 기간 보관해 재처리를 가능하게 하는 등 아키텍처 전반의 안정성을 높이는 중요한 컴포넌트였습니다.
확장성은 처음부터 고려해야 한다
수평 확장이 가능한 구조로 설계한 덕분에, 트래픽이 증가해도 서버를 추가하는 것만으로 대응할 수 있었습니다. 컨테이너 기반 아키텍처와 Kafka의 파티셔닝 메커니즘이 이를 가능하게 했습니다.
온프레미스에서도 유연한 인프라 구성이 가능하다
클라우드 없이도 L4 스위치와 Nginx를 계층화하여 충분히 유연한 로드밸런싱을 구현할 수 있었습니다. 중요한 것은 각 계층의 역할을 명확히 분리하고, 설정을 코드로 관리하는 것이었습니다.
마무리하며
온프레미스 환경에서 15만 개소의 실시간 데이터를 처리하는 시스템을 구축하는 여정은 쉽지 않았습니다. 클라우드 매니지드 서비스가 제공하는 편리함 대신, 하드웨어 선정부터 네트워크 망 분리, 각 서버의 역할 정의와 이중화 구성까지 모든 단계를 저희 손으로 직접 결정하고 구축해야 했습니다.
하지만 그만큼 배운 것도 많았습니다. 대규모 트래픽을 안정적으로 처리하기 위한 Spring WebFlux와 Kafka의 활용, 그리고 Nginx와 Docker를 활용한 소프트웨어 로드밸런싱을 통해 유연한 아키텍처를 구성해 본 것은 저희 팀의 큰 자산으로 남게 되었습니다.
이 글이 온프레미스 환경에서 대규모 트래픽 처리를 고민하는 엔지니어분들에게 작은 도움이 되기를 바랍니다.

——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1 (방금 읽은 글이에요)
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 12월 3일

Tech
단일책임원칙(SRP)을 충족하는 React 개발
혹시 SOLID 원칙에 대해 들어보셨나요?
개발을 접하신 분이라면 자세히는 몰라도 한 번쯤 이름은 들어보셨을 거예요.
SOLID 원칙은 객체지향 설계에서 지켜야 할 다섯 가지 소프트웨어 개발 원칙(SRP, OCP, LSP, ISP, DIP)을 말합니다.
SRP (Single Responsibility Principle): 단일 책임 원칙
OCP (Open Closed Principle): 개방 폐쇄 원칙
LSP (Liskov Substitution Principle): 리스코프 치환 원칙
ISP (Interface Segregation Principle): 인터페이스 분리 원칙
DIP (Dependency Inversion Principle): 의존 역전 원칙
이런 원칙들을 지키면 좋은 객체지향 설계에 가까워질 수 있습니다.
그런데 프론트엔드 개발자, 특히 React를 사용하는 분들이라면 이런 생각이 들 수도 있습니다.
“객체지향 원칙을 함수 기반 React에 어떻게 적용하지?”
식스티헤르츠는 관리자 도구, 대시보드, 사용자 웹 서비스 등 다양한 영역에서 React를 활용하고 있습니다.
React는 빠르고 선언적인 개발을 가능하게 하지만, 동시에 SOLID 같은 설계 원칙을 놓치기 쉬운 환경이기도 합니다.특히 일정에 쫓기다 보면 "일단 되게 만들고 나중에 리팩토링하자"는 생각으로 컴포넌트 하나에 API 호출, 상태 관리, 비즈니스 로직, UI 렌더링을 모두 집어넣게 됩니다. 당장은 빠르게 느껴지지만, 시간이 지나면 그 '나중'은 오지 않고 코드는 점점 더 복잡해집니다. 결국 새로운 기능을 추가할 때마다 기존 코드를 건드리기 두려워지고, 수정 대신 코드를 추가하는 방식으로 문제를 회피하게 되죠.
사실 저는 주니어 개발자 시절부터 꽤 오랫동안 설계 원칙에 갇혀 있었습니다. 하나의 원칙을 프로젝트에 적용하면 그것을 엄격하게 지키려고만 했지, '왜 지켜야 하는가'에 대해서는 제대로 생각하지 못했어요. 그러다 보니 오히려 원칙을 지키는 게 불편해지고, 어느 순간부터는 원칙을 의도적으로 멀리하게 됐습니다. 코드를 작성하는 데 불편하고 시간도 오래 걸렸거든요. 막상 코드를 작성하고 나면 그렇게 마음에 들지도 않았어요.
하지만 원칙을 멀리한 채 개발하다 보니, 오히려 다시 원칙을 찾게 되는 상황들이 생겼습니다. 왜일까요? 개발 원칙에는 좋은 소프트웨어를 만들기 위한 개발 철학이 담겨있기 때문입니다. 나보다 먼저 이 길을 걸은 개발자들의 고민과 해결 방법들이 개발 원칙으로 만들어진 것이죠. 구체적인 지침 자체는 내 상황에 맞지 않을 수 있어도, 그 지침이 만들어지기까지의 철학은 어떤 소프트웨어 개발에도 유효할 수 있습니다. 한 발 물러서서 개발 원칙을 바라보니, 필요한 시점에 필요한 철학을 적절히 적용할 수 있게 되었습니다.이 글에서는 그런 문제의식에서 출발해, SOLID의 첫 번째 원칙인 SRP(단일 책임 원칙)를 React 코드에 어떻게 적용할 수 있는지 살펴보려 합니다
단일 책임 원칙의 철학
단일 책임 원칙(SRP)의 핵심은 간단합니다. "하나의 모듈(클래스, 함수, 컴포넌트)은 하나의 책임만 가져야 한다." 여기서 '책임'이란 '변경의 이유'를 의미합니다. 로버트 C. 마틴은 이를 "하나의 모듈은 하나의, 오직 하나의 액터(사용자)에 대해서만 책임져야 한다"고 표현했습니다.
왜 이게 중요할까요? 여러 책임이 하나의 모듈에 섞여 있으면, 한 가지를 수정할 때 다른 것까지 영향을 받게 됩니다. 책임이 명확하게 분리되어 있으면 변경의 파급 효과를 최소화할 수 있고, 코드를 이해하고 테스트하기도 훨씬 쉬워집니다.
실생활에서의 단일 책임 원칙
우리가 개발 과정을 설명할 때 자동차를 예시로 자주 사용합니다. 자동차는 각 책임 단위인 부품으로 잘 분리되어 있습니다. 에어컨이 고장나면 에어컨만 수리하면 되고, 브레이크가 고장나면 브레이크만 교체하면 됩니다. 각 부품에 문제가 생겼을 때 해당 부품만 손보면 되는 구조죠.
그렇다면 단일 책임 원칙을 지키지 못해 에어컨, 브레이크, 엔진이 하나의 통합 모듈로 결합되어 있다면 어떻게 될까요? 에어컨 필터만 교체하려 해도 전체 모듈을 분해해야 합니다. 작업 중 실수로 브레이크 라인을 건드려 브레이크액이 샐 수도 있고, 엔진 배선을 잘못 만져 시동이 걸리지 않을 수도 있습니다. 단순한 에어컨 필터 교체가 브레이크나 엔진 같은 핵심 기능에 문제를 일으킬 위험이 생기는 거죠. 당연히 수리 시간도 길어지고, 비용도 훨씬 비싸집니다.
여기에 에어컨 부품이 개선되어 새로운 에어컨 부품이 개발되었다고 해볼까요? 별도 모듈로 사용하고 있다면 브레이크와 엔진은 기존 부품을 그대로 사용하면 되는데, 모듈이 결합되어 있기 때문에 새 에어컨 부품을 사용하기 위해서는 새 에어컨, 브레이크, 엔진이 결합된 새로운 모듈을 만들어 사용해야 합니다. 기존 모듈은 더이상 사용할 수 없어지겠죠.
소프트웨어 개발도 마찬가지입니다. 단일 책임 원칙을 지키지 못한다면 동일한 문제가 발생합니다.
작은 수정에도 큰 비용이 발생합니다 (유지보수 비용 증가)
코드 수정 중 예상치 못한 사이드 이펙트가 발생합니다
수정이 두려워 코드를 수정하기보다는 코드를 추가하게 되고, 코드가 점점 복잡해집니다
코드 재사용이 어려워집니다. (여러 책임이 얽혀있기 때문에)
결국 단일 책임 원칙은 유지보수 비용을 줄이면서, 자연스럽게 재사용성도 높여주는 중요한 원칙입니다. React에서는 컴포넌트 재사용 빈도가 높기 때문에 단일 책임 원칙을 지키면 재사용성 측면에서 큰 이점을 만들어낼 수 있습니다.
React 개발에서 SOLID 원칙을 놓치기 쉬운 이유
식스티헤르츠는 React를 주로 관리자 도구와 대시보드, 그리고 사용자 대면 웹 서비스 개발에 사용하고 있습니다. 개발 업무 중 웹 개발이 차지하는 비중이 많기 때문에 javascript를 적극적으로 활용하게 되고, 속도와 유지보수성을 모두 살리기 위해 선언적 개발을 가능하게 만들어주는 React를 주로 활용하고 있습니다. 여러 상황에서 React는 훌륭한 선택이지만, 동시에 SOLID 원칙 같은 설계 원칙을 간과하게 만드는 특성도 가지고 있습니다.
JavaScript와 React는 강력한 자유도를 제공합니다. 함수 안에서 무엇이든 할 수 있으며, 컴포넌트 하나에 로직과 UI를 모두 담을 수 있습니다. 이런 자유로움 덕분에 빠르게 기능을 구현할 수 있지만, 역설적으로 '잘못된 설계'도 쉽게 만들어집니다. Java나 C# 같은 언어에서는 클래스 구조와 타입 시스템이 어느 정도 설계를 강제하지만, React에서는 모든 것이 '함수'이기 때문에 책임의 경계가 흐려지기 쉽습니다.
특히 일정에 쫓기다 보면 "일단 되게 만들고 나중에 리팩토링하자"는 생각으로 컴포넌트 하나에 API 호출, 상태 관리, 비즈니스 로직, UI 렌더링을 모두 집어넣게 됩니다. 당장은 빠르게 느껴지지만, 시간이 지나면 그 '나중'은 오지 않고 코드는 점점 더 복잡해집니다. 결국 새로운 기능을 추가할 때마다 기존 코드를 건드리기 두려워지고, 수정 대신 코드를 추가하는 방식으로 문제를 회피하게 되죠.
React 개발에서 '책임'이란?
React 개발은 결국 함수 개발이라고 할 수 있습니다. 비즈니스 로직은 말할 것도 없이 함수로 개발하고 UI조차도 함수로 개발하는 특징을 갖고 있죠. 그리고 함수가 하는 일이 곧 책임입니다. 그래서 React에서의 책임은 ‘함수가 어떤 비즈니스 로직을 수행하는가' 뿐만 아니라 ‘어떤 UI를 어떻게 그려내는가’를 포함한다고 할 수 있습니다.
React에서 단일 책임 원칙 지키기
1. 비즈니스 로직과 UI 분리
가장 먼저 책임을 분리할 수 있는 지점은 비즈니스 로직과 UI를 분리하는 것입니다. React는 비즈니스 로직과 UI를 모두 함수로 표현하기에 이를 합쳐서 사용하게 되는 경우가 많습니다.
// 책임이 섞여있는 컴포넌트 function MyProfile() { const [myInfo, setMyInfo] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/me') .then(res => res.json()) .then(data => setMyInfo(data)) .finally(() => setLoading(false)); }, []); if (loading) return <Spinner />; return ( <div className="profile"> <img src={myInfo?.avatar} /> <h1>{myInfo?.name}</h1> <p>{myInfo?.email}</p> </div> ); }
간단하게 예를 들어 위와 같은 `MyProfile` 컴포넌트가 있다고 해보겠습니다. 언뜻 보기에는 내 정보를 화면에 보여주는 단일 책임 컴포넌트처럼 오해하기 쉽습니다. 하지만 이 컴포넌트는 '내 정보를 호출하는 로직'과 '프로필 UI 렌더링 로직' 두 가지가 강하게 결합되어 있습니다.
이렇게 되면 어떤 문제가 발생할까요?
가장 먼저 발생하는 문제는 재사용이 어려워진다는 것입니다. 동일한 UI를 사용하는 화면이 있는데 내 정보가 아니라 다른 사용자의 프로필을 보여줘야 한다고 가정해볼까요? 현재 `MyProfile` 은 내 정보를 화면에 그려주는 역할을 하기 때문에 이 코드를 재사용할 수 없습니다. 그럼 아래와 같은 컴포넌트를 새로 만들어야 할 겁니다.
function UserProfile({ userId }) { const [user, setUser] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch(`/api/user/${userId}`) .then(res => res.json()) .then(data => setUser(data)) .finally(() => setLoading(false)); }, [userId]); if (loading) return <Spinner />; return ( <div className="profile"> <img src={user?.avatar} /> <h1>{user?.name}</h1> <p>{user?.email}</p> </div> ); }
컴포넌트를 분석해보니 '유저 정보를 호출하는 로직'과 '프로필 UI 렌더링 로직'이 결합되어 있네요. 뭔가 이상함을 느끼셨나요? 같은 '프로필 UI 렌더링' 책임이 두 컴포넌트에 중복되어 존재합니다. 단지 두 개가 아닙니다. 앞으로 동일한 UI를 사용할 때마다 매번 새로운 컴포넌트를 만들어야 하고, 앞으로 몇 개가 더 생성될지 모릅니다.
이는 결국 유지보수의 문제로 이어집니다. "프로필 UI에서 email이 없으면 '-'를 보여주세요" 같은 간단한 수정에도 수많은 컴포넌트들을 일일이 찾아서 수정해야 하고, 누락되는 부분이 생길 가능성이 큽니다.
반대로 다른 컴포넌트에서 유저정보를 가져다 사용하는 것 처럼 비즈니스 로직이 재사용되는 경우에도 매번 동일한 코드를 작성해줘야 하겠죠.
이처럼 비즈니스 로직과 UI의 결합은 언뜻 보면 자연스러워 보여도 실제로는 서로 다른 책임의 결합으로 이루어져 있음을 이해해야 합니다.
그럼 어떻게 수정하면 좋을까요? 처음 이야기했던 대로 비즈니스 로직과 UI를 분리하면 됩니다. 비즈니스 로직은 Custom Hook으로, UI는 별도 컴포넌트로 분리해보겠습니다.
// 내 정보를 가져오는 책임 담당 function useMyInfo() { const [myInfo, setMyInfo] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/me') .then(res => res.json()) .then(data => setMyInfo(data)) .finally(() => setLoading(false)); }, []); return { myInfo, loading }; } // 유저 정보를 가져오는 책임 담당 function useUser(userId) { const [user, setUser] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { if (!userId) return; setLoading(true); fetch(`/api/user/${userId}`) .then(res => res.json()) .then(data => setUser(data)) .finally(() => setLoading(false)); }, [userId]); return { user, loading }; } // UI를 렌더링하는 책임 담당 function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile"> <img src={avatar} alt={name} /> <h1>{name}</h1> <p>{email || "-"}</p> // 수정사항 반영 </div> ); }
이제 책임을 나누었으니 완성된 함수를 사용해보겠습니다.
function MyProfile(){ const { myInfo, loading } = useMyInfo(); return ( <ProfileCard loading={loading} avatar={myInfo?.avatar} name={myInfo?.name} email={myInfo?.email} /> ) } function UserProfile({ userId }){ const { user, loading } = useUser(userId); return ( <ProfileCard loading={loading} avatar={user?.avatar} name={user?.name} email={user?.email} /> ) } // 다른곳에서 비즈니스 로직 재사용 function Header(){ const { myInfo, loading } = useMyInfo(); return <UserSummary userLevel={myInfo?.level} name={myInfo?.name} /> }
어떠신가요? 이제 ProfileCard는 UI의 변경에만 대응하면 되는 단일 책임을 가진 컴포넌트가 되었습니다. 이렇게 비즈니스 로직과 UI를 분리하게 되면 여러 가지 장점이 따라옵니다.
재사용성 향상
ProfileCard는 어디서든 사용 가능합니다.
새로운 페이지에서 프로필을 보여줘야 한다면? ProfileCard 만 재사용하면 됩니다.
내 정보를 가져오는 비즈니스 로직이 필요하면 UseMyInfo 를 재사용하면 됩니다.
유지보수 용이
UseMyInfo, UseUser : "데이터를 어떻게 가져올 것인가"에 대한 책임
ProfileCard : "프로필을 어떻게 보여줄 것인가"에 대한 책임
MyProfile, UserProfile : "어떤 데이터를 어떤 UI로 조합할 것인가"에 대한 책임
각 모듈이 하나의 명확한 책임만 가지고 있어서, 변경의 이유도 하나씩만 가집니다. 유지보수 시점에 어떤 책임을 수정할지 확인하고 수정하면 됩니다.
병렬 개발이 가능하다
API 서버 개발이 늦어지는 상황에서도 UI를 완성할 수 있고, 추후 비즈니스 로직 작성이 UI 컴포넌트를 수정하지 않습니다.
반대로 디자인이 늦어지는 상황에서도 비즈니스 로직을 먼저 작성할 수 있습니다.
각각의 책임을 쉽게 테스트할 수 있다.
// Hook 테스트 test('useMyInfo는 내 정보를 가져온다', async () => { const { result } = renderHook(() => useMyInfo()); await waitFor(() => { expect(result.current.myInfo).toBeDefined(); }); }); // UI 테스트 (혹은 스토리북 테스트) test('ProfileCard는 사용자 정보를 표시한다', () => { render(<ProfileCard avatar="/avatar.png" name="홍길동" email="hong@example.com" />); expect(screen.getByText('홍길동')).toBeInTheDocument(); });
2. UI 세분화
비즈니스 로직을 분리했다면, 이제 UI 자체도 더 작은 책임으로 나눌 수 있습니다. 앞서 만든 ProfileCard 를 다시 살펴볼까요?
function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile"> <img src={avatar} alt={name} /> <h1>{name}</h1> <p>{email || '-'}</p> </div> ); }
이 컴포넌트는 '프로필 카드를 렌더링한다'는 하나의 책임을 가진 것처럼 보입니다. 실제로 어떤 상황에서는 하나의 책임이 맞을 수 있습니다. 하지만 조금 더 들여다보면 상황에 따라 여러 UI 요소들이 섞여 있다고 할 수 있습니다.
아바타 이미지 표시
사용자 이름 표시
이메일 표시
전체 레이아웃 구성
만약 다음과 같은 요구사항이 생긴다면 어떨까요?
"댓글 섹션에서도 사용자 아바타와 이름을 보여주세요"
"헤더에 아바타만 동그랗게 표시해주세요"
"사용자 정보 편집 폼에서 이메일 입력란 스타일을 프로필과 동일하게 해주세요"
현재 구조에서는 이런 작은 UI 요소들을 재사용하기 어렵습니다. 책임을 분리한 순간 ProfileCard 에 이미 여러 책임들이 섞여있기 때문이죠. 그래서 ProfileCard 에서 코드를 복사해와서 사용하거나 새로 작성해야 할 겁니다. 이는 디자인팀도 Figma를 사용해 디자인 요소를 컴포넌트화하는 현재 시점에서, 비즈니스 로직과 UI의 결합과 마찬가지로 유지보수 문제를 발생시킬 수 있습니다.
UI 컴포넌트도 비즈니스 로직처럼 작은 책임 단위로 나눌 수 있습니다. ProfileCard 를 실제로 책임 단위로 쪼개보겠습니다.
// 아바타 이미지 표시 책임 function Avatar({ src, alt, size = 'medium' }) { const sizeClasses = { small: 'w-8 h-8', medium: 'w-16 h-16', large: 'w-24 h-24' }; return ( <img src={src} alt={alt} className={`rounded-full ${sizeClasses[size]}`} /> ); } // 사용자 이름/이메일 표시 책임 function UserInfo({ name, email }) { return ( <div className="user-info"> <h3 className="text-xl font-semibold">{name}</h3> <p className="text-sm text-gray-600">{email || '-'}</p> </div> ); } // 프로필 카드 레이아웃 구성 책임 function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile-card"> <Avatar src={avatar} alt={name} size="large" /> <UserInfo name={name} email={email} /> </div> ); }
이제 각 요소를 독립적으로 재사용할 수 있습니다.
// 댓글 섹션 - 작은 아바타와 이름만 function Comment({ author, content }) { return ( <div className="comment"> <Avatar src={author.avatar} alt={author.name} size="small" /> <div> <h4>{author.name}</h4> <p>{content}</p> </div> </div> ); } // 헤더 - 아바타만 function Header() { const { myInfo } = useMyInfo(); return ( <header> <Logo /> <Avatar src={myInfo?.avatar} alt={myInfo?.name} size="small" /> </header> ); } // 사용자 목록 - 아바타와 정보를 함께 function UserListItem({ user }) { return ( <li className="flex items-center gap-3"> <Avatar src={user.avatar} alt={user.name} size="medium" /> <UserInfo name={user.name} email={user.email} /> </li> ); }
이렇게 UI 로직도 책임 단위로 분리하게 되면 재사용성과 유지보수성을 더 좋게 만들 수 있습니다. 이렇게 UI 요소를 책임 단위로 분리하는 대표적인 패턴이 Atomic Design Pattern입니다.
주의해야 할 점은 반드시 모든 UI를 작은 컴포넌트 단위로 쪼갤 필요는 없다는 것입니다. 책임의 단위는 각 회사마다 다르고, 개발자마다 느끼는 책임의 범위도 다릅니다. 중요한 것은 실제로 재사용되는 단위, 독립적으로 변경되는 단위를 기준으로 적합한 책임의 단위를 찾아내고 관리하는 것입니다. 모든 요소를 강박적으로 쪼갤 필요는 없습니다.
3. 비즈니스 로직 세분화
비즈니스 로직과 UI를 분리했다고 해서 끝이 아닙니다. 비즈니스 로직 자체도 여러 책임으로 나눌 수 있습니다. Custom Hook 안에서도 여러 가지 일을 한꺼번에 처리하고 있다면, 그것 역시 단일 책임 원칙을 위반하는 것입니다.
예를 들어 장바구니 기능을 개발한다고 가정해봅시다.
// 여러 책임이 섞여있는 Hook function useCart() { const [items, setItems] = useState([]); const [loading, setLoading] = useState(false); // 장바구니 데이터 조회 useEffect(() => { setLoading(true); fetch('/api/cart') .then(res => res.json()) .then(data => setItems(data)) .finally(() => setLoading(false)); }, []); // 가격 계산 const totalPrice = items.reduce((sum, item) => sum + item.price * item.quantity, 0); const discount = totalPrice >= 50000 ? totalPrice * 0.1 : 0; const shippingFee = totalPrice >= 30000 ? 0 : 3000; const finalPrice = totalPrice - discount + shippingFee; // 상품 추가/삭제 const addItem = (product) => setItems(prev => [...prev, product]); const removeItem = (id) => setItems(prev => prev.filter(item => item.id !== id)); return { items, loading, totalPrice, discount, finalPrice, addItem, removeItem };
이 Hook은 다음과 같은 여러 책임을 가지고 있습니다
장바구니 데이터 가져오기
가격 계산 (총액, 할인, 배송비)
장바구니 아이템 관리
이렇게 되면 어떤 문제가 발생할까요?
주문 페이지에서 가격 계산만 필요한데, useCart 를 사용하면 불필요한 장바구니 데이터 fetching까지 실행됩니다
가격을 계산하는 코드는 외부 의존성이 없는 순수 함수 성격의 코드인데, 이를 테스트하기 위해서는 API mocking까지 해야합니다.
그럼 어떻게 책임단위로 분리할 수 있을까요?
// 가격 계산 로직만 담당 function calculatePrice(items) { const totalPrice = items.reduce((sum, item) => sum + item.price * item.quantity, 0); const discount = totalPrice >= 50000 ? totalPrice * 0.1 : 0; const shippingFee = totalPrice >= 30000 ? 0 : 3000; const finalPrice = totalPrice - discount + shippingFee; return { totalPrice, discount, shippingFee, finalPrice }; } // 장바구니 데이터 조회만 담당 function useCartData() { const [items, setItems] = useState([]); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/cart') .then(res => res.json()) .then(data => setItems(data)) .finally(() => setLoading(false)); }, []); return { items, setItems, loading }; } // 필요한 것들을 조합 function useCart() { const { items, setItems, loading } = useCartData(); const priceInfo = calculatePrice(items); const addItem = (product) => setItems(prev => [...prev, product]); const removeItem = (id) => setItems(prev => prev.filter(item => item.id !== id)); return { items, loading, ...priceInfo, addItem, removeItem }; }
로직을 분리하면 이제 필요한 곳에서 조립해 사용할 수도 있고, 각 모듈을 독립적으로 재사용 할 수도 있습니다. 테스트하기도 훨씬 수월해졌죠.
// 주문 페이지 - 가격 계산만 재사용 function OrderSummary({ orderItems }) { const { totalPrice, discount, finalPrice } = calculatePrice(orderItems); return ( <div> <p>총 금액: {totalPrice}원</p> <p>할인: -{discount}원</p> <p>최종 금액: {finalPrice}원</p> </div> ); } // 장바구니 페이지 - 전체 기능 사용 function CartPage() { const { items, finalPrice, addItem, removeItem } = useCart(); // ... } // 가격 계산 테스트 test('5만원 이상 구매시 10% 할인이 적용된다', () => { const items = [{ price: 50000, quantity: 1 }]; const result = calculatePrice(items); expect(result.discount).toBe(5000); });
이렇게 비즈니스 로직을 적당한 책임 단위로 분리해 재사용성을 높이고 유지보수를 용이하게 만들었습니다. 비즈니스 로직도 UI 로직과 마찬가지로 억지로 작은 단위로 분리하려고 힘쓸 필요는 없습니다. 우선 적당한 책임 단위로 만들고, 책임 분리가 필요한 시점에 분리해도 괜찮습니다. 가장 중요한건 분리가 필요하다고 느끼는 시점에는 반드시 분리를 해 주는 것이라고 생각합니다.
마치며
간단하게 단일 책임 원칙이 React에 어떤식으로 적용될 수 있는지 살펴봤습니다. 사실 위에 적은 이점 외에도 책임을 분리하면 좋은 점이 하나 더 있다고 생각합니다. 바로 AI에게 일을 맡길 때 굉장히 좋은 결과물로 나올 때가 많다는 것입니다. 이것저것 여러 책임을 부여한 컴포넌트를 AI에 만들어달라고 했을 때와 책임단위로 일을 분리한 뒤 한 개씩 AI에 만들어달라고 했을 때, 후자가 훨씬 더 좋은 결과물을 만들어 낼 때가 많았습니다. AI 생성물을 관리하는 입장에서도 후자가 훨씬 유리하겠죠.
단일 책임 원칙은 객체지향의 전유물이 아닙니다. SOLID 원칙도 그렇고 다른 개발원칙도 그렇습니다. React 개발에서도, 아니 어떤 개발에서도 적용할 수 있는 철학입니다. 중요한 건 원칙을 맹목적으로 따르는 게 아니라, 그 이면의 철학을 이해하고 상황에 맞게 적용하는 것입니다.
여러분의 컴포넌트는 너무 많은 책임을 떠안고 있진 않나요? 컴포넌트가 힘들어하고 관리자도 힘들어하고 있진 않은지요? 한 번 돌아보는 시간을 가져보시면 유익한 시간이 되리라 확신합니다.
결국 좋은 설계는 원칙을 맹목적으로 따르는 것이 아니라, 원칙을 ‘이해한 뒤 선택적으로 적용하는 것’에서 시작됩니다.

——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 11월 14일

Insight
재생에너지의 심장, ESS, 그리고 전기차
재생에너지는 이제 우리 삶의 일부가 되었습니다. 건물 옥상 곳곳에 설치된 소규모 태양광 발전기를 볼 수도 있고 고속도로를 달리다 보면 광활한 임야에 설치된 대규모 태양광 발전소를 볼 수 있습니다. 바닷가를 지나다 보면 하늘 높이 뻗어있는 풍력발전기도 볼 수 있죠. 재생에너지 발전은 발전기의 이름에서 짐작할 수 있듯이 태양광이나 바람같은 자연에너지를 사용해 전기를 발전하는 것을 말합니다. 그래서 재생에너지 발전에 대해 잘 모르는 분들이라도 친환경적이고 경제적일 것 같다는 느낌을 받는 분이 많을 것 같아요. 실제로 재생에너지 발전은 발전소가 한 번 설치되고 난 이후부터는 발전비용이 거의 들지 않고 환경도 훼손하지 않습니다.
듣기만 해도 매력적입니다. 점점 비싸지는 전기요금에 대비하기도 좋고 친환경적인 전기 발전이라면 하지 않을 이유가 없을 것 같아요. 그런데, 여러분은 재생에너지를 사용하고 계신가요? 기업들은 재생에너지를 사용하고 있을까요? 아마 사용하고 계시는 분들도 일부 있겠지만, 대부분은 그렇지 않을 것이라고 생각합니다. 그럼 이렇게 좋은 재생에너지를 왜 적극적으로 사용하지 못하는 걸까요? 무조건 많이 설치해서 전국에서 사용하는 전기를 모두 재생에너지로 발전해서 사용할 수는 없는 걸까요? 이렇게 하지 못하는 가장 큰 이유 중 하나는 재생에너지의 불확실성에 있습니다.
전기의 특징과 재생에너지의 한계
전기는 기본적으로 저장이 어렵고 생산과 동시에 소비되어야 합니다. 여러분이 집에서 전기를 사용하려고 전등을 켜는 순간 불이 바로 들어오는 것에서 알 수 있는 것처럼 전기는 계속해서 생산되어 우리에게 전달되고 바로 사용됩니다. 그래서 항상 적정량의 전기가 생산되고 적정량의 전기가 소비되어야 전력망이 안정된 상태로 운영될 수 있습니다. 이때 우리나라 전력망의 표준 주파수가 60Hz이며, 이를 안정적으로 유지해야 합니다(저희 회사명 식스티헤르츠도 바로 이 주파수를 의미합니다). 전기 생산량이 소비량보다 많으면 주파수가 높아져 전기설비에 문제가 발생할 수 있고, 전기 생산량이 소비량보다 적어지면 정전이 발생할 수 있습니다. 그래서 KPX(한국전력거래소)는 전력망을 안정시키기 위해 많은 노력을 하고 있습니다.
그런데 재생에너지는 어떤 특징을 가지고 있을까요? 자연에너지를 활용하는 만큼 전기의 발전량도 자연에 달려있을 수밖에 없습니다. 구름이 잔뜩 낀 날은 태양광 발전이 어렵고 바람 한 점 없는 날에는 풍력 발전이 어려울 거예요. 반면에 햇빛이 좋은 날에는 태양광 발전이 엄청나게 잘 되겠죠. 당장 한 가구를 위한 재생에너지 발전시설이 있다 하더라도 재생에너지만으로 전기를 충당하는 것은 불가능에 가깝다는 이야기가 됩니다.
예시를 들어보면, 한여름 오후 6시에 에어컨이 한창 가동되어 전력 소비가 많은 시기에 해가 지기 시작해 전력 공급이 점점 줄게 되면 정상적으로 소비 전력을 공급하지 못하는 상황이 올 거예요. 혹은, 전기를 쓰지 않는데도 태양광 발전이 너무 잘 되어 문제를 일으킬 수도 있게 되겠죠.
그렇다면 이런 재생에너지가 국가 전력망에 대규모로 연결되면 어떻게 될까요? 재생에너지 발전시설은 때로는 과도하게, 때로는 부족하게 계통에 전기를 공급하게 되고 이는 전력망을 불안정하게 만드는 위험 요소가 될 거예요. 이처럼 재생에너지의 불확실성과 간헐성은 전력망 안정성에 큰 도전 과제가 되고 있습니다.
재생에너지의 심장, ESS
그렇다면 재생에너지의 이런 한계를 어떻게 해결할 수 있을까요? 바로 여기서 ESS(Energy Storage System, 에너지저장시스템)가 등장합니다. ESS를 가장 쉽게 설명하자면 '거대한 배터리'라고 생각하시면 됩니다. 여러분이 스마트폰을 충전해두고 필요할 때 사용하는 것처럼, ESS도 전력을 저장해두었다가 필요할 때 꺼내 쓸 수 있게 해주는 시스템입니다.
예를 들어 볼까요? 한여름 낮 12시, 태양이 쨍쨍 내리쬐어 태양광 발전이 최대로 이루어지고 있습니다. 하지만 이 시간에는 대부분의 사람들이 외출해 있어서 전력 사용량이 많지 않아요. 이때 남는 전력을 ESS가 배터리에 저장해둡니다. 그리고 저녁 6시가 되면 사람들이 집에 돌아와 에어컨을 틀고 밥을 짓기 시작하면서 전력 사용량이 급증하죠. 하지만 태양은 이미 지기 시작해서 태양광 발전량은 줄어들고 있습니다. 바로 이때 ESS가 낮에 저장해둔 전력을 꺼내서 공급하는 거예요.
마치 우리 몸의 심장이 혈액을 온몸으로 순환시켜 생명을 유지하듯이, ESS는 에너지를 저장하고 공급하며 재생에너지 시스템의 생명력을 유지하는 핵심 역할을 합니다. 그래서 ESS를 '재생에너지의 심장'이라고 칭했습니다. ESS는 이렇게 재생에너지의 한계점을 보완하고 안정적인 전력공급을 할 수 있게 만들어 줍니다.
식스티헤르츠와 ESS
그럼 식스티헤르츠는 여기서 어떤 역할을 할까요? ESS는 위에 말씀드린 것처럼 재생에너지 생태계에서 아주 중요한 역할을 하지만, 자세하게 들여다 보면 단순한 거대 배터리에 불과합니다. 저장하면 저장이 되고, 방전하면 방전이 되는 게 전부인 것이죠.
여기서 식스티헤르츠가 '재생에너지의 뇌' 역할을 수행합니다. 식스티헤르츠는 ESS를 관리할 수 있는 소프트웨어를 개발해 ESS가 더 효율적으로 재생에너지를 활용할 수 있도록 돕습니다. 단순히 충방전 on/off만 하던 ESS를 더 다양한 상황에 맞춰 정밀하게 제어하는 것이죠. 구체적으로 몇 가지 예시를 들어보겠습니다.
1. 잔여 재생에너지 발전량 저장
태양광 발전량과 가구 소비량을 예측한 뒤 잉여 발전량이 예측되면 잉여 발전량은 ESS로 저장될 수 있도록 실시간으로 제어합니다. 저장된 전력은 필요한 때 방전해서 사용할 수 있게 되어, 재생에너지를 유연하게 활용할 수 있게 도와줍니다.
2. 전력 부하시간대별 요금 최적화
우리나라의 일부 전력 사용자들은 계절별/시간별로 전기요금이 경부하/중간부하/최대부하로 요금 체계가 나뉘어져 있습니다. 경부하 시간대에 사용하는 전기요금이 가장 저렴하고 최대부하 시간대에 사용하는 전기요금이 가장 비쌉니다.
그래서 경부하 시간대에는 ESS를 최대로 충전하고, 더 비싼 전기요금 시간대에 ESS를 방전해 전기요금을 절감할 수 있는 알고리즘을 개발해 운용하고 있습니다. 여기에 태양광 예측기술이 결합되어 경부하 시간대에 재생에너지만으로 ESS를 가득 충전할 수 없는 경우 부족한 전력은 계통을 통해 구매해 축적해 더 효율적으로 동작할 수 있도록 돕습니다.
3. DR 제도 대응
앞서 KPX에서 안정적인 전력망 유지를 위한 노력을 하고 있다고 말씀드렸는데요. 여러가지 방법 중 하나로 전력 사용을 조절하는 방법이 있습니다. KPX에서 전력이 부족한 시간대에는 전력 사용을 줄이라는 요청을 보내고, 전력이 남을 것 같은 시간대에는 전력 사용을 늘리라는 요청을 보내게 됩니다.
전력 사용을 줄이는 요청을 보내 전력망을 안정시키는 제도를 일반적인 DR(Demand Response)라고 부르고 전력 사용을 늘리는 요청을 보내 전력망을 안정시키는 제도를 플러스 DR이라고 부릅니다. 이런 DR 제도에 참여하게 되면 그에 응하는 보상을 받을 수 있고, ESS는 이런 제도에 참여하기에 최적화된 시스템입니다. DR에 적극 대응할 수 있도록 소프트웨어로 ESS를 제어할 수 있습니다.
전기차, 움직이는 ESS
그럼 전기차는 뜬금없이 왜 언급되었을까요? 전기차는 왜 전기차일까요? 전기로 동작하는 차량이기 때문에 전기차라고 부르겠지요. 전기로 운행이 가능하려면 무엇이 필요할까요? 바로 전기를 저장할 수 있는 배터리가 필요합니다. 그래야 전원 공급에서 멀어진 채로 장거리를 운전할 수 있겠죠. 그래서 전기차에도 모두 전기배터리가 있고 충전/방전을 할 수 있습니다. 최근에는 V2L(Vehicle to Load)라는 기술이 널리 퍼져 실제로 전기차에서 전기를 공급받아 캠핑이나 비상상황에 활용할 수 있게 되었습니다.
이제 왜 전기차가 언급되었는지 조금 감이 오시나요?
전기차는 이동이 가능하다.
전기차는 전기를 저장할 수 있다.
요약하면 전기차는 결국 움직일 수 있는 ESS라고 볼 수 있습니다. 이렇게 전기차를 계통과 연결해 전기차를 충전하는 것 뿐만 아니라 전기차를 방전시켜 전력망에 보낼 수 있는 기술을 V2G(Vehicle-to-Grid)라고 부릅니다.
사실 일반적인 ESS는 굉장히 비싸고 거대해서 일반 가정에서 활용하기 쉬운 시스템은 아닙니다. 그에 비해 전기차는 이제 널리 보급되어 쉽게 볼 수 있죠. 그래서 저희는 전기차를 ESS처럼 활용해 일반 가구의 재생에너지 활용도를 높이는 방안을 고민하고 소프트웨어로 해결할 수 있는 기술을 개발하고 있습니다. 언젠가는 전기차 차주들이 계통망을 안정화시키는데 가장 큰 역할을 할 것이라고 확신합니다.
함께 만들어갈 미래
식스티헤르츠에서는 이처럼 다양한 상황에 다양한 방법으로 재생에너지를 활용하는 소프트웨어를 개발해 운영하고 있습니다. 현재 전력시장과 재생에너지 생태계를 분석해 그에 맞는 알고리즘을 개발하고, 이를 적절하게 시각화해서 고객들이 사용하기 편하고 이해하기 쉬운 형태로 서비스를 만들어 나가고 있습니다.
재생에너지, V2G에 관심이 있으시다면 식스티헤르츠의 행보를 관심있게 지켜봐주시면 감사하겠습니다. 더 나아가 이런 기술 개발에 함께 참여하고 싶은 소프트웨어 엔지니어분들의 많은 관심 부탁드립니다.
By 방경민 ㅣ TVPP/FE Leader ㅣ 60Hertz
🔗 채용 페이지 바로가기!
#재생에너지 #에너지저장장치 #ESS #DR #전기차 #V2G #스마트그리드 #탄소중립 #에너지전환 #에너지혁신 #가상발전소 #태양광 #풍력 #전력망안정화 #식스티헤르츠 #에너지소프트웨어
2025년 9월 23일

Insight
재생에너지 혁신의 현장, 기후산업국제박람회 2025 참여 소식
식스티헤르츠가 지난 8월 27일부터 29일까지 부산 벡스코에서 열린 세계기후산업박람회(WCE 2025)에 참가했습니다. 이번 행사는 산업통상자원부, 국제에너지기구(IEA), 세계은행(WB)이 공동 주최한 글로벌 에너지·기후 대표 박람회로, 약 560개 국내외 선도 기업이 참여해 미래 에너지 혁신 기술을 선보이는 자리였습니다.
WCE 2025, “Energy for AI & AI for Energy”
올해 WCE의 주제는 “Energy for AI & AI for Energy” 였습니다. AI가 어떻게 지속 가능하고 안전하며 효율적인 글로벌 에너지 시스템을 만들어가는지, 또 인공지능이 에너지 수요 급증과 공급 안정화 문제를 어떻게 해결할 수 있는지가 주요 의제로 다뤄졌습니다. 전시장에서는 청정에너지, 에너지·AI, 미래교통, 환경, 해양, 기상 등 다양한 분야의 혁신 기술이 전시되었으며, 글로벌 리더십·에너지&AI·기후 등 3개의 서밋과 12개의 전문 회의 등이 함께 열렸습니다.
제1전시장 현장
이번 기후산업국제박람회 2025의 제1전시장에는 SK, 현대차, 삼성전자, 한화큐셀, 두산에너빌리티, 포스코, 효성중공업, 고려아연 등 국내 주요 기업들이 대거 참여해 미래 에너지 전환을 위한 다양한 기술과 솔루션을 선보였습니다. 특히, 청정에너지와 스마트그리드, 수소경제 등 첨단 분야의 전시가 활발히 이루어지며, 전력망 혁신과 탄소중립 실현을 위한 산업계의 방향성을 엿볼 수 있었습니다. 많은 참관객들이 최신 기술을 직접 체험하며, 기업 부스에서 관계자들과 활발히 교류하는 모습이 인상적이었습니다.

식스티헤르츠 부스 & 주요 성과
식스티헤르츠는 이번 박람회에서 대한민국 에너지대전 혁신상 특별관과 전력거래소(KPX) 부스를 통해 AI 기반 에너지 통합 관리 솔루션을 소개했습니다. 3일간 운영된 부스에는 공공기관, 대기업, 금융권 등 다양한 이해관계자가 방문하여 깊은 관심을 보였습니다.

특히 해외 재생에너지 사업 협력 가능성 논의, 에너지케어 및 모니터링 솔루션 문의, PPA 사무위탁과 신규 서비스 모델에 대해 의견을 나누는 등 다양한 후속 협업 기회가 마련될 것으로 기대됩니다.
KPX와 함께한 CMV 소개
전력거래소(KPX)와의 파트너십 프로젝트인 CMV(Cloud Motion Vector)도 전시 현장에서 소개되었습니다. 그래픽과 영상을 통해 방문객들에게 구름이동기반 초단기 발전량 예측 시스템으로 새로운 전력시장 시각화 도구를 선보였습니다.

혁신상·IR·세미나 참여 소식
이번 기후산업국제박람회 2025에서 식스티헤르츠는 기후·에너지 혁신상 시상식에서 산업통상자원부 장관상을 수상하며, 자사의 기술력과 성과를 공식적으로 인정받는 뜻깊은 성과를 거두었습니다. 또한 전시 기간 동안 IR 기업 소개 발표와 중부발전 주최 미니 세미나에 참여해, 에너지 전환을 위한 비전과 혁신적인 솔루션을 공유했습니다.

현장 반응 & 설문 결과
혁신상 특별관에서 진행한 설문조사에는 약 80여명이 참여했으며, 응답자의 다수는 제조업, 에너지·전력, 공공 부문 종사자였습니다. 응답자들은 ▲에너지 절감 및 수익성 개선 효과 ▲AI 활용 가능성 ▲파트너십 기회 등에 높은 관심을 보였습니다.

식스티헤르츠가 만든 의미
이번 WCE 2025 참가를 통해 식스티헤르츠는 국내외 주요 기관 및 기업과의 협력 가능성을 확인하고, AI 기반 에너지 혁신 솔루션의 시장성과 필요성을 다시 한번 입증했습니다. 앞으로도 재생에너지 확산과 효율적 관리, 그리고 탄소중립 실현을 위해 글로벌 파트너십을 확대해 나갈 예정입니다.
#기후산업국제박람회2025 #기후산업박람회 #기후에너지혁신상 #산업통상자원부 #한국에너지공단 #장관상표창 #재생에너지전환 #AI에너지
2025년 9월 9일

Impact
SOVAC과 함께하는 사회적가치 페스타 현장 스케치
식스티헤르츠는 지난 8월 25일(월)부터 26일(화)까지 삼성동 COEX Hall C에서 열린 제2회 대한민국 사회적가치 페스타에 참가해, 다양한 기관 및 기업들과 지속가능한 미래를 위한 협력 방안을 함께 고민하며 뜻깊은 시간을 보냈습니다.
대한민국 사회적 가치 페스타란? 🎊
대한상공회의소가 주최하고, SOVAC, SK텔레콤, 현대해상, 카카오임팩트, KOICA 등 여러 기관이 함께 주관하며 기후위기, 지역소멸, 미래세대, 디지털 격차 등 복합적인 사회문제를 민관 협력으로 해결하기 위해 마련된 국내 최대 규모의 사회적 가치 축제입니다. 올해 행사에는 13,000여 명의 참관객과 300여 개 기관·기업이 함께하며 다양한 강연과 전시를 통해 “지속가능한 미래를 설계(Designing the Sustainable Future)”라는 주제를 나눴습니다.

식스티헤르츠의 전시 부스 ☀️
식스티헤르츠는 이번 페스타에서 SOVAC “혁신의 길_기후위기 극복” 존에 전시 부스를 마련하고, 자사의 AI 기반 재생에너지 발전량 예측 및 관리 기술을 중심으로 다양한 에너지 자원을 통합적으로 운영할 수 있는 솔루션을 소개했습니다. 이를 통해 기후위기 대응과 안정적인 전력 운영, 그리고 탄소중립 실현을 돕고 있습니다. 이틀간의 현장은 다양한 공공기관, 대기업, 소셜벤처, 금융기관, 그리고 업계 전문가분들을 만나 식스티헤르츠의 기술과 비전을 공유할 수 있었던 뜻 깊은 자리였습니다. 특히, 에너지 전환 솔루션에 대한 많은 관심과 다양한 협력 가능성을 확인할 수 있는 시간이었습니다.

퀴즈 이벤트와 현장 🎁
식스티헤르츠는 부스를 찾아주신 분들을 위해 "도전, 식스티!" 퀴즈 이벤트도 함께 진행했습니다. 방문객들이 식스티헤르츠를 한층 더 이해하고 기억할 수 있는 퀴즈로, 재생에너지, 탄소중립 등에 관심을 보이며 현장 분위기를 더욱 뜨겁게 만들어 주었습니다. 또한 퀴즈를 모두 맞힌 정답자에게는 소정의 기념품을 드려서 현장 분위기도 더욱 활기찼습니다.

현장에서 만난 소중한 인연들 🤝
이번 페스타에서는 공공 및 민간을 포함해 다양한 소셜벤처 파트너사와의 만남을 통해 식스티헤르츠의 활동 영역을 넓히고, 새로운 협력의 기회를 모색할 수 있었습니다. 많은 분들께서 관심을 가지고 찾아주셔서 재생에너지 확산을 위한 사회적 가치 창출 활동에 대한 공감과 응원을 느낄 수 있었습니다. 🙏
앞으로의 계획 🗓️
이번 페스타는 단순한 전시회를 넘어, 재생에너지와 기후테크 분야의 리더로서 식스티헤르츠가 나아갈 방향을 다시 한번 확인하는 소중한 시간이었습니다. 앞으로도 현장에서 만난 소중한 인연들을 바탕으로 협업을 이어가며, 더 많은 기업과 기관이 지속가능한 에너지 전환에 동참할 수 있도록 최선을 다하겠습니다.
마무리하며 🚀
SOVAC과 함께하는 대한민국 사회적가치 페스타는 ‘함께 만드는 지속가능한 미래’라는 비전을 공유하는 자리였습니다. 식스티헤르츠도 이 여정의 한 축으로서, 기후위기 대응과 사회적 가치 확산을 위한 노력을 계속 이어가겠습니다.
함께해 주신 모든 분들께 진심으로 감사드립니다! 🌏💚
#식스티헤르츠 #SOVAC #사회적가치페스타 #재생에너지 #에너지전환 #AI기반솔루션 #기후테크 #지속가능한미래 #사회적가치 #소셜벤처
2025년 8월 28일

Insight
에너지고속도로란?
최근 뉴스에서 “에너지고속도로”라는 표현을 자주 접할 수 있습니다. 특히 “에너지고속도로” 구축이 정책적 화두로 떠오르기도 했는데요. 이름만 들으면 도로나 교통망이 떠오를 수도 있지만, 사실은 전기를 장거리-대규모로 효율적으로 이동시키기 위한 첨단 송전 인프라를 가리키는 비유적인 표현입니다. 이번 블로그 글에서는 “에너지고속도로”와 함께 관련된 주요 키워드를 살펴보도록 하겠습니다.
왜 ‘고속도로’라는 표현을 쓰나요?
자동차 고속도로가 사람과 물자를 빠르고 효율적으로 이동시키듯, "에너지고속도로"는 발전된 전기를 멀리 있는 소비지로 신속하고 효율적으로 ‘운송’하는 첨단 전력망을 의미합니다.
왜 이런 개념이 필요할까요?
전 세계가 탄소중립을 목표로 재생에너지 비중을 확대하고 있지만, 대부분 발전소 입지와 수요가 일치하지 않는 문제가 발생하고 있습니다. 다시 말해 재생에너지는 친환경적이지만 입지가 한정적입니다. 예를 들어, 대규모 태양광 발전소는 햇빛이 좋은 공장 지붕, 임야, 평야 등에 설치가 됩니다. 해상풍력발전단지는 어떨까요? 바람이 좋은 해안이나 산악지대를 선호합니다. 반면에 주요 전력 소비는 대도시나 도심 또는 산업지대에 집중되고 있습니다. 그래서 이러한 격차를 메우고 거리를 잇기 위한 인프라 혁신으로 “에너지고속도로”와 같은 첨단 전력망이 필요합니다.
기술적 핵심
"에너지고속도로"는 기존 송전망과는 다른 기술이 적용됩니다. 매우 긴 거리에서도 전력 손실이 적어야 하며, 대규모 전력을 한 번에 안정적으로 이송할 수 있어야 하기 때문입니다. 그래서 초고압 직류 송전(HVDC)과 같은 핵심 기술이 필요합니다. 또한 단순한 ‘길’이 아닌 스마트하고 유연한 에너지 네트워크를 기반으로 만들어져야 합니다.
주요 특징
장거리 초고압 송전: 태양광 풍력과 같이 먼 거리에 위치한 대규모 재생에너지 발전소에서 도심이나 산업단지로 전력 전송
디지털-스마트 그리드 기술 접목: AI, IoT 기반 실시간 수요관리와 분산자원 통합
지역 간 연계성 강화: 지역 간 전력망을 연결해 수급 안정화
경제-환경적 가치
"에너지고속도로"는 단순한 전력망이 아닙니다. 재생에너지 발전 단가가 낮은 지역에서 전력 조달 시 전력 가격 안정화에 기여하며, 기존의 화력 발전소 대체 및 탄소중립 실현에 기여 가치는 매우 클 것으로 기대됩니다.
단점 및 한계
하지만 초고압 직류(HVDC) 송전망 건설에는 대규모의 투자가 필요합니다. 해저케이블, 변환소(AC—>DC 변환), 관리 시스템 등 발생 비용이 매우 큽니다. 정부 보조나 전기요금 인상과 같은 논쟁도 불가피합니다. 또한 설계, 인허가, 협의, 시공까지 긴 건설 기간이 걸릴 수도 있습니다. 기술 의존성이나 표준 문제나 초기 투자에 더해 운영 유지 비용이나 보안도 큰 문제가 될 수 있습니다. 이렇듯 "에너지고속도로"는 재생에너지 전환의 필수 인프라지만, 비용, 시간, 사회적 합의, 기술 의존 등 해결해야 할 도전 과제가 매우 많습니다.
보이지 않는 혁신의 길
그럼에도 자동차 고속도로가 산업화를 이끌었듯, "에너지고속도로"는 재생에너지 전환을 가능하게 만드는 전략적인 인프라입니다. 발전소는 지방에, 소비는 도시에와 같은 구조적 문제를 해결하며 재생에너지의 불규칙성을 보완할 수 있습니다. 앞으로 우리나라가 이 거대한 보이지 않는 도로를 어떻게 설계하고 구축할지 에너지 전환과 관련한 중요한 과제가 될 것으로 보입니다.
#에너지고속도로 #송전망혁신 #전력망 #탄소중립 #에너지전환 #재생에너지확산 #전력인프라 #HVDC #스마트그리드 #분산에너지
2025년 7월 24일

Insight
식스티헤르츠, 2025년 '혁신 프리미어 1000' 기업 선정
식스티헤르츠가 2025년 '혁신 프리미어 1000' 기업에 선정 되었습니다!
지난 5월 14일, 금융위원회는 산업통상자원부, 과학기술정보통신부, 중소벤처기업부 등 13개 부처와 함께 2025년 제1차 ‘혁신 프리미어 1000’ 기업으로 총 509개의 중소·중견기업을 선정했다고 발표했습니다. (참조: 대한민국정책브리핑, 중소·중견기업 509개, '혁신 프리미어 1000' 선정)
이 프로그램은 기술 혁신을 통해 신제품 개발, 신규 시장 개척, 부가가치 창출, 고용 확대에 기여할 수 있는 유망 기업을 발굴·지원하기 위한 정부의 중점 정책 중 하나입니다.
식스티헤르츠는 이번 선정을 통해 AI 기반 재생에너지 발전 예측 및 제어 기술의 혁신성과 성장 가능성을 정부로부터 공식적으로 인정받았습니다. 이는 기술력은 물론, 지속가능한 에너지 전환을 이끄는 기업으로서의 경쟁력과 비전을 입증하는 중요한 이정표가 되었습니다.
식스티헤르츠의 주요 기술은 소규모 재생에너지 자원을 통합 관리하는 가상발전소(VPP) 통합 소프트웨어와 AI를 활용한 발전량 예측 기술을 기반으로, 재생에너지의 불확실성을 줄이고 전력 운영의 효율성을 높이는 데 중점을 두고 있습니다. 이러한 기술력은 재생에너지 생태계 고도화에 기여하며, 이번 평가에서 높은 점수를 받은 핵심 요인으로 분석됩니다.
이번 선정을 계기로 식스티헤르츠는 정책금융기관의 맞춤형 지원과 부처별 특화 사업의 혜택을 바탕으로, 기술 중심의 에너지 전환은 물론 글로벌 시장 진출에도 더욱 박차를 가할 계획입니다.
[회사 소개]
식스티헤르츠는 2021년, 전국 13만 개의 태양광·풍력·에너지저장장치(ESS)를 연결한 ‘대한민국 가상발전소’를 공개하며 주목을 받았습니다. 이후 약 8만 개의 재생에너지 발전소(총 18GW)의 위치와 발전량을 AI로 시각화한 ‘햇빛바람지도’를 무료로 제공하는 등, 에너지 데이터 기반 서비스를 지속 확장하고 있습니다.
2023년: 자체 개발한 에너지관리시스템(EMS)으로 CES 혁신상 수상
2024년: IPEF(인도·태평양 경제 프레임워크) 선정 아시아·태평양 100대 기후테크 기업
앞으로도 식스티헤르츠는 기술을 통해 더 많은 사람들이 지속가능한 에너지 전환에 참여할 수 있도록 혁신을 이어가겠습니다.
👉 홈페이지 바로가기
#식스티헤르츠 #재생에너지 #에너지전환 #가상발전소 #인공지능 #RE100 #탄소중립 #기술혁신 #혁신프리미어1000 #선정
2025년 5월 19일

Insight
작은 변화, 큰 영향
안녕하세요,
에너지 IT 소셜벤처 식스티헤르츠입니다.
지난 4월 23일부터 25일까지 서울 양재동 aT센터에서 열린 '2025 자동차부품산업 ESG·탄소중립 박람회'에서 식스티헤르츠 부스를 방문해주신 모든 분들께 진심으로 감사드립니다.

이번 박람회에서 식스티헤르츠는 기업의 지속가능경영을 실현할 수 있도록 돕는 다양한 에너지 IT 솔루션을 제1 전시장 제조혁신관(현대차-기아 제조솔루션본부 협력관) 및 제2전시장 재생에너지관(현대건설-현대차증권 협력관)을 통해 아래와 같이 소개했습니다.
태양광 발전소 구축 및 운영 솔루션
전력 통합관리 모니터링 시스템(EMS)
온사이트 PPA 및 RE100 달성 컨설팅
V2G 에너지 신산업 생태계 구축
수요반응(DR)을 통한 전력 효율화


특히, 박람회 기간 제조 산업을 포함한 많은 방문객들이 공장 지붕이나 주차장 등 유휴 부지를 활용한 태양광 구축 사례에 많은 관심을 보여주셨으며, 재생에너지 전환을 통한 비용 절감 방안에 대한 깊이 있는 상담도 적극적으로 요청해 주셨습니다.
예를 들어, 약 3,000평 규모의 공장에 1MW급 태양광 발전소를 도입하면 연간 약 3,000만원의 전기료 절감, 에너지 관련 부가 수익 창출, 그리고 604톤 규모의 온실가스 감축 효과를 기대할 수 있습니다.
이를 위해 식스티헤르츠의 고객 환경 맞춤형 토탈 솔루션을 도입 시 ESG 경영을 더욱 효율적이고 체계적으로 실현할 수 있습니다.
[고객 맞춤형 솔루션]
태양광 설비 도입
실시간 발전량 모니터링
RE100 성과 분석
[태양광 도입 및 모니터링 솔루션 구축 최신 사례]
인천 남동 스마트그린산업단지 에너지 자급자족 인프라 구축 및 운영사업
태양광 패널부터 인버터, 모니터링 솔루션의 통합 구축
고객의 전기 사용량에 따른 과금 정산서 발행 (임대형 발전소 대상)
실시간 출력 제어 및 스마트 O&M을 통한 발전량 오차율 및 고장 예측 감지
현대자동차 국내외 공장 태양광 모니터링 시스템 구축
현대자동차 국내 주요 공장 다수 온-프레미스 태양광 모니터링 스마트 O&M 시스템 구축 (5MW~9MW)
현대자동차 미국 북미 공장 온-프레미스 태양광 모니터링 시스템 구축
앞으로도 식스티헤르츠는 탄소중립과 에너지 전환을 선도하는 신뢰받는 파트너로서, 귀사의 지속가능한 성장을 적극 지원하겠습니다.
지속가능한 미래를 함께 만들어가길 기대합니다!
👉 식스티헤르츠 솔루션 자세히 보기
#식스티헤르츠 #ESG #RE100 #탄소중립 #탄소저감 #자동차부품산업 #지속가능 #재생에너지 #태양광 #EMS #PPA #REC #V2G #DR
2025년 4월 30일

Tech
가상발전소(VPP) 통합 솔루션
분산에너지 자원의 특징
전세계적으로 탄소중립이 주요 화두가 되면서, 탄소중립 달성 수단으로 분산에너지에 대한 관심이 증대되고 있습니다. 분산에너지는 전통적인 중앙집중식 발전소를 통한 전력 수급 시스템에 대비되는 개념으로, 에너지의 사용지역 인근에서 생산되는 에너지를 말합니다. 기본적으로 분산에너지는 규모가 작고 에너지 사용지역 인근에 위치한다는 특징을 가지고 있습니다.
분산에너지 자원의 확대
분산에너지는 기존의 대단위 발전소 및 송전선을 건설하는 방식보다 용이하며, 송 · 배전망을 신규로 건설하기 위해 투입되는 인프라 건축비용과 운영비용을 크게 절감할 수 있다는 장점이 있습니다. 특히 분산에너지 자원들은 친환경 재생에너지로 온실가스나 탄소배출 감소에 기여하는 바가 크다고 여겨집니다. 하지만 분산에너지 자원 중 태양광과 풍력은 일조량과 풍량에 의존하기 때문에 변동성이 생길 수 있고, 이로 인해 전력계통의 안전성을 저해할 수 있습니다. 우리나라도 태양광 중심으로 재생에너지 비중을 확대하고 있어서 변동성 문제를 완화하거나 발전 효율을 높일 수 있는 방안에 대한 관심 및 관련 정책 등이 확대되고 있습니다.
분산에너지 자원의 효율적 관리 운영을 위한 솔루션
위에서 언급한 재생에너지 비중이 확대되면서 발전 효율 증대, 발전량 예측 및 관리 등 관련 분야의 기술 개발 및 도입이 활발히 진행되고 있는 가운데, 식스티헤르츠에서 출시한 Energy Scrum은 분산에너지 자원을 효율적으로 관리 및 운영하는데 최적화된 에너지 관리 시스템입니다. Energy Scrum을 통하면 PV, ESS, 연료 전지, EV 충전기 등 다양한 분산자원을 AI를 기반으로 전체 에너지 공급과 수요를 정확하게 예측하여 하나의 통합된 시각으로 확인 및 관리할 수 있습니다.

사용자 친화적으로 설계된 에너지 관리 시스템
Energy Scrum은 일부 번거로운 프로세스를 최소화하여 분산자원을 조율할 수 있도록, 사용자가 사용자별 운영 시나리오를 적용하여 친환경 전기 사용을 극대화하는 것과 같은 목표를 달성할 수 있도록 지원합니다. 예를 들어 Energy Scrum을 오래된 주유소에 적용시 친환경 에너지 스테이션으로 전환할 수 있습니다.

AI 기반 기술 혁신으로 고도화
Energy Scrum은 다양한 분산자원을 연결하고 클라우드 기반 시스템에서 방대한 양의 비정형 데이터를 관리할 수 있는 OpenAPI 서비스를 제공합니다. 분산자원과 지역 IoT 센서, 기상 위성과 같은 외부 소스의 정보를 결합하여 AI 모델을 점진적으로 훈련하고, 데이터와 학습을 축적하여 전체 에너지 공급과 수요에 대한 보다 정확한 예측을 제공합니다. 또한 예측된 에너지 정보를 활용하여 사용자의 요구에 맞는 다양한 모드(예: 친환경 전기 사용량 극대화 모드)를 제공합니다. 따라서 사용자는 목표를 달성하기 위해 원하는 방식으로 분산자원을 조정할 수 있습니다.

신재생에너지 시장을 겨냥한 차별화
Energy Scrum의 차별화된 강점은 대부분의 발전사들이 사용하고 있는 모니터링 솔루션에 비해 제조사를 포함한 다양한 고객의 니즈에 맞춤형으로 설계가 가능하며, 태양광 풍력 뿐 만이 아닌 다양한 분산에너지 자원들을 효율적으로 관리할 수 있다는 것입니다. 특히 관리 및 운영의 영역을 넘어 발전소유주들의 시장을 연결하여 재생에너지의 활성화와 수익을 만들 수 있는 생태계를 구축하는 통합 플랫폼으로 구현되었다는 점입니다. 예를 들어 V2G (Vehicle-to-grid, 전기자동차를 전력망과 연결해 배터리의 남은 전력을 이용) 기술을 적용 및 전기차를 에너지 저장 장치로 활용하는 시장을 연결하여 주행 중 남은 전력을 건물에 공급하거나 판매할 수 있는 플랫폼으로 활성화할 수 있습니다.
CES 2023 혁신상 수상
식스티헤르츠의 에너지관리시스템 Energy Scrum은 세계 최대 IT 전시회 ‘CES 2023’에서 지속 가능성, 에코 디자인 및 스마트 에너지 분야에서 혁신상을 수상한 바 있습니다. 친환경 분산전원이 전 세계적으로 빠르게 확대됨에 따라 이를 통합적으로 관리할 수 있는 시스템 수요가 지속적으로 증가하고 있는 가운데, 식스티헤르츠의 기술력이 집약된 Energy Scrum은 첨단 에너지 관리시스템으로 재생에너지 관리의 새로운 지평을 열었다는 평가를 받았습니다. 특히 기존 태양광 중심의 가상발전소 개념을 넘어, 풍력과 에너지저장장치(ESS)까지 통합 관리하는 종합 솔루션으로서 재생에너지의 효율적인 운영을 통해 재생에너지 확산에 기여할 수 있기를 기대합니다.
#식스티헤르츠 #재생에너지 #에너지관리시스템 #EMS #VPP #ESS
2025년 4월 25일

Impact
기술로 그리는 지속가능한 에너지 전환
전 세계적으로 RE100과 탄소중립이 기업의 새로운 기준이 되어가고 있는 지금, ‘재생에너지를 더 쉽게, 더 효과적으로’ 쓰기 위한 기술이 필요합니다. 식스티헤르츠는 이러한 전환을 현실로 만들고 있는 에너지 IT 소셜벤처입니다. 인공지능, 빅데이터, 클라우드 기술을 바탕으로 분산된 재생에너지 자원의 가치를 극대화하며, 사회와 환경에 긍정적인 변화를 만들어가고 있습니다.
수치로 증명된 임팩트
지난 해 기준 식스티헤르츠는 8개 기업을 대상으로 재생에너지 구독 서비스를 운영하며 총 11,901MWh의 재생에너지 사용을 이끌어냈습니다. 이를 통해 약 5,089tCO2e의 탄소배출을 저감하는 성과를 달성했으며, 이는 탄소중립 실현을 위한 의미 있는 진전이었습니다. 뿐만 아니라, 소셜벤처 및 중소기업을 위한 소규모 REC 구매 지원, 월별 리포팅 시스템 운영 등을 통해 에너지 접근성과 투명성도 높이고 있습니다.
기술로 완성하는 에너지 전환
식스티헤르츠는 기후, 수요, 공급의 불확실성 속에서도 전력망을 안정적으로 운영할 수 있도록 최신 기술을 적용한 다양한 솔루션을 개발 및 운영하고 있습니다.
☀️ 햇빛바람지도
국내 유일의 재생에너지 발전량 예측 공개 서비스로, 전국의 태양광/풍력 발전소 발전량을 AI 기반으로 예측 및 시각화하여 일 발전량 및 내일 발전량 예측치를 제공합니다. 재생에너지 발전량에 영향을 미치는 기상정보와 발전량을 함께 볼 수 있습니다.
🔋 에너지스크럼
태양광 발전소, ESS, EV 충전소 등 분산 전원을 통합 관리하고, 실시간 예측을 통해 공급과 소비의 균형을 맞춥니다. 클라우드 기반으로 보안성과 확장성까지 갖췄으며, 실제 전력거래소와 연계해 수요자 중심의 운영 최적화를 고도화하고 있습니다.
사회적 가치와 지속가능성
식스티헤르츠는 단순히 기술을 제공하는 기업을 넘어, 지속가능한 비즈니스 생태계를 만드는 파트너입니다.
RE100 기업 지원: 탄소중립 목표를 가진 기업에게 손쉬운 전력 전환을 위한 구독형 서비스를 제공합니다.
소상공인 재생에너지 전환 지원: 재정적 부담이 큰 초기 기업에게도 100% 재생에너지 사용 기회를 제공합니다.
사회적 성과 측정: 정량/정성 지표 기반의 프로젝트 영향 분석을 수행합니다.
햇빛발전소 기증: 에너지 취약계층 지원 및 지역사회 환원을 위한 프로젝트를 확산해 갑니다.
확장하는 비전
식스티헤르츠는 앞으로 다음과 같은 방향으로 에너지 혁신을 이어가기 위한 플랜을 실천하고 있습니다.
글로벌 플랫폼 확대
국내에서 검증된 기술을 아시아-태평양 지역으로 확장
지역 간 재생에너지 거래를 위한 인프라 확보
RE100 시뮬레이션 서비스 고도화
기업 맞춤형 컨설팅 제공
더 많은 기업의 참여를 유도
V2G 기술을 활용한 에너지 효율화
EV를 에너지 네트워크의 한 축으로 활용
분산 전원의 활용도를 높이는 차세대 전략
지속가능한 에너지 생태계를 위한 여정
식스티헤르츠는 단순한 에너지 기술기업을 넘어, 재생에너지 전환을 앞당기며, 기업과 사회가 함께 탄소중립을 향해 나아갈 수 있도록 다음 세대를 위한 기술과 협력의 터전을 마련하고 있습니다. 앞으로도 식스티헤르츠는 지속가능한 미래를 위한 실질적 변화를 만들어갈 것입니다.
#식스티헤르츠 #소셜벤처 #SDG #재생에너지 #RE100 #탄소중립 #탄소배출 #햇빛발전소
2025년 4월 24일

People & Culture
식스티헤르츠(60Hertz)를 소개합니다
일상을 지키는 특별한 기술을 만드는 팀
전력망을 안정적으로 관리하는 것은 매우 중요합니다.
전력망이 안정적으로 유지되지 않을 경우, 대규모 정전(black out)과 같은 국가적 재난 사태로 이어질 수 있기 때문입니다. 전력의 공급과 수요가 일치할 때, 대한민국의 전력망은 ‘60Hertz’라는 주파수를 유지합니다.
그래서 식스티헤르츠(60Hertz)는 우리의 안온한 일상을 지키는 균형을 의미합니다.
식스티헤르츠는 우리의 일상을 지키는 특별한 기술을 만듭니다. 🙂

다음 세대를 위한 에너지 기업
“우리가 기후위기를 막을 수 있는 마지막 세대이다”
우리 식스티헤르츠 구성원이 공유하는 세계관입니다.
지구 평균 온도가 매년 상승하고 있는 지금, 이를 해결할 중요한 열쇠는 ‘에너지 전환’입니다. 우리는 IT 기술을 통해 더 효율적이고 지속가능한 에너지 생태계를 구현하여 재생에너지 확산에 기여하고자 합니다.
기술로 이루어낸 작은 변화들이 모여, 다음 세대를 위한 큰 변화를 만들어 갈 수 있다고 믿습니다.🙏

식스티헤르츠와 함께해주세요!
사람들의 일상을 지키고 기후위기를 막기 위해 노력하는 식스티헤르츠 여정에 함께해주세요.🚀

우리는 지속가능한 미래를 위해 끊임없이 학습하고 함께 성장합니다.
변화를 두려워하지 않고 새로운 기술과 지식을 습득하고, 솔직하게 의견을 나누고, 서로에게 최고의 동료가 되고자 노력합니다.
식스티헤르츠의 세계관에 공감한다면 주저하지 말고 알려주세요. 우리는 내일을 향해 함께 달릴 동료를 기다립니다.🏃➡️
자세히 알아보기
👉 Embedded firmware Engineer (임베디드 펌웨어 개발, EE)
👉 Sales(영업 기획)
👉 Project Manager
👉 R&D 정부 과제 기획/관리
2025년 4월 23일

Insight
식스티헤르츠 홈페이지가 새로워졌습니다!
안녕하세요,
에너지 IT 소셜벤처 식스티헤르츠(60Hertz) 입니다. 🚀
오늘은 여러분께 새로워진 식스티헤르츠 공식 홈페이지 소식을 전해드립니다.
✨ 무엇이 달라졌을까요?
더 빠르고 직관적인 사용자 경험
복잡하지 않은 구조, 깔끔한 디자인, 그리고 모바일에서도 최적화된 화면으로 누구나 편리하게 정보를 확인하실 수 있습니다.
서비스 중심의 콘텐츠 구성
재생에너지 생산-관리-유통의 전반적인 Life cycle 솔루션을 제공하는 식스티헤르츠의 주요 기술과 서비스를 한눈에 확인할 수 있도록 정리했습니다.
글로벌 확장을 위한 다국어 지원
글로벌 파트너들과의 소통 강화를 위해 영문 페이지를 확장하였습니다.
🌍 왜 지금, 홈페이지를 개편했을까요?
식스티헤르츠는 국내를 넘어 베트남, 미국, 독일 등 글로벌 시장 진출을 본격화하고 있으며
에너지 전환, 탄소중립, 기후테크 등 빠르게 변화하는 흐름 속에서 식스티헤르츠의 기술과 철학을 더 많은 분들과 나누고 싶었습니다.
👀 지금 바로 방문해보세요!
새로워진 홈페이지에서 식스티헤르츠가 어떻게 기술로 기후 위기에 답하고 있는지 직접 확인해 보세요.
👉 https://60hz.io
여러분의 방문을 환영합니다!
앞으로도 더욱 투명하고, 혁신적이며, 사회적 가치를 실현하는 식스티헤르츠가 되겠습니다.
고맙습니다.
식스티헤르츠팀 드림
2025년 4월 21일
All
Tech
Insight
People & Culture
Impact
Tech
[개발자 인터뷰 ①] “기술에 얽매이지 않고 현실 문제 해결에 집중하는 실용적인 개발을 하고 싶어요.” / Tech Lead 최성원 님
본인 소개 부탁드립니다.
안녕하세요. 개발 조직을 리드하고 있는 최성원입니다.
입사한 지는 약 3년 정도 되었고, 서비스 개발을 중심으로 다양한 업무를 수행해왔어요. 특히 기술과 비즈니스를 함께 이해하는 경험을 통해 개발자의 시선에서 서비스의 방향과 가치를 고민하고 있습니다.
식스티헤르츠 합류 전 성원님의 커리어를 소개해주세요.
2009년쯤, 아이폰이 막 출시되면서 ‘앱스토어’라는 새로운 플랫폼이 등장했어요. 대학 선배와 함께 “우리도 직접 앱을 만들어보자”는 이야기를 하게 됐고, ‘쓰임epub’라는 회사를 창업해서 저는 CTO 역할로 합류했어요. 사회적으로 의미 있게 쓰이는 서비스를 만들면 좋겠다는 마음을 담은 회사였죠.
이후 회사가 점차 커지면서 한 콘텐츠 회사로 합류하게 되었는데, 그 회사가 지금의 카카오엔터테인먼트에요. 처음에는 iOS 개발자로 시작했고, 이후 웹 개발로 영역을 넓혀 2017년부터는 프론트엔드 개발자로 일을 하였지요. 카카오엔터테인먼트에서의 재직 기간은 약 10년 정도였는데, 그 중 3년 정도는 팀장을 맡아 개발 조직을 이끌었어요.
식스티헤르츠 합류 스토리도 궁금해요.
식스티헤르츠에서 먼저 제안을 주셨고, 당시 저는 카카오엔터테인먼트에서 팀장으로 일하며 큰 프로젝트를 맡고 있어서 처음 제안은 고사했어요. 그런데 신기하게도, 그 프로젝트가 마무리될 즈음 다시 연락이 왔어요. (웃음)
그 시점에 제가 고민하던 게 하나 있었어요. 기술이 상향 평준화되면서, 사람들이 플랫폼을 선택하는 기준이 ‘기술’보다는 ‘콘텐츠’나 ‘도메인 가치’로 옮겨가고 있다는 느낌이었거든요. 점점 내가 기술로 만들어낼 수 있는 임팩트가 줄어든다는 생각도 들었고요. 그때 식스티헤르츠의 ‘재생에너지’라는 도메인이 새롭고 매력적으로 다가왔어요. 아직 제가 경험해보지 못한 분야였고, 성장 가능성과 사회적 임팩트가 분명한 영역이라고 느껴졌기 때문이죠.
재생에너지 도메인은 실제로 와서 보니 어땠나요?
기존에 경험했던 콘텐츠 플랫폼과는 정말 달랐어요. 솔직히 말하면, 기술 환경만 놓고 보면 다소 낙후되어 있다고 말할 수 있고, 최신 기술과 트렌드 자체를 즐기는 개발자라면 처음엔 아쉬울 수도 있는 환경이었던 것이죠.
그런데 저는 결국 중요한 건 내가 가진 기술을 어디에, 어떻게 쓰느냐라고 생각해요. 그래서 그러한 환경이 제약으로 느껴지지는 않았어요. 특히 요즘은 AI 기술이 빠르게 발전하면서, 특정 기술의 난이도보다는 전체 구조를 이해하고 문제를 정의하는 역량이 더 중요해지고 있잖아요. 그런 점에서 보면 이러한 환경이 오히려 시대와 잘 맞는다고 느끼기도 해요. 특정 기술 스택이나 환경에 얽매이지 않고, 현실의 문제 해결에 집중하고 싶은 개발자라면 충분히 의미 있는 도메인이라고 생각해요.
방금 살짝 말씀하신 것 같은데 성원님은 어떤 개발자라고 생각하시나요?
“기술의 깊이보다 문제 해결의 깊이를 더 중요하게 생각합니다.”
저는 고객의 문제를 해결하고, 실제로 결과를 만들어내는 걸 좋아하는 개발자입니다. 팀에서도 늘 “우리는 실용적으로 가자”라는 이야기를 자주 해요.
예전에 학부 시절 근로장학생으로 일하면서 표절 검사용 텍스트 분절 프로그램을 만들어달라는 요청을 받은 적이 있어요. 당시 저는 윈도우 프로그램을 만들 줄 몰랐고, 그래서 콘솔 프로그램으로 간단히 구현했는데 그걸 오랫동안 잘 쓰시더라고요. 만약 그때 “이건 제가 못 해요”, “이 기술은 몰라요”라고 했다면 문제는 해결되지 않았겠죠. 저는 요구사항의 본질에 집중해서, 가능한 방식으로 빠르게 문제를 해결한 거예요.
고객은 ‘왜 필요한지’보다는 ‘무엇이 필요한지’만 이야기하는 경우가 많아요. 그럴 때 개발자가 한 발 더 나서서 문제를 정의하고, 현실적인 해결책을 제안해야 한다고 생각해요. 재생에너지 분야에서도 기본적인 태도는 크게 다르지 않다고 봐요.
성원님과 함께 일하는 식스티헤르츠 개발자들은 어떤 분들인가요?
사업에 관심이 많은 개발자들이 꽤 있어요. 개발자 입장에서는 사업의 전체 맥락을 모르면 혼란스러울 수 있는데, 이를 개발자의 언어로 설명해주는 경우는 많지 않거든요. 저는 개발과 사업 양쪽을 경험해왔기 때문에 제가 개발자의 시선에서 사업 이야기를 공유하면 팀원들이 정말 흥미롭게 듣고 또 서로 의견을 주고받고 있어요.
아 테크 리드들이요? 테크 리드 분들도 정말 자랑스럽죠. 기본적인 개발 역량도 뛰어나지만, 문제가 생기면 어떻게든 파고들어 해결하려는 사람들이에요. 답이 바로 보이지 않아도 결국 답을 만들어내는 사람들, 그래서 신뢰할 수 있는 사람들! 이러한 서로간의 신뢰가 우리팀의 가장 큰 강점이라고 생각해요.
개발팀의 조직 분위기는 어떤가요?
새로운 개발자가 들어오면 항상 하는 이야기가 있어요. “코드와 너무 사랑에 빠지지 말자.”
그래서 ‘코드가 곧 나다’라는 분위기는 없어요. 코드 리뷰에서도 직급과 상관없이 누구나 합리적인 의견을 낼 수 있고, 의견이 갈리면 다른 사람을 더 참여시켜 논의하죠. 그래도 판단이 어려우면, 굳이 내 의견을 끝까지 관철하기보다는 동료의 의견을 존중하자고 이야기해요. 결과가 비슷하다면 팀워크가 더 중요하니까요. 덕분에 지금까지 서로간의 관계로 인한 문제는 거의 없었어요.
앞으로 우리 개발팀이 어떤 팀이 되었으면 하나요?
AI 활용을 더 적극적으로 장려하고 싶어요. 이미 회사 차원에서 여러 도구를 지원하고 있고, 내부적으로도 AI를 활용해 산출물을 만드는 도구를 개발하고 있는데, 앞으로는 이런 흐름을 더 자연스럽게 조직문화에 반영하고 싶어요.
또 하나는 예측 가능한 팀이 되는 것이에요. 회사도 팀도 빠르게 성장하다 보니 조직 안정화가 숙제였는데, 이제는 성과와 결과를 조금 더 예측할 수 있는 팀이 되고 싶어요.
어떤 분이 팀에 합류하면 좋을까요?
고객이 진짜로 해결하고 싶은 문제가 무엇인지 질문하고, 본질을 파악하려는 분이었으면 좋겠어요. “이건 내 문제가 아니다”가 아니라, “내가 해결해보자”라고 생각하는 사람. 스스로를 문제 해결사라고 생각하고, 안 되는 이유를 찾기보다는 어떻게든 해결하려고 노력하는 분과 함께하고 싶어요.
마지막으로, 관심 있는 분들을 위해 성원님은 면접에서 어떤 걸 가장 중요하게 보시는지 알려주세요.
저는 정답이 없는 질문을 많이 해요. 예를 들면 개발자로서의 커리어 방향 같은 질문이요. 저는 개발을 하나의 도구라고 생각하기 때문에, 반드시 정해진 목표가 있어야 한다고 보지는 않아요. 다만 그 사람이 어디까지 바라보며 일하는지, 어떤 고민을 하고 있는지를 알고 싶어요. 그래서 특정한 답을 기대하기보다는, 평소 생각을 솔직하게 이야기해주시는 게 가장 좋아요.
—-------------------
식스티헤르츠는 지금 성장의 다음 단계를 함께 만들어갈 동료를 찾고 있습니다.
“내가 가진 기술로 세상의 문제를 해결하고 싶다면, 식스티헤르츠에 지원하세요.”
🌟 식스티헤르츠 채용공고 보러가기 (click!)
🌟 이메일 지원: recruit@60hz.io
2025년 12월 29일
Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
: PVlib 벡터라이제이션과 데이터 구조 단순화로 이룬 식스티헤르츠의 스케일업
📂서론 | 15만 개의 발전소, 하나의 계산
식스티헤르츠(60Hertz)는 전국 15만 개 이상의 중소규모 재생에너지 발전소로부터 데이터를 수집하고, 이를 기반으로 발전량을 실시간 예측하는 시스템을 운영합니다. 전력망의 안정성을 지키기 위해, 이 예측값은 빠르고 정확하게 계산되어야 합니다.
대부분의 사람들이 ‘발전량 예측’이라고 하면 머신러닝 모델의 정확도를 떠올립니다. 하지만 예측 대상의 규모가 15만 개 정도 수준이 되면 모델의 정확도 뿐만 아니라 “이 계산을 어떻게 제 시간에 끝낼 것인가”도 중요한 문제가 됩니다. 정확도가 아무리 좋다고 하더라도 문제의 규모가 커졌다고 제시간에 답이 나오지 않는 시스템은 전혀 실용적이지 않겠지요. 이런 측면에서 식스티헤르츠의 기존에 사용하던 시스템(이하 v1)은 하루 발전량 예측 계산에 1시간 이상이 소요되었지만, 다음의 철학을 통해 효율적인 스케일업을 이루어냈습니다.
💡 코드 병렬화보다 중요한 것은, 데이터를 한 번에 계산할 수 있는 단순한 구조로 만드는 것.
v1과 달리, 개선한 시스템(이하 v2)은 데이터를 벡터화하고 구조를 단순화하여 동일한 작업을 단 3~5분 만에 끝냅니다. 본 포스트는 어떻게 식스트헤르츠가 위 성과를 이루어낼 수 있었는지를 데이터 엔지니어링 관점에서 설명하고 있습니다.
📂문제 정의 | 15만 번의 루프, 15만 번의 병목
v1에서의 파이프라인은 Apache Airflow를 기반으로 동작합니다. Airflow란 복잡한 데이터 파이프라인을 스케줄링하고 모니터링하는 워크플로우 관리 플랫폼을 말하며, 이를 이용해 15만 개 발전소들의 발전량 예측 작업을 여러 Task로 나누어 관리해왔습니다.
각 Task는 발전소의 메타 데이터와 기상 데이터를 조합해 python의 태양광 발전 시뮬레이션 라이브러리인 PVlib의 ModelChain API를 반복 호출하는 방식을 통해 이루어집니다. ModelChain은 PVlib에서 제공하고 있는 고수준 API로, 태양광 발전 시스템의 물리적 특성(모듈, 인버터 등)과 기상 데이터를 기반으로 발전량을 계산하는 과정을 캡슐화한 객체입니다. 위 API는 단일 발전소에 대한 시뮬레이션을 쉽게 수행할 수 있도록 설계되었으며, 발전량 예측 과정은 다음과 같이 시각화할 수 있습니다.
먼저 15만개의 발전소들을 10개의 그룹으로 만들어 각 그룹별로 Task가 병렬로 이루어지도록 합니다. 각 그룹 내에서는 1.5만개 발전소를 for-loop로 순회하며 직렬 형태로 ModelChain을 반복호출하게 됩니다. 즉, 병렬처럼 보여도 실상은 루프의 반복이 전체 시간을 지배했습니다. 위 아키텍쳐에서 병목 현상을 유발한 요인은 다음과 같이 정리할 수 있습니다.
계산 과정에서의 병목
데이터 관점에서 병목
데이터 I/O 관점에서 병목
이제 이 각각의 요인들이 어떻게 병목현상을 야기했는지, 그리고 어떻게 기술적으로 해결했는지 하나씩 살펴보도록 하겠습니다.
a. 계산 과정에서의 병목: 고수준 API인 ModelChain 을 변환하다
PVlib은 태양광 발전 시뮬레이션 표준 라이브러리로, 고수준 API(ModelChain)와 저수준 API 두 가지를 제공합니다. 각각의 API는 아래 표와 같이 정리할 수 있습니다.
고수준 API | 저수준 API | |
적용된 시스템 | v1 | v2 |
특징 | 태양광 발전 시스템 전체를 시뮬레이션 하는데 필요한 세부 단계들을 캡슐화하여 | 시뮬레이션의 각 세부 단계들을 구성하는 |
적합한 문제 | 단일 발전소 발전량 예측에 적합 | 대규모 발전소 발전량 예측에 적합 |
PVlib 내 | ModelChain | pvlib.irradiance |
장점 | 사용이 간편하며, 기본적인 시뮬레이션을 | 세밀한 제어가 가능하고, 대규모 데이터 |
단점 | 내부 로직이 숨겨져 있어 세부적인 제어가 | 사용자가 직접 시뮬레이션의 모든 단계를 |
고수준 API인 ModelChain은 단일 발전소 발전량 예측에 적합하지만, 15만개 발전소를 처리할 때는 15만 번의 객체 생성이 필요하여 지속적인 오버헤드를 유발합니다. 고수준 API 기반의 코드 예시는 다음과 같으며, python-level에서의 for loop을 중점적으로 사용하는 것을 확인할 수 있습니다.
results_v1 = [] for plant in plant_meta: mc = pvlib.modelchain.ModelChain(plant.system, plant.location) weather = weather_data_map[plant.id] mc.run_model(weather) results_v1.append(mc.results.ac)
반면 단순한 수학 함수로 구성된 저수준 API는 배열 전체를 한 번에 처리할 수 있어 대규모 데이터 처리에 적합합니다. 아래 코드를 비교해보시면 아시겠지만, python에서의 for-loop문이 완전히 사라진 것을 확인할 수 있습니다. python에서의 for-loop는 다음 단락에서 설명할 벡터화 연산의 이점을 이용할 수 없기 때문에 태생적으로 느릴 수 밖에 없습니다. 1.44억(=15 만개의 발전소 x 96 번)번의 연산이 저수준 API를 통해 벡터라이제이션됨으로써 C-level에서의 벡터화가 적용되어 빠르게 처리됨을 의미합니다.
tilt = plant_meta['tilt'].to_numpy() azimuth = plant_meta['azimuth'].to_numpy() dni = weather_data['dni'].reshape(150000, 96) ghi = weather_data['ghi'].reshape(150000, 96) tilt_b = tilt[:, np.newaxis] azimuth_b = azimuth[:, np.newaxis] total_irrad = pvlib.irradiance.get_total_irradiance( surface_tilt=tilt_b, surface_azimuth=azimuth_b, dni=dni, ghi=ghi ) final_ac_power = pvlib.pvsystem.sapm( effective_irradiance=total_irrad )
b. 데이터 관점에서의 병목: 벡터화를 통한 데이터 처리속도 향상
Pandas와 NumPy는 내부적으로 C언어 수준(이하 C-level)의 벡터 연산을 사용하여 빠른 계산 성능을 제공하며, groupby 역시 이에 최적화된 연산입니다. 하지만 v1에서는 발전소들을 묶는 과정에서 agg(list)를 사용해 데이터를 리스트화했습니다. 이로 인해 메모리상에 동일한 변수형이 연속적으로 배치되어야 하는 NumPy 배열의 구조적 장점이 깨지게 되었습니다. 그 결과 배열 내 값들이 불가피하게 object 타입으로 변환되면서 벡터화의 이 점을 완전히 잃게 되었습니다.
데이터가 벡터화로 구성이 되면 다음의 이유로 성능이 매우 빨라지게 됩니다.
먼저 데이터 형식이 동일하면, SIMD(Single Instruction, Multiple Data) 기술을 활용하여 CPU가 단 한 번의 명령어로 여러 데이터(레지스터 단위)를 동시에 처리하여 물리적인 연산 속도를 획기적으로 높입니다.
또한, Python 인터프리터는 동적 타이핑 언어 특성상, 반복문을 돌 때마다 변수의 타입을 확인하고 적절한 연산 함수를 찾는 과정인 Dispatching을 거칩니다. 반면, 벡터화된 NumPy 배열은 생성 시점에서 동일한 변수형이 보장이 되기 대문에 연산을 시작하기 전에 한 번만 타입을 검사하며, 이후에는 별도의 확인작업 없이 기계어 레벨에서 값을 밀어넣기 때문에 오버헤드가 0에 수렴합니다.
마지막으로 데이터가 메모리에 연속적으로 배치되기 때문에 v1처럼 주소(Pointer)를 따라 여기저기 메모리를 찾아다는 비용인 Dereferencing cost가 줄어들고, CPU 캐시 적중률이 극대화되며, 컴파일러가 자동으로 병렬화 최적화를 수행할 수 있습니다.
다음은 v1에서 사용한 예제 코드입니다.
# v1: C-level 연산을 포기하게 만드는 코드 grouped = df.groupby('plant_id')['ghi'].agg(list) print(grouped.dtype) # dtype('O') → object 타입
C-level에서의 연산은 데이터가 동일한 타입의 데이터가 연속된 메모리 블록에 저장되어 있을 때 가능합니다. 예를 들어, int64 로 구성된 배열은 실제값들이 빈틈없이 붙어있는 형태이며, 첫 번째 값의 주소만 알면 “여기서 부터 1000개의 값을 더해라”와 같은 명령을 단 한 번의 CPU 명령어로 처리할 수 있습니다.
하지만 object 타입으로 구성된 배열은 데이터가 아닌 데이터의 주소를 저장하게 됩니다. 실제 데이터는 메모리 여기저기에 흩어진 상태이며, 각 데이터의 타입도 제각각일 수 있습니다. 이렇게 되면 C-level 연산이 어려워져 속도가 느린 Python 인터프리터가 개입하게 되고, 이로 인해 비효율적인 연산 방식을 수행하게 됩니다.
v1의 경험이 남긴 교훈은 단순했습니다.
복잡한 병렬 처리로 비효율적인 구조를 보완하려 하지 말라. 데이터를 단순하게 만들어라.
이를 기반으로 새로 개선한 v2의 철학은 세 가지였습니다.
루프 제거: Python for 루프를 없앤다.
벡터화: NumPy 브로드캐스팅을 활용한다.
구조 단순화: 중첩 list 대신 2D long-form 구조 사용.
v1이 “15만 개 발전소 객체”를 다뤘다면, v2는 “15만 개의 발전소 정보가 동일한 형태로 줄지어 저장된 tilt, azimuth 배열”을 다룹니다. 데이터 중심의 설계로 전환하면서 코드 구조가 근본적으로 달라지게 된 것입니다.
c. 데이터 I/O 관점에서의 병목: CPU보다 느린 건 데이터였다
저수준 API를 통해 엄청난 속도의 발전을 이루었지만, 데이터 I/O에서의 문제가 남아있었습니다. 기존 v1 방식은 각 발전소 루프마다 필요한 기상예보데이터(NWP; Numerical Weather Prediction)를 개별 Parquet 파일에서 읽어왔습니다. 15만 개의 발전소가 10개의 Task로 나뉘어져 있어도, 각 Task 내에서는 1.5만 번의 파일 접근을 시도하여, 엄청난 I/O 병목을 유발하였습니다. 쉽게 설명하자면 택배로 보낼 물품 1.5만개를 한 대의 오토바이 퀵서비스로 반복적으로 보내고 받는 것과 다르지 않습니다. v2방식은 1) 인덱스 기반 조회와 2) 대량 데이터 전송(예: fetch_df_all()) 방식을 통해 택배차 한 대가 1000개의 택배를 한꺼번에 운송하는 방식과 비슷하게 문제를 해결했습니다.
먼저 모든 NWP 기상 데이터를 Oracle DB에 저장한 뒤, 15만 개 발전소의 위치 인덱스를 활용해 단일 SQL 쿼리에서 필요한 데이터를 한 번에 조회할 수 있도록 구조를 개선했습니다. 이를 통해 쿼리 단위를 통합해 네트워크 왕복 횟수를 최소화하고 I/O 과정에서의 효율을 크게 높였습니다.
또한, execute() 나 executemany() 등의 대용량 데이터 I/O에 적합하지 않은 표준 Python DB-API 방식 대신, Apache Arrow 기반의 python-oracledb DataFrame API를 사용했습니다. 이 방식은 DB에서 읽어온 대량의 데이터를 즉시 NumPy 배열로 변환하여, Python 객체 생성 오버헤드를 건너뛰고 제로카피에 가까운 메모리 효율을 달성합니다. 위 과정을 시각화하면 다음과 같습니다.
📂숫자로 증명된 구조의 힘
위의 세 병목 현상을 해결하여 v2방식은 데이터 로딩 속도만 수십 배 향상시켰고, 이는 전체 파이프라인 처리 시간 단축에 결정적으로 기여했습니다. 데이터 처리 방식을 v1에서 v2로 바꾸면서, 다음의 성능을 달성했습니다.
구분 | 방식 | 처리 시간 | 코드 라인 수 |
|---|---|---|---|
v1 | 발전소별 Python for-loop | 1시간 이상 | ~1200 |
v2 | 벡터 연산에 최적화된 데이터 구조 | 3분 내외 | ~400 |
v2는 24 코어를 모두 활용하며 3분 만에 계산을 완료함으로써 약 20배의 성능 향상을 달성했습니다. 하지만 여기서 더 주목해야 하는 것은 코드 라인의 수입니다. 복잡한 병렬처리, 예외 처리, 데이터 파편화로 가득했던 1,200개 라인의 코드가, 데이터 구조를 단순화하자 400개 라인의 명료한 벡터 연산 코드로 바뀌었습니다. 성능과 유지보수성, 두 마리 토끼를 모두 잡은 것 입니다.
📂이런 문제를 풀고 싶으시다면..
현장에서는 서비스가 어떻게 돌아가는지 뿐만 아니라 얼마나 잘 돌아가는지도 중요합니다. 그리고 상품화의 대상 및 문제 공간이 확대가 되면서 폭넓은 통찰 또한 필요합니다. 이러한 흐름 속에서 식스티헤르츠는,
단순한 데이터 수집이나 ML 모델을 학습시키는 것이 아닌, 문제의 본질을 이해하는 엔지니어를 원합니다.
15만 개의 수준의 거대한 데이터를 다룰 때 어떤 방식이 더 빠르고 효율적인지, 그 근본적인 원리를 이해하고 최적의 구조를 선택할 수 있는 분을 찾습니다.
단순히 데이터를 불러오는 것에 그치지 않고, 어떻게 하면 불필요한 네트워크 왕복 횟수를 최소화하여 전체 시스템의 속도를 높일 수 있을지 치열하게 고민하는 분을 원합니다.
여러 작업을 동시에 처리하는 방식과 거대한 데이터를 한 번에 계산하는 방식의 차이를 명확히 이해하고, 상황에 맞게 적절한 해결책을 제시할 수 있는 분과 함께하고 싶습니다.
우리는 코드가 '돌아가는 것'에 만족하지 않고, '왜 이렇게 돌아가야만 하는지', 그리고 ‘현재보다 더 효율적인 방법은 없는지’를 끊임없이 질문하는 엔지니어와 함께 스케일업의 한계를 넘고 싶습니다.
계산 최적화는 왜 중요할까요?
빠른 계산은 곧 효율적인 서버 운영을 의미하고, 효율적인 서버 운영은 에너지 절약으로 이어집니다. 1시간 걸리던 작업을 3분으로 줄이면, 그 차이인 57분만큼의 서버 리소스를 아낄 수 있습니다. 이것이 바로 고도화된 IT 기술과 정교한 데이터 아키텍처가 곧 탄소 효율로 이어지는 방식입니다.
식스티헤르츠는 '데이터로 에너지를 절약하는 회사'입니다. 이 거대하고 의미 있는 계산에 동참하고 싶다면, 지금 바로 식스티헤르츠의 문을 두드려 주시기 바랍니다.
——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2 (방금 읽은 글이에요)
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 12월 10일
Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
: 온프레미스 대규모 데이터 처리 아키텍처 구축기
저희 팀은 최근 전국 15만 개소 이상의 중소규모 재생에너지 발전소로부터 실시간으로 데이터를 수집하고, 이를 기반으로 발전량을 예측하고 모니터링하는 시스템을 온프레미스(On-premises) 환경에 성공적으로 구축했습니다. 클라우드 환경이 대세인 요즘, 고객사의 보안 정책과 데이터 소유권 문제로 인해 온프레미스 환경에 대규모 시스템을 설계하는 것은 저희에게도 큰 과제였습니다.
해결해야 할 과제들
프로젝트의 목표는 안정성과 확장성 두 가지로 압축되었습니다.
안정적인 데이터 수집
15만 개의 RTU(Remote Terminal Unit)는 LoRa, NB-IoT, HTTPS 등 서로 다른 통신망과 프로토콜을 사용합니다. 이를 단일 시스템으로 통합하여 데이터 유실 없이 수집해야 했습니다.
실시간 처리와 스케일 아웃
수집된 데이터는 즉시 처리되어야 하며, 향후 발전소 증가에 유연하게 대응할 수 있도록 모든 컴포넌트는 수평 확장(Scale-out)이 가능한 구조로 설계되어야 했습니다.
복합 분석 기능
단순 수집을 넘어, 외부 기상 데이터와 결합한 발전량 예측 및 실측치 비교를 통한 이상 감지 기능이 요구되었습니다.
보안 및 고가용성(HA)
외부 공격 방어는 물론, 일부 서버 장애 시에도 서비스 연속성을 보장하는 고가용성 아키텍처가 필수였습니다.
기술 스택 선정 - 왜 이 기술들을 선택했을까?
리액티브 스택을 선택한 이유
대규모 IoT 데이터 처리를 앞두고 가장 먼저 고민한 것은 동시성 처리 방식이었습니다. 전통적인 서블릿 기반의 Spring MVC도 충분히 검증된 기술이지만, 15만 개소에서 동시에 쏟아지는 연결을 처리하기에는 스레드 모델의 한계가 명확해 보였습니다.
그래서 저희는 Spring WebFlux를 선택했습니다. 비동기-논블로킹(Asynchronous Non-blocking) 방식으로 동작하는 WebFlux는 적은 수의 스레드로도 대량의 동시 연결을 처리할 수 있었습니다.
WebFlux를 선택한 결정적인 이유는 세 가지였습니다.
이벤트 루프 방식으로 수만 개의 연결을 동시에 처리할 수 있는 높은 동시성.
Reactor의 Flux/Mono를 통해 데이터 생산자와 소비자 간 속도 차이를 자동으로 조절하는 백프레셔(Backpressure) 지원.
스레드 기반 모델보다 더 적은 리소스로 동작하는 메모리 효율성이었습니다.
Kafka를 통한 이벤트 처리
Apache Kafka를 도입한 것은 이번 프로젝트에서 가장 중요한 아키텍처 결정 중 하나였습니다. 15만 개소에서 동시에 쏟아지는 데이터를 안정적으로 받아내기 위해 Kafka를 선택했습니다.
Kafka는 단순한 메시지 큐 이상의 역할을 담당했습니다. 순간적으로 폭증하는 트래픽을 버퍼링하고, 수집 시스템과 처리 시스템을 분리(Decoupling)함으로써 각 컴포넌트가 독립적으로 확장되고 장애에 대응할 수 있게 해줬습니다.
또한, 토픽 설계는 신중하게 진행했습니다. IoT Platform A, B, C, HTTPS 등 프로토콜별로 토픽을 분리해 각 채널의 특성에 맞게 독립적으로 관리할 수 있도록 했습니다. 각 토픽은 6개의 파티션으로 구성하여 병렬 처리 능력을 확보했고, 복제 계수를 3으로 설정하여 브로커 장애 시에도 데이터를 안전하게 보호했습니다. 메시지는 7일간 보관되도록 설정하여, 만약의 장애 상황에서도 충분한 복구 시간을 확보했습니다.
아키텍처 설계 - 데이터는 어떻게 흐르는가?
기술 스택을 정했으니, 이제 이것들을 어떻게 조합할 것인지 고민할 차례였습니다. 저희는 데이터의 흐름을 따라 시스템을 크게 4개 영역으로 나누어 설계했습니다.
1. 데이터 수집 영역
전국 각지에 흩어진 발전소의 RTU 장비에서 보낸 데이터가 시스템으로 유입되는 진입점입니다. 방화벽과 L4 스위치를 거쳐 수집 서버로 전달된 데이터는, 여기서 프로토콜별로 정제되어 Kafka로 발행됩니다.
Data Collector
Spring WebFlux 기반의 비동기 서버로, 다양한 IoT 프로토콜을 표준화된 내부 포맷으로 변환합니다.
reactor-kafka를 사용하여 논블로킹 메시지 발행을 구현했으며, Reactor의 백프레셔 기능을 통해 Kafka 클러스터로 가는 부하를 조절합니다. 컨테이너 기반으로 설계되어 트래픽 증가 시 즉각적인 확장이 가능합니다.
2계층 로드밸런싱: L4 스위치와 Nginx, Docker
클라우드의 관리형 로드밸런서가 없는 온프레미스 환경에서 고가용성과 확장성을 확보하기 위해, 하드웨어 L4 스위치와 소프트웨어 로드밸런서를 계층화하여 유연한 트래픽 분산을 구현했습니다. 외부에서 들어오는 트래픽은 먼저 L4 스위치가 여러 대의 서버로 분산하고, 각 서버 내부에서는 Nginx가 Docker 컨테이너로 패키징된 수집 서버 인스턴스들에게 요청을 분배합니다.
하드웨어 스위치가 네트워크 레벨의 빠른 분산과 헬스체크를 담당하고, Nginx가 애플리케이션 레벨의 세밀한 라우팅을 담당하는 역할 분리가 핵심입니다.
Nginx는 Least Connections 방식으로 현재 활성 연결 수가 가장 적은 인스턴스에 요청을 전달하며, Passive Health Check를 통해 실패한 인스턴스를 자동으로 제외합니다.
upstream collector_api_server1 { least_conn; server collector-api-1:8081 max_fails=3 fail_timeout=30s; server collector-api-2:8081 max_fails=3 fail_timeout
Nginx 설정은 코드로 관리되어 버전 관리가 가능하고, 컨테이너 스케일 아웃 시 설정만 변경하면 됩니다. 이 패턴은 WEB/WAS 서버에도 동일하게 적용했습니다.
2. 이벤트 허브 영역
Kafka 토픽 설계는 단순해 보이지만, 실제로는 많은 고민이 필요한 부분입니다. 저희는 프로토콜별로 토픽을 분리하여 각 채널이 서로 영향을 주지 않도록 격리성을 확보하면서도, 파티셔닝을 통해 확장성도 함께 확보했습니다.
토픽 네이밍은 일관된 컨벤션을 따랐습니다. {namespace}.collector.{platform}.raw-data 형태로 명명하고, Event Contracts 모듈에서 모든 토픽 이름을 상수로 중앙 관리했습니다.
파티셔닝 전략도 중요했습니다. 각 토픽을 6개 파티션으로 나누어 컨슈머가 병렬로 처리할 수 있도록 했습니다. 파티션 리밸런싱 기능 덕분에 컨슈머가 추가되거나 제거될 때도 부하가 자동으로 재분배됩니다.
3. 데이터 중계 및 저장 영역
Kafka에 쌓인 데이터를 이제 안전하게 내부망의 데이터베이스로 옮겨야 합니다. 보안을 위해 DMZ에 중계 서버를 두고, 여기서 Kafka 메시지를 소비해 내부망 DB에 저장하는 구조로 설계했습니다.
컨슈머 처리 로직
컨슈머 모듈은 Kafka 메시지를 소비하여 DB에 저장하는 역할을 합니다. 가장 먼저 집중한 부분은 배치 처리 최적화였습니다. 메시지를 개별적으로 처리하지 않고 배치(Batch) 단위로 묶어서 DB에 저장하도록 했는데, 최대 1,000개 메시지를 한 번에 가져오며 최소 1MB 데이터가 모이거나 3초가 경과하면 배치 처리를 수행합니다. 이 방식으로 DB Insert 성능을 크게 향상시킬 수 있었습니다.
처리량을 극대화하기 위해 컨슈머 그룹도 적극 활용했습니다. 6개의 파티션을 6개의 컨슈머가 병렬로 소비하며, 각 컨슈머는 독립적으로 메시지를 처리합니다.
안정성을 위한 재시도 및 에러 핸들링도 중요했습니다. 일시적인 오류 시에는 1초 간격으로 최대 3번 재시도하며, 배치 저장 실패 시에는 개별 저장으로 fallback하여 가능한 많은 데이터를 보존하도록 했습니다. 그래도 실패하는 데이터는 별도의 오류 테이블에 저장하여 추후 분석할 수 있도록 했습니다.
4. 발전량 예측 및 분석 영역
단순히 데이터를 쌓는 것만으로는 가치를 만들기 어렵습니다. 분석 예측 서버는 수집된 데이터를 분석하고 예측하는 역할을 합니다.
분석 예측 서버는 Dagster 기반 워크플로우 오케스트레이션을 사용합니다. Dagster를 활용해 데이터 파이프라인의 스케줄링과 실행을 관리하며, 데이터 수집, 전처리, 예측 실행을 하나의 워크플로우로 통합했습니다. 파이프라인 실행 이력과 의존성도 체계적으로 관리했습니다.
예측 정확도를 높이기 위해서는 외부 데이터 연동이 필수적이었습니다. Python 분석 파이프라인이 NOAA NWP(수치예보모델)를 통해 기상 예보 데이터를 수집하며, 태양광 발전에 영향을 미치는 기상 요소를 확보했습니다. 발전량 예측 모델은 과거 발전 실적 데이터와 기상 데이터를 결합하여 미래 발전량을 예측하고, 그 결과는 데이터베이스에 저장되어 분석 및 리포팅에 활용됩니다.
5. 웹 서비스 제공 영역
사용자들이 발전소 상태를 모니터링하고 시스템을 제어하는 웹 서비스 영역입니다.
웹 서비스는 전형적인 3-Tier 아키텍처로 구성했습니다. 가장 앞단의 WEB 계층에서는 정적 리소스 서빙과 SSL/TLS 터미네이션을 담당하며, L4 스위치를 통해 2대의 서버로 로드 밸런싱합니다. 들어온 요청은 WAS 서버로 프록시됩니다.
WAS 계층은 3대의 Application Server로 구성되어 고가용성을 확보했습니다. 여기서 동작하는 Business API Service는 Spring Boot 기반의 RESTful API 서버로, 모니터링 서비스의 핵심 비즈니스 로직을 처리합니다. 무중단 서비스는 필수 요구사항이었습니다. Oracle RAC Active-Active 클러스터로 DB를 이중화하고, 모든 계층에서 최소 2대 이상의 서버를 운영하며 L4 로드 밸런싱을 구성했습니다. Docker 기반 구성 덕분에 장애 발생 시에도 빠르게 복구할 수 있습니다.
배치 계층은 Spring Batch를 활용해 정기적인 통계 집계와 리포트 생성 같은 대용량 데이터 처리 작업을 수행합니다.
수집 서버 클러스터 성능 검증: 12,000 TPS 달성
아키텍처 설계가 실제 대규모 트래픽 환경에서 유효한지 검증하기 위해 강도 높은 부하 테스트를 수행했습니다. 단순 산술 계산으로 접근하면 15만 개의 장비가 60초 동안 균등하게 데이터를 전송한다고 가정했을 때, 필요한 처리량은 약 2,500 TPS입니다.
150,000 Requests / 60 Seconds = 2,500 TPS
하지만 실제 환경에서는 장비들이 완벽하게 분산되지 않습니다. 많은 설비들이 동시에 데이터를 전송하는 트래픽 스파이크가 빈번하게 발생하기 때문입니다. 클라이언트 측에 지연 로직이 없다면 서버는 순간적으로 10,000 TPS 이상의 폭주 트래픽을 감당해야 할 수도 있습니다. 저희는 이러한 트래픽 서지(Surge)를 고려하여, 평균 대비 약 4~5배의 예비 용량을 확보하는 것을 목표로 삼았습니다.
Grafana k6를 이용한 부하 테스트 결과 단일 노드 기준 초당 3,000건의 수집 요청(3,000 TPS), 전체 클러스터 기준 초당 12,000건(12,000 TPS)의 수집 요청을 지연 없이 안정적으로 처리하는 것을 확인했습니다. Spring WebFlux의 Non-blocking 구조와 Kafka를 통한 트래픽 버퍼링, 그리고 컨슈머의 Batch Insert 전략이 유기적으로 동작하여, 이론적 피크치를 상회하는 부하 상황에서도 데이터 유실 없이 안정적인 처리가 가능함을 증명했습니다.
회고 - 우리가 배운 것들
비동기-논블로킹의 이점
Spring WebFlux를 실전에 적용하면서 대규모 IoT 환경에서 리액티브 프로그래밍의 장점을 확인할 수 있었습니다. 적은 리소스로 높은 처리량을 달성하는 것은 물론, 백프레셔 제어를 통해 시스템 전체의 안정성을 확보할 수 있었습니다.
Kafka는 단순한 메시지 큐가 아니다
Kafka를 도입하면서 이벤트 스트리밍 플랫폼의 진가를 알게 되었습니다. 단순히 메시지를 전달하는 것을 넘어, 시스템 간 결합도를 낮추고 장애 격리를 가능하게 하며, 데이터를 일정 기간 보관해 재처리를 가능하게 하는 등 아키텍처 전반의 안정성을 높이는 중요한 컴포넌트였습니다.
확장성은 처음부터 고려해야 한다
수평 확장이 가능한 구조로 설계한 덕분에, 트래픽이 증가해도 서버를 추가하는 것만으로 대응할 수 있었습니다. 컨테이너 기반 아키텍처와 Kafka의 파티셔닝 메커니즘이 이를 가능하게 했습니다.
온프레미스에서도 유연한 인프라 구성이 가능하다
클라우드 없이도 L4 스위치와 Nginx를 계층화하여 충분히 유연한 로드밸런싱을 구현할 수 있었습니다. 중요한 것은 각 계층의 역할을 명확히 분리하고, 설정을 코드로 관리하는 것이었습니다.
마무리하며
온프레미스 환경에서 15만 개소의 실시간 데이터를 처리하는 시스템을 구축하는 여정은 쉽지 않았습니다. 클라우드 매니지드 서비스가 제공하는 편리함 대신, 하드웨어 선정부터 네트워크 망 분리, 각 서버의 역할 정의와 이중화 구성까지 모든 단계를 저희 손으로 직접 결정하고 구축해야 했습니다.
하지만 그만큼 배운 것도 많았습니다. 대규모 트래픽을 안정적으로 처리하기 위한 Spring WebFlux와 Kafka의 활용, 그리고 Nginx와 Docker를 활용한 소프트웨어 로드밸런싱을 통해 유연한 아키텍처를 구성해 본 것은 저희 팀의 큰 자산으로 남게 되었습니다.
이 글이 온프레미스 환경에서 대규모 트래픽 처리를 고민하는 엔지니어분들에게 작은 도움이 되기를 바랍니다.
——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1 (방금 읽은 글이에요)
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 12월 3일
Tech
단일책임원칙(SRP)을 충족하는 React 개발
혹시 SOLID 원칙에 대해 들어보셨나요?
개발을 접하신 분이라면 자세히는 몰라도 한 번쯤 이름은 들어보셨을 거예요.
SOLID 원칙은 객체지향 설계에서 지켜야 할 다섯 가지 소프트웨어 개발 원칙(SRP, OCP, LSP, ISP, DIP)을 말합니다.
SRP (Single Responsibility Principle): 단일 책임 원칙
OCP (Open Closed Principle): 개방 폐쇄 원칙
LSP (Liskov Substitution Principle): 리스코프 치환 원칙
ISP (Interface Segregation Principle): 인터페이스 분리 원칙
DIP (Dependency Inversion Principle): 의존 역전 원칙
이런 원칙들을 지키면 좋은 객체지향 설계에 가까워질 수 있습니다.
그런데 프론트엔드 개발자, 특히 React를 사용하는 분들이라면 이런 생각이 들 수도 있습니다.
“객체지향 원칙을 함수 기반 React에 어떻게 적용하지?”
식스티헤르츠는 관리자 도구, 대시보드, 사용자 웹 서비스 등 다양한 영역에서 React를 활용하고 있습니다.
React는 빠르고 선언적인 개발을 가능하게 하지만, 동시에 SOLID 같은 설계 원칙을 놓치기 쉬운 환경이기도 합니다.특히 일정에 쫓기다 보면 "일단 되게 만들고 나중에 리팩토링하자"는 생각으로 컴포넌트 하나에 API 호출, 상태 관리, 비즈니스 로직, UI 렌더링을 모두 집어넣게 됩니다. 당장은 빠르게 느껴지지만, 시간이 지나면 그 '나중'은 오지 않고 코드는 점점 더 복잡해집니다. 결국 새로운 기능을 추가할 때마다 기존 코드를 건드리기 두려워지고, 수정 대신 코드를 추가하는 방식으로 문제를 회피하게 되죠.
사실 저는 주니어 개발자 시절부터 꽤 오랫동안 설계 원칙에 갇혀 있었습니다. 하나의 원칙을 프로젝트에 적용하면 그것을 엄격하게 지키려고만 했지, '왜 지켜야 하는가'에 대해서는 제대로 생각하지 못했어요. 그러다 보니 오히려 원칙을 지키는 게 불편해지고, 어느 순간부터는 원칙을 의도적으로 멀리하게 됐습니다. 코드를 작성하는 데 불편하고 시간도 오래 걸렸거든요. 막상 코드를 작성하고 나면 그렇게 마음에 들지도 않았어요.
하지만 원칙을 멀리한 채 개발하다 보니, 오히려 다시 원칙을 찾게 되는 상황들이 생겼습니다. 왜일까요? 개발 원칙에는 좋은 소프트웨어를 만들기 위한 개발 철학이 담겨있기 때문입니다. 나보다 먼저 이 길을 걸은 개발자들의 고민과 해결 방법들이 개발 원칙으로 만들어진 것이죠. 구체적인 지침 자체는 내 상황에 맞지 않을 수 있어도, 그 지침이 만들어지기까지의 철학은 어떤 소프트웨어 개발에도 유효할 수 있습니다. 한 발 물러서서 개발 원칙을 바라보니, 필요한 시점에 필요한 철학을 적절히 적용할 수 있게 되었습니다.이 글에서는 그런 문제의식에서 출발해, SOLID의 첫 번째 원칙인 SRP(단일 책임 원칙)를 React 코드에 어떻게 적용할 수 있는지 살펴보려 합니다
단일 책임 원칙의 철학
단일 책임 원칙(SRP)의 핵심은 간단합니다. "하나의 모듈(클래스, 함수, 컴포넌트)은 하나의 책임만 가져야 한다." 여기서 '책임'이란 '변경의 이유'를 의미합니다. 로버트 C. 마틴은 이를 "하나의 모듈은 하나의, 오직 하나의 액터(사용자)에 대해서만 책임져야 한다"고 표현했습니다.
왜 이게 중요할까요? 여러 책임이 하나의 모듈에 섞여 있으면, 한 가지를 수정할 때 다른 것까지 영향을 받게 됩니다. 책임이 명확하게 분리되어 있으면 변경의 파급 효과를 최소화할 수 있고, 코드를 이해하고 테스트하기도 훨씬 쉬워집니다.
실생활에서의 단일 책임 원칙
우리가 개발 과정을 설명할 때 자동차를 예시로 자주 사용합니다. 자동차는 각 책임 단위인 부품으로 잘 분리되어 있습니다. 에어컨이 고장나면 에어컨만 수리하면 되고, 브레이크가 고장나면 브레이크만 교체하면 됩니다. 각 부품에 문제가 생겼을 때 해당 부품만 손보면 되는 구조죠.
그렇다면 단일 책임 원칙을 지키지 못해 에어컨, 브레이크, 엔진이 하나의 통합 모듈로 결합되어 있다면 어떻게 될까요? 에어컨 필터만 교체하려 해도 전체 모듈을 분해해야 합니다. 작업 중 실수로 브레이크 라인을 건드려 브레이크액이 샐 수도 있고, 엔진 배선을 잘못 만져 시동이 걸리지 않을 수도 있습니다. 단순한 에어컨 필터 교체가 브레이크나 엔진 같은 핵심 기능에 문제를 일으킬 위험이 생기는 거죠. 당연히 수리 시간도 길어지고, 비용도 훨씬 비싸집니다.
여기에 에어컨 부품이 개선되어 새로운 에어컨 부품이 개발되었다고 해볼까요? 별도 모듈로 사용하고 있다면 브레이크와 엔진은 기존 부품을 그대로 사용하면 되는데, 모듈이 결합되어 있기 때문에 새 에어컨 부품을 사용하기 위해서는 새 에어컨, 브레이크, 엔진이 결합된 새로운 모듈을 만들어 사용해야 합니다. 기존 모듈은 더이상 사용할 수 없어지겠죠.
소프트웨어 개발도 마찬가지입니다. 단일 책임 원칙을 지키지 못한다면 동일한 문제가 발생합니다.
작은 수정에도 큰 비용이 발생합니다 (유지보수 비용 증가)
코드 수정 중 예상치 못한 사이드 이펙트가 발생합니다
수정이 두려워 코드를 수정하기보다는 코드를 추가하게 되고, 코드가 점점 복잡해집니다
코드 재사용이 어려워집니다. (여러 책임이 얽혀있기 때문에)
결국 단일 책임 원칙은 유지보수 비용을 줄이면서, 자연스럽게 재사용성도 높여주는 중요한 원칙입니다. React에서는 컴포넌트 재사용 빈도가 높기 때문에 단일 책임 원칙을 지키면 재사용성 측면에서 큰 이점을 만들어낼 수 있습니다.
React 개발에서 SOLID 원칙을 놓치기 쉬운 이유
식스티헤르츠는 React를 주로 관리자 도구와 대시보드, 그리고 사용자 대면 웹 서비스 개발에 사용하고 있습니다. 개발 업무 중 웹 개발이 차지하는 비중이 많기 때문에 javascript를 적극적으로 활용하게 되고, 속도와 유지보수성을 모두 살리기 위해 선언적 개발을 가능하게 만들어주는 React를 주로 활용하고 있습니다. 여러 상황에서 React는 훌륭한 선택이지만, 동시에 SOLID 원칙 같은 설계 원칙을 간과하게 만드는 특성도 가지고 있습니다.
JavaScript와 React는 강력한 자유도를 제공합니다. 함수 안에서 무엇이든 할 수 있으며, 컴포넌트 하나에 로직과 UI를 모두 담을 수 있습니다. 이런 자유로움 덕분에 빠르게 기능을 구현할 수 있지만, 역설적으로 '잘못된 설계'도 쉽게 만들어집니다. Java나 C# 같은 언어에서는 클래스 구조와 타입 시스템이 어느 정도 설계를 강제하지만, React에서는 모든 것이 '함수'이기 때문에 책임의 경계가 흐려지기 쉽습니다.
특히 일정에 쫓기다 보면 "일단 되게 만들고 나중에 리팩토링하자"는 생각으로 컴포넌트 하나에 API 호출, 상태 관리, 비즈니스 로직, UI 렌더링을 모두 집어넣게 됩니다. 당장은 빠르게 느껴지지만, 시간이 지나면 그 '나중'은 오지 않고 코드는 점점 더 복잡해집니다. 결국 새로운 기능을 추가할 때마다 기존 코드를 건드리기 두려워지고, 수정 대신 코드를 추가하는 방식으로 문제를 회피하게 되죠.
React 개발에서 '책임'이란?
React 개발은 결국 함수 개발이라고 할 수 있습니다. 비즈니스 로직은 말할 것도 없이 함수로 개발하고 UI조차도 함수로 개발하는 특징을 갖고 있죠. 그리고 함수가 하는 일이 곧 책임입니다. 그래서 React에서의 책임은 ‘함수가 어떤 비즈니스 로직을 수행하는가' 뿐만 아니라 ‘어떤 UI를 어떻게 그려내는가’를 포함한다고 할 수 있습니다.
React에서 단일 책임 원칙 지키기
1. 비즈니스 로직과 UI 분리
가장 먼저 책임을 분리할 수 있는 지점은 비즈니스 로직과 UI를 분리하는 것입니다. React는 비즈니스 로직과 UI를 모두 함수로 표현하기에 이를 합쳐서 사용하게 되는 경우가 많습니다.
// 책임이 섞여있는 컴포넌트 function MyProfile() { const [myInfo, setMyInfo] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/me') .then(res => res.json()) .then(data => setMyInfo(data)) .finally(() => setLoading(false)); }, []); if (loading) return <Spinner />; return ( <div className="profile"> <img src={myInfo?.avatar} /> <h1>{myInfo?.name}</h1> <p>{myInfo?.email}</p> </div> ); }
간단하게 예를 들어 위와 같은 `MyProfile` 컴포넌트가 있다고 해보겠습니다. 언뜻 보기에는 내 정보를 화면에 보여주는 단일 책임 컴포넌트처럼 오해하기 쉽습니다. 하지만 이 컴포넌트는 '내 정보를 호출하는 로직'과 '프로필 UI 렌더링 로직' 두 가지가 강하게 결합되어 있습니다.
이렇게 되면 어떤 문제가 발생할까요?
가장 먼저 발생하는 문제는 재사용이 어려워진다는 것입니다. 동일한 UI를 사용하는 화면이 있는데 내 정보가 아니라 다른 사용자의 프로필을 보여줘야 한다고 가정해볼까요? 현재 `MyProfile` 은 내 정보를 화면에 그려주는 역할을 하기 때문에 이 코드를 재사용할 수 없습니다. 그럼 아래와 같은 컴포넌트를 새로 만들어야 할 겁니다.
function UserProfile({ userId }) { const [user, setUser] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch(`/api/user/${userId}`) .then(res => res.json()) .then(data => setUser(data)) .finally(() => setLoading(false)); }, [userId]); if (loading) return <Spinner />; return ( <div className="profile"> <img src={user?.avatar} /> <h1>{user?.name}</h1> <p>{user?.email}</p> </div> ); }
컴포넌트를 분석해보니 '유저 정보를 호출하는 로직'과 '프로필 UI 렌더링 로직'이 결합되어 있네요. 뭔가 이상함을 느끼셨나요? 같은 '프로필 UI 렌더링' 책임이 두 컴포넌트에 중복되어 존재합니다. 단지 두 개가 아닙니다. 앞으로 동일한 UI를 사용할 때마다 매번 새로운 컴포넌트를 만들어야 하고, 앞으로 몇 개가 더 생성될지 모릅니다.
이는 결국 유지보수의 문제로 이어집니다. "프로필 UI에서 email이 없으면 '-'를 보여주세요" 같은 간단한 수정에도 수많은 컴포넌트들을 일일이 찾아서 수정해야 하고, 누락되는 부분이 생길 가능성이 큽니다.
반대로 다른 컴포넌트에서 유저정보를 가져다 사용하는 것 처럼 비즈니스 로직이 재사용되는 경우에도 매번 동일한 코드를 작성해줘야 하겠죠.
이처럼 비즈니스 로직과 UI의 결합은 언뜻 보면 자연스러워 보여도 실제로는 서로 다른 책임의 결합으로 이루어져 있음을 이해해야 합니다.
그럼 어떻게 수정하면 좋을까요? 처음 이야기했던 대로 비즈니스 로직과 UI를 분리하면 됩니다. 비즈니스 로직은 Custom Hook으로, UI는 별도 컴포넌트로 분리해보겠습니다.
// 내 정보를 가져오는 책임 담당 function useMyInfo() { const [myInfo, setMyInfo] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/me') .then(res => res.json()) .then(data => setMyInfo(data)) .finally(() => setLoading(false)); }, []); return { myInfo, loading }; } // 유저 정보를 가져오는 책임 담당 function useUser(userId) { const [user, setUser] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { if (!userId) return; setLoading(true); fetch(`/api/user/${userId}`) .then(res => res.json()) .then(data => setUser(data)) .finally(() => setLoading(false)); }, [userId]); return { user, loading }; } // UI를 렌더링하는 책임 담당 function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile"> <img src={avatar} alt={name} /> <h1>{name}</h1> <p>{email || "-"}</p> // 수정사항 반영 </div> ); }
이제 책임을 나누었으니 완성된 함수를 사용해보겠습니다.
function MyProfile(){ const { myInfo, loading } = useMyInfo(); return ( <ProfileCard loading={loading} avatar={myInfo?.avatar} name={myInfo?.name} email={myInfo?.email} /> ) } function UserProfile({ userId }){ const { user, loading } = useUser(userId); return ( <ProfileCard loading={loading} avatar={user?.avatar} name={user?.name} email={user?.email} /> ) } // 다른곳에서 비즈니스 로직 재사용 function Header(){ const { myInfo, loading } = useMyInfo(); return <UserSummary userLevel={myInfo?.level} name={myInfo?.name} /> }
어떠신가요? 이제 ProfileCard는 UI의 변경에만 대응하면 되는 단일 책임을 가진 컴포넌트가 되었습니다. 이렇게 비즈니스 로직과 UI를 분리하게 되면 여러 가지 장점이 따라옵니다.
재사용성 향상
ProfileCard는 어디서든 사용 가능합니다.
새로운 페이지에서 프로필을 보여줘야 한다면? ProfileCard 만 재사용하면 됩니다.
내 정보를 가져오는 비즈니스 로직이 필요하면 UseMyInfo 를 재사용하면 됩니다.
유지보수 용이
UseMyInfo, UseUser : "데이터를 어떻게 가져올 것인가"에 대한 책임
ProfileCard : "프로필을 어떻게 보여줄 것인가"에 대한 책임
MyProfile, UserProfile : "어떤 데이터를 어떤 UI로 조합할 것인가"에 대한 책임
각 모듈이 하나의 명확한 책임만 가지고 있어서, 변경의 이유도 하나씩만 가집니다. 유지보수 시점에 어떤 책임을 수정할지 확인하고 수정하면 됩니다.
병렬 개발이 가능하다
API 서버 개발이 늦어지는 상황에서도 UI를 완성할 수 있고, 추후 비즈니스 로직 작성이 UI 컴포넌트를 수정하지 않습니다.
반대로 디자인이 늦어지는 상황에서도 비즈니스 로직을 먼저 작성할 수 있습니다.
각각의 책임을 쉽게 테스트할 수 있다.
// Hook 테스트 test('useMyInfo는 내 정보를 가져온다', async () => { const { result } = renderHook(() => useMyInfo()); await waitFor(() => { expect(result.current.myInfo).toBeDefined(); }); }); // UI 테스트 (혹은 스토리북 테스트) test('ProfileCard는 사용자 정보를 표시한다', () => { render(<ProfileCard avatar="/avatar.png" name="홍길동" email="hong@example.com" />); expect(screen.getByText('홍길동')).toBeInTheDocument(); });
2. UI 세분화
비즈니스 로직을 분리했다면, 이제 UI 자체도 더 작은 책임으로 나눌 수 있습니다. 앞서 만든 ProfileCard 를 다시 살펴볼까요?
function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile"> <img src={avatar} alt={name} /> <h1>{name}</h1> <p>{email || '-'}</p> </div> ); }
이 컴포넌트는 '프로필 카드를 렌더링한다'는 하나의 책임을 가진 것처럼 보입니다. 실제로 어떤 상황에서는 하나의 책임이 맞을 수 있습니다. 하지만 조금 더 들여다보면 상황에 따라 여러 UI 요소들이 섞여 있다고 할 수 있습니다.
아바타 이미지 표시
사용자 이름 표시
이메일 표시
전체 레이아웃 구성
만약 다음과 같은 요구사항이 생긴다면 어떨까요?
"댓글 섹션에서도 사용자 아바타와 이름을 보여주세요"
"헤더에 아바타만 동그랗게 표시해주세요"
"사용자 정보 편집 폼에서 이메일 입력란 스타일을 프로필과 동일하게 해주세요"
현재 구조에서는 이런 작은 UI 요소들을 재사용하기 어렵습니다. 책임을 분리한 순간 ProfileCard 에 이미 여러 책임들이 섞여있기 때문이죠. 그래서 ProfileCard 에서 코드를 복사해와서 사용하거나 새로 작성해야 할 겁니다. 이는 디자인팀도 Figma를 사용해 디자인 요소를 컴포넌트화하는 현재 시점에서, 비즈니스 로직과 UI의 결합과 마찬가지로 유지보수 문제를 발생시킬 수 있습니다.
UI 컴포넌트도 비즈니스 로직처럼 작은 책임 단위로 나눌 수 있습니다. ProfileCard 를 실제로 책임 단위로 쪼개보겠습니다.
// 아바타 이미지 표시 책임 function Avatar({ src, alt, size = 'medium' }) { const sizeClasses = { small: 'w-8 h-8', medium: 'w-16 h-16', large: 'w-24 h-24' }; return ( <img src={src} alt={alt} className={`rounded-full ${sizeClasses[size]}`} /> ); } // 사용자 이름/이메일 표시 책임 function UserInfo({ name, email }) { return ( <div className="user-info"> <h3 className="text-xl font-semibold">{name}</h3> <p className="text-sm text-gray-600">{email || '-'}</p> </div> ); } // 프로필 카드 레이아웃 구성 책임 function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile-card"> <Avatar src={avatar} alt={name} size="large" /> <UserInfo name={name} email={email} /> </div> ); }
이제 각 요소를 독립적으로 재사용할 수 있습니다.
// 댓글 섹션 - 작은 아바타와 이름만 function Comment({ author, content }) { return ( <div className="comment"> <Avatar src={author.avatar} alt={author.name} size="small" /> <div> <h4>{author.name}</h4> <p>{content}</p> </div> </div> ); } // 헤더 - 아바타만 function Header() { const { myInfo } = useMyInfo(); return ( <header> <Logo /> <Avatar src={myInfo?.avatar} alt={myInfo?.name} size="small" /> </header> ); } // 사용자 목록 - 아바타와 정보를 함께 function UserListItem({ user }) { return ( <li className="flex items-center gap-3"> <Avatar src={user.avatar} alt={user.name} size="medium" /> <UserInfo name={user.name} email={user.email} /> </li> ); }
이렇게 UI 로직도 책임 단위로 분리하게 되면 재사용성과 유지보수성을 더 좋게 만들 수 있습니다. 이렇게 UI 요소를 책임 단위로 분리하는 대표적인 패턴이 Atomic Design Pattern입니다.
주의해야 할 점은 반드시 모든 UI를 작은 컴포넌트 단위로 쪼갤 필요는 없다는 것입니다. 책임의 단위는 각 회사마다 다르고, 개발자마다 느끼는 책임의 범위도 다릅니다. 중요한 것은 실제로 재사용되는 단위, 독립적으로 변경되는 단위를 기준으로 적합한 책임의 단위를 찾아내고 관리하는 것입니다. 모든 요소를 강박적으로 쪼갤 필요는 없습니다.
3. 비즈니스 로직 세분화
비즈니스 로직과 UI를 분리했다고 해서 끝이 아닙니다. 비즈니스 로직 자체도 여러 책임으로 나눌 수 있습니다. Custom Hook 안에서도 여러 가지 일을 한꺼번에 처리하고 있다면, 그것 역시 단일 책임 원칙을 위반하는 것입니다.
예를 들어 장바구니 기능을 개발한다고 가정해봅시다.
// 여러 책임이 섞여있는 Hook function useCart() { const [items, setItems] = useState([]); const [loading, setLoading] = useState(false); // 장바구니 데이터 조회 useEffect(() => { setLoading(true); fetch('/api/cart') .then(res => res.json()) .then(data => setItems(data)) .finally(() => setLoading(false)); }, []); // 가격 계산 const totalPrice = items.reduce((sum, item) => sum + item.price * item.quantity, 0); const discount = totalPrice >= 50000 ? totalPrice * 0.1 : 0; const shippingFee = totalPrice >= 30000 ? 0 : 3000; const finalPrice = totalPrice - discount + shippingFee; // 상품 추가/삭제 const addItem = (product) => setItems(prev => [...prev, product]); const removeItem = (id) => setItems(prev => prev.filter(item => item.id !== id)); return { items, loading, totalPrice, discount, finalPrice, addItem, removeItem };
이 Hook은 다음과 같은 여러 책임을 가지고 있습니다
장바구니 데이터 가져오기
가격 계산 (총액, 할인, 배송비)
장바구니 아이템 관리
이렇게 되면 어떤 문제가 발생할까요?
주문 페이지에서 가격 계산만 필요한데, useCart 를 사용하면 불필요한 장바구니 데이터 fetching까지 실행됩니다
가격을 계산하는 코드는 외부 의존성이 없는 순수 함수 성격의 코드인데, 이를 테스트하기 위해서는 API mocking까지 해야합니다.
그럼 어떻게 책임단위로 분리할 수 있을까요?
// 가격 계산 로직만 담당 function calculatePrice(items) { const totalPrice = items.reduce((sum, item) => sum + item.price * item.quantity, 0); const discount = totalPrice >= 50000 ? totalPrice * 0.1 : 0; const shippingFee = totalPrice >= 30000 ? 0 : 3000; const finalPrice = totalPrice - discount + shippingFee; return { totalPrice, discount, shippingFee, finalPrice }; } // 장바구니 데이터 조회만 담당 function useCartData() { const [items, setItems] = useState([]); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/cart') .then(res => res.json()) .then(data => setItems(data)) .finally(() => setLoading(false)); }, []); return { items, setItems, loading }; } // 필요한 것들을 조합 function useCart() { const { items, setItems, loading } = useCartData(); const priceInfo = calculatePrice(items); const addItem = (product) => setItems(prev => [...prev, product]); const removeItem = (id) => setItems(prev => prev.filter(item => item.id !== id)); return { items, loading, ...priceInfo, addItem, removeItem }; }
로직을 분리하면 이제 필요한 곳에서 조립해 사용할 수도 있고, 각 모듈을 독립적으로 재사용 할 수도 있습니다. 테스트하기도 훨씬 수월해졌죠.
// 주문 페이지 - 가격 계산만 재사용 function OrderSummary({ orderItems }) { const { totalPrice, discount, finalPrice } = calculatePrice(orderItems); return ( <div> <p>총 금액: {totalPrice}원</p> <p>할인: -{discount}원</p> <p>최종 금액: {finalPrice}원</p> </div> ); } // 장바구니 페이지 - 전체 기능 사용 function CartPage() { const { items, finalPrice, addItem, removeItem } = useCart(); // ... } // 가격 계산 테스트 test('5만원 이상 구매시 10% 할인이 적용된다', () => { const items = [{ price: 50000, quantity: 1 }]; const result = calculatePrice(items); expect(result.discount).toBe(5000); });
이렇게 비즈니스 로직을 적당한 책임 단위로 분리해 재사용성을 높이고 유지보수를 용이하게 만들었습니다. 비즈니스 로직도 UI 로직과 마찬가지로 억지로 작은 단위로 분리하려고 힘쓸 필요는 없습니다. 우선 적당한 책임 단위로 만들고, 책임 분리가 필요한 시점에 분리해도 괜찮습니다. 가장 중요한건 분리가 필요하다고 느끼는 시점에는 반드시 분리를 해 주는 것이라고 생각합니다.
마치며
간단하게 단일 책임 원칙이 React에 어떤식으로 적용될 수 있는지 살펴봤습니다. 사실 위에 적은 이점 외에도 책임을 분리하면 좋은 점이 하나 더 있다고 생각합니다. 바로 AI에게 일을 맡길 때 굉장히 좋은 결과물로 나올 때가 많다는 것입니다. 이것저것 여러 책임을 부여한 컴포넌트를 AI에 만들어달라고 했을 때와 책임단위로 일을 분리한 뒤 한 개씩 AI에 만들어달라고 했을 때, 후자가 훨씬 더 좋은 결과물을 만들어 낼 때가 많았습니다. AI 생성물을 관리하는 입장에서도 후자가 훨씬 유리하겠죠.
단일 책임 원칙은 객체지향의 전유물이 아닙니다. SOLID 원칙도 그렇고 다른 개발원칙도 그렇습니다. React 개발에서도, 아니 어떤 개발에서도 적용할 수 있는 철학입니다. 중요한 건 원칙을 맹목적으로 따르는 게 아니라, 그 이면의 철학을 이해하고 상황에 맞게 적용하는 것입니다.
여러분의 컴포넌트는 너무 많은 책임을 떠안고 있진 않나요? 컴포넌트가 힘들어하고 관리자도 힘들어하고 있진 않은지요? 한 번 돌아보는 시간을 가져보시면 유익한 시간이 되리라 확신합니다.
결국 좋은 설계는 원칙을 맹목적으로 따르는 것이 아니라, 원칙을 ‘이해한 뒤 선택적으로 적용하는 것’에서 시작됩니다.
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 11월 14일
Insight
재생에너지의 심장, ESS, 그리고 전기차
재생에너지는 이제 우리 삶의 일부가 되었습니다. 건물 옥상 곳곳에 설치된 소규모 태양광 발전기를 볼 수도 있고 고속도로를 달리다 보면 광활한 임야에 설치된 대규모 태양광 발전소를 볼 수 있습니다. 바닷가를 지나다 보면 하늘 높이 뻗어있는 풍력발전기도 볼 수 있죠. 재생에너지 발전은 발전기의 이름에서 짐작할 수 있듯이 태양광이나 바람같은 자연에너지를 사용해 전기를 발전하는 것을 말합니다. 그래서 재생에너지 발전에 대해 잘 모르는 분들이라도 친환경적이고 경제적일 것 같다는 느낌을 받는 분이 많을 것 같아요. 실제로 재생에너지 발전은 발전소가 한 번 설치되고 난 이후부터는 발전비용이 거의 들지 않고 환경도 훼손하지 않습니다.
듣기만 해도 매력적입니다. 점점 비싸지는 전기요금에 대비하기도 좋고 친환경적인 전기 발전이라면 하지 않을 이유가 없을 것 같아요. 그런데, 여러분은 재생에너지를 사용하고 계신가요? 기업들은 재생에너지를 사용하고 있을까요? 아마 사용하고 계시는 분들도 일부 있겠지만, 대부분은 그렇지 않을 것이라고 생각합니다. 그럼 이렇게 좋은 재생에너지를 왜 적극적으로 사용하지 못하는 걸까요? 무조건 많이 설치해서 전국에서 사용하는 전기를 모두 재생에너지로 발전해서 사용할 수는 없는 걸까요? 이렇게 하지 못하는 가장 큰 이유 중 하나는 재생에너지의 불확실성에 있습니다.
전기의 특징과 재생에너지의 한계
전기는 기본적으로 저장이 어렵고 생산과 동시에 소비되어야 합니다. 여러분이 집에서 전기를 사용하려고 전등을 켜는 순간 불이 바로 들어오는 것에서 알 수 있는 것처럼 전기는 계속해서 생산되어 우리에게 전달되고 바로 사용됩니다. 그래서 항상 적정량의 전기가 생산되고 적정량의 전기가 소비되어야 전력망이 안정된 상태로 운영될 수 있습니다. 이때 우리나라 전력망의 표준 주파수가 60Hz이며, 이를 안정적으로 유지해야 합니다(저희 회사명 식스티헤르츠도 바로 이 주파수를 의미합니다). 전기 생산량이 소비량보다 많으면 주파수가 높아져 전기설비에 문제가 발생할 수 있고, 전기 생산량이 소비량보다 적어지면 정전이 발생할 수 있습니다. 그래서 KPX(한국전력거래소)는 전력망을 안정시키기 위해 많은 노력을 하고 있습니다.
그런데 재생에너지는 어떤 특징을 가지고 있을까요? 자연에너지를 활용하는 만큼 전기의 발전량도 자연에 달려있을 수밖에 없습니다. 구름이 잔뜩 낀 날은 태양광 발전이 어렵고 바람 한 점 없는 날에는 풍력 발전이 어려울 거예요. 반면에 햇빛이 좋은 날에는 태양광 발전이 엄청나게 잘 되겠죠. 당장 한 가구를 위한 재생에너지 발전시설이 있다 하더라도 재생에너지만으로 전기를 충당하는 것은 불가능에 가깝다는 이야기가 됩니다.
예시를 들어보면, 한여름 오후 6시에 에어컨이 한창 가동되어 전력 소비가 많은 시기에 해가 지기 시작해 전력 공급이 점점 줄게 되면 정상적으로 소비 전력을 공급하지 못하는 상황이 올 거예요. 혹은, 전기를 쓰지 않는데도 태양광 발전이 너무 잘 되어 문제를 일으킬 수도 있게 되겠죠.
그렇다면 이런 재생에너지가 국가 전력망에 대규모로 연결되면 어떻게 될까요? 재생에너지 발전시설은 때로는 과도하게, 때로는 부족하게 계통에 전기를 공급하게 되고 이는 전력망을 불안정하게 만드는 위험 요소가 될 거예요. 이처럼 재생에너지의 불확실성과 간헐성은 전력망 안정성에 큰 도전 과제가 되고 있습니다.
재생에너지의 심장, ESS
그렇다면 재생에너지의 이런 한계를 어떻게 해결할 수 있을까요? 바로 여기서 ESS(Energy Storage System, 에너지저장시스템)가 등장합니다. ESS를 가장 쉽게 설명하자면 '거대한 배터리'라고 생각하시면 됩니다. 여러분이 스마트폰을 충전해두고 필요할 때 사용하는 것처럼, ESS도 전력을 저장해두었다가 필요할 때 꺼내 쓸 수 있게 해주는 시스템입니다.
예를 들어 볼까요? 한여름 낮 12시, 태양이 쨍쨍 내리쬐어 태양광 발전이 최대로 이루어지고 있습니다. 하지만 이 시간에는 대부분의 사람들이 외출해 있어서 전력 사용량이 많지 않아요. 이때 남는 전력을 ESS가 배터리에 저장해둡니다. 그리고 저녁 6시가 되면 사람들이 집에 돌아와 에어컨을 틀고 밥을 짓기 시작하면서 전력 사용량이 급증하죠. 하지만 태양은 이미 지기 시작해서 태양광 발전량은 줄어들고 있습니다. 바로 이때 ESS가 낮에 저장해둔 전력을 꺼내서 공급하는 거예요.
마치 우리 몸의 심장이 혈액을 온몸으로 순환시켜 생명을 유지하듯이, ESS는 에너지를 저장하고 공급하며 재생에너지 시스템의 생명력을 유지하는 핵심 역할을 합니다. 그래서 ESS를 '재생에너지의 심장'이라고 칭했습니다. ESS는 이렇게 재생에너지의 한계점을 보완하고 안정적인 전력공급을 할 수 있게 만들어 줍니다.
식스티헤르츠와 ESS
그럼 식스티헤르츠는 여기서 어떤 역할을 할까요? ESS는 위에 말씀드린 것처럼 재생에너지 생태계에서 아주 중요한 역할을 하지만, 자세하게 들여다 보면 단순한 거대 배터리에 불과합니다. 저장하면 저장이 되고, 방전하면 방전이 되는 게 전부인 것이죠.
여기서 식스티헤르츠가 '재생에너지의 뇌' 역할을 수행합니다. 식스티헤르츠는 ESS를 관리할 수 있는 소프트웨어를 개발해 ESS가 더 효율적으로 재생에너지를 활용할 수 있도록 돕습니다. 단순히 충방전 on/off만 하던 ESS를 더 다양한 상황에 맞춰 정밀하게 제어하는 것이죠. 구체적으로 몇 가지 예시를 들어보겠습니다.
1. 잔여 재생에너지 발전량 저장
태양광 발전량과 가구 소비량을 예측한 뒤 잉여 발전량이 예측되면 잉여 발전량은 ESS로 저장될 수 있도록 실시간으로 제어합니다. 저장된 전력은 필요한 때 방전해서 사용할 수 있게 되어, 재생에너지를 유연하게 활용할 수 있게 도와줍니다.
2. 전력 부하시간대별 요금 최적화
우리나라의 일부 전력 사용자들은 계절별/시간별로 전기요금이 경부하/중간부하/최대부하로 요금 체계가 나뉘어져 있습니다. 경부하 시간대에 사용하는 전기요금이 가장 저렴하고 최대부하 시간대에 사용하는 전기요금이 가장 비쌉니다.
그래서 경부하 시간대에는 ESS를 최대로 충전하고, 더 비싼 전기요금 시간대에 ESS를 방전해 전기요금을 절감할 수 있는 알고리즘을 개발해 운용하고 있습니다. 여기에 태양광 예측기술이 결합되어 경부하 시간대에 재생에너지만으로 ESS를 가득 충전할 수 없는 경우 부족한 전력은 계통을 통해 구매해 축적해 더 효율적으로 동작할 수 있도록 돕습니다.
3. DR 제도 대응
앞서 KPX에서 안정적인 전력망 유지를 위한 노력을 하고 있다고 말씀드렸는데요. 여러가지 방법 중 하나로 전력 사용을 조절하는 방법이 있습니다. KPX에서 전력이 부족한 시간대에는 전력 사용을 줄이라는 요청을 보내고, 전력이 남을 것 같은 시간대에는 전력 사용을 늘리라는 요청을 보내게 됩니다.
전력 사용을 줄이는 요청을 보내 전력망을 안정시키는 제도를 일반적인 DR(Demand Response)라고 부르고 전력 사용을 늘리는 요청을 보내 전력망을 안정시키는 제도를 플러스 DR이라고 부릅니다. 이런 DR 제도에 참여하게 되면 그에 응하는 보상을 받을 수 있고, ESS는 이런 제도에 참여하기에 최적화된 시스템입니다. DR에 적극 대응할 수 있도록 소프트웨어로 ESS를 제어할 수 있습니다.
전기차, 움직이는 ESS
그럼 전기차는 뜬금없이 왜 언급되었을까요? 전기차는 왜 전기차일까요? 전기로 동작하는 차량이기 때문에 전기차라고 부르겠지요. 전기로 운행이 가능하려면 무엇이 필요할까요? 바로 전기를 저장할 수 있는 배터리가 필요합니다. 그래야 전원 공급에서 멀어진 채로 장거리를 운전할 수 있겠죠. 그래서 전기차에도 모두 전기배터리가 있고 충전/방전을 할 수 있습니다. 최근에는 V2L(Vehicle to Load)라는 기술이 널리 퍼져 실제로 전기차에서 전기를 공급받아 캠핑이나 비상상황에 활용할 수 있게 되었습니다.
이제 왜 전기차가 언급되었는지 조금 감이 오시나요?
전기차는 이동이 가능하다.
전기차는 전기를 저장할 수 있다.
요약하면 전기차는 결국 움직일 수 있는 ESS라고 볼 수 있습니다. 이렇게 전기차를 계통과 연결해 전기차를 충전하는 것 뿐만 아니라 전기차를 방전시켜 전력망에 보낼 수 있는 기술을 V2G(Vehicle-to-Grid)라고 부릅니다.
사실 일반적인 ESS는 굉장히 비싸고 거대해서 일반 가정에서 활용하기 쉬운 시스템은 아닙니다. 그에 비해 전기차는 이제 널리 보급되어 쉽게 볼 수 있죠. 그래서 저희는 전기차를 ESS처럼 활용해 일반 가구의 재생에너지 활용도를 높이는 방안을 고민하고 소프트웨어로 해결할 수 있는 기술을 개발하고 있습니다. 언젠가는 전기차 차주들이 계통망을 안정화시키는데 가장 큰 역할을 할 것이라고 확신합니다.
함께 만들어갈 미래
식스티헤르츠에서는 이처럼 다양한 상황에 다양한 방법으로 재생에너지를 활용하는 소프트웨어를 개발해 운영하고 있습니다. 현재 전력시장과 재생에너지 생태계를 분석해 그에 맞는 알고리즘을 개발하고, 이를 적절하게 시각화해서 고객들이 사용하기 편하고 이해하기 쉬운 형태로 서비스를 만들어 나가고 있습니다.
재생에너지, V2G에 관심이 있으시다면 식스티헤르츠의 행보를 관심있게 지켜봐주시면 감사하겠습니다. 더 나아가 이런 기술 개발에 함께 참여하고 싶은 소프트웨어 엔지니어분들의 많은 관심 부탁드립니다.
By 방경민 ㅣ TVPP/FE Leader ㅣ 60Hertz
🔗 채용 페이지 바로가기!
#재생에너지 #에너지저장장치 #ESS #DR #전기차 #V2G #스마트그리드 #탄소중립 #에너지전환 #에너지혁신 #가상발전소 #태양광 #풍력 #전력망안정화 #식스티헤르츠 #에너지소프트웨어
2025년 9월 23일
Insight
재생에너지 혁신의 현장, 기후산업국제박람회 2025 참여 소식
식스티헤르츠가 지난 8월 27일부터 29일까지 부산 벡스코에서 열린 세계기후산업박람회(WCE 2025)에 참가했습니다. 이번 행사는 산업통상자원부, 국제에너지기구(IEA), 세계은행(WB)이 공동 주최한 글로벌 에너지·기후 대표 박람회로, 약 560개 국내외 선도 기업이 참여해 미래 에너지 혁신 기술을 선보이는 자리였습니다.
WCE 2025, “Energy for AI & AI for Energy”
올해 WCE의 주제는 “Energy for AI & AI for Energy” 였습니다. AI가 어떻게 지속 가능하고 안전하며 효율적인 글로벌 에너지 시스템을 만들어가는지, 또 인공지능이 에너지 수요 급증과 공급 안정화 문제를 어떻게 해결할 수 있는지가 주요 의제로 다뤄졌습니다. 전시장에서는 청정에너지, 에너지·AI, 미래교통, 환경, 해양, 기상 등 다양한 분야의 혁신 기술이 전시되었으며, 글로벌 리더십·에너지&AI·기후 등 3개의 서밋과 12개의 전문 회의 등이 함께 열렸습니다.
제1전시장 현장
이번 기후산업국제박람회 2025의 제1전시장에는 SK, 현대차, 삼성전자, 한화큐셀, 두산에너빌리티, 포스코, 효성중공업, 고려아연 등 국내 주요 기업들이 대거 참여해 미래 에너지 전환을 위한 다양한 기술과 솔루션을 선보였습니다. 특히, 청정에너지와 스마트그리드, 수소경제 등 첨단 분야의 전시가 활발히 이루어지며, 전력망 혁신과 탄소중립 실현을 위한 산업계의 방향성을 엿볼 수 있었습니다. 많은 참관객들이 최신 기술을 직접 체험하며, 기업 부스에서 관계자들과 활발히 교류하는 모습이 인상적이었습니다.
식스티헤르츠 부스 & 주요 성과
식스티헤르츠는 이번 박람회에서 대한민국 에너지대전 혁신상 특별관과 전력거래소(KPX) 부스를 통해 AI 기반 에너지 통합 관리 솔루션을 소개했습니다. 3일간 운영된 부스에는 공공기관, 대기업, 금융권 등 다양한 이해관계자가 방문하여 깊은 관심을 보였습니다.
특히 해외 재생에너지 사업 협력 가능성 논의, 에너지케어 및 모니터링 솔루션 문의, PPA 사무위탁과 신규 서비스 모델에 대해 의견을 나누는 등 다양한 후속 협업 기회가 마련될 것으로 기대됩니다.
KPX와 함께한 CMV 소개
전력거래소(KPX)와의 파트너십 프로젝트인 CMV(Cloud Motion Vector)도 전시 현장에서 소개되었습니다. 그래픽과 영상을 통해 방문객들에게 구름이동기반 초단기 발전량 예측 시스템으로 새로운 전력시장 시각화 도구를 선보였습니다.
혁신상·IR·세미나 참여 소식
이번 기후산업국제박람회 2025에서 식스티헤르츠는 기후·에너지 혁신상 시상식에서 산업통상자원부 장관상을 수상하며, 자사의 기술력과 성과를 공식적으로 인정받는 뜻깊은 성과를 거두었습니다. 또한 전시 기간 동안 IR 기업 소개 발표와 중부발전 주최 미니 세미나에 참여해, 에너지 전환을 위한 비전과 혁신적인 솔루션을 공유했습니다.
현장 반응 & 설문 결과
혁신상 특별관에서 진행한 설문조사에는 약 80여명이 참여했으며, 응답자의 다수는 제조업, 에너지·전력, 공공 부문 종사자였습니다. 응답자들은 ▲에너지 절감 및 수익성 개선 효과 ▲AI 활용 가능성 ▲파트너십 기회 등에 높은 관심을 보였습니다.
식스티헤르츠가 만든 의미
이번 WCE 2025 참가를 통해 식스티헤르츠는 국내외 주요 기관 및 기업과의 협력 가능성을 확인하고, AI 기반 에너지 혁신 솔루션의 시장성과 필요성을 다시 한번 입증했습니다. 앞으로도 재생에너지 확산과 효율적 관리, 그리고 탄소중립 실현을 위해 글로벌 파트너십을 확대해 나갈 예정입니다.
#기후산업국제박람회2025 #기후산업박람회 #기후에너지혁신상 #산업통상자원부 #한국에너지공단 #장관상표창 #재생에너지전환 #AI에너지
2025년 9월 9일
Impact
SOVAC과 함께하는 사회적가치 페스타 현장 스케치
식스티헤르츠는 지난 8월 25일(월)부터 26일(화)까지 삼성동 COEX Hall C에서 열린 제2회 대한민국 사회적가치 페스타에 참가해, 다양한 기관 및 기업들과 지속가능한 미래를 위한 협력 방안을 함께 고민하며 뜻깊은 시간을 보냈습니다.
대한민국 사회적 가치 페스타란? 🎊
대한상공회의소가 주최하고, SOVAC, SK텔레콤, 현대해상, 카카오임팩트, KOICA 등 여러 기관이 함께 주관하며 기후위기, 지역소멸, 미래세대, 디지털 격차 등 복합적인 사회문제를 민관 협력으로 해결하기 위해 마련된 국내 최대 규모의 사회적 가치 축제입니다. 올해 행사에는 13,000여 명의 참관객과 300여 개 기관·기업이 함께하며 다양한 강연과 전시를 통해 “지속가능한 미래를 설계(Designing the Sustainable Future)”라는 주제를 나눴습니다.
식스티헤르츠의 전시 부스 ☀️
식스티헤르츠는 이번 페스타에서 SOVAC “혁신의 길_기후위기 극복” 존에 전시 부스를 마련하고, 자사의 AI 기반 재생에너지 발전량 예측 및 관리 기술을 중심으로 다양한 에너지 자원을 통합적으로 운영할 수 있는 솔루션을 소개했습니다. 이를 통해 기후위기 대응과 안정적인 전력 운영, 그리고 탄소중립 실현을 돕고 있습니다. 이틀간의 현장은 다양한 공공기관, 대기업, 소셜벤처, 금융기관, 그리고 업계 전문가분들을 만나 식스티헤르츠의 기술과 비전을 공유할 수 있었던 뜻 깊은 자리였습니다. 특히, 에너지 전환 솔루션에 대한 많은 관심과 다양한 협력 가능성을 확인할 수 있는 시간이었습니다.
퀴즈 이벤트와 현장 🎁
식스티헤르츠는 부스를 찾아주신 분들을 위해 "도전, 식스티!" 퀴즈 이벤트도 함께 진행했습니다. 방문객들이 식스티헤르츠를 한층 더 이해하고 기억할 수 있는 퀴즈로, 재생에너지, 탄소중립 등에 관심을 보이며 현장 분위기를 더욱 뜨겁게 만들어 주었습니다. 또한 퀴즈를 모두 맞힌 정답자에게는 소정의 기념품을 드려서 현장 분위기도 더욱 활기찼습니다.
현장에서 만난 소중한 인연들 🤝
이번 페스타에서는 공공 및 민간을 포함해 다양한 소셜벤처 파트너사와의 만남을 통해 식스티헤르츠의 활동 영역을 넓히고, 새로운 협력의 기회를 모색할 수 있었습니다. 많은 분들께서 관심을 가지고 찾아주셔서 재생에너지 확산을 위한 사회적 가치 창출 활동에 대한 공감과 응원을 느낄 수 있었습니다. 🙏
앞으로의 계획 🗓️
이번 페스타는 단순한 전시회를 넘어, 재생에너지와 기후테크 분야의 리더로서 식스티헤르츠가 나아갈 방향을 다시 한번 확인하는 소중한 시간이었습니다. 앞으로도 현장에서 만난 소중한 인연들을 바탕으로 협업을 이어가며, 더 많은 기업과 기관이 지속가능한 에너지 전환에 동참할 수 있도록 최선을 다하겠습니다.
마무리하며 🚀
SOVAC과 함께하는 대한민국 사회적가치 페스타는 ‘함께 만드는 지속가능한 미래’라는 비전을 공유하는 자리였습니다. 식스티헤르츠도 이 여정의 한 축으로서, 기후위기 대응과 사회적 가치 확산을 위한 노력을 계속 이어가겠습니다.
함께해 주신 모든 분들께 진심으로 감사드립니다! 🌏💚
#식스티헤르츠 #SOVAC #사회적가치페스타 #재생에너지 #에너지전환 #AI기반솔루션 #기후테크 #지속가능한미래 #사회적가치 #소셜벤처
2025년 8월 28일
Insight
에너지고속도로란?
최근 뉴스에서 “에너지고속도로”라는 표현을 자주 접할 수 있습니다. 특히 “에너지고속도로” 구축이 정책적 화두로 떠오르기도 했는데요. 이름만 들으면 도로나 교통망이 떠오를 수도 있지만, 사실은 전기를 장거리-대규모로 효율적으로 이동시키기 위한 첨단 송전 인프라를 가리키는 비유적인 표현입니다. 이번 블로그 글에서는 “에너지고속도로”와 함께 관련된 주요 키워드를 살펴보도록 하겠습니다.
왜 ‘고속도로’라는 표현을 쓰나요?
자동차 고속도로가 사람과 물자를 빠르고 효율적으로 이동시키듯, "에너지고속도로"는 발전된 전기를 멀리 있는 소비지로 신속하고 효율적으로 ‘운송’하는 첨단 전력망을 의미합니다.
왜 이런 개념이 필요할까요?
전 세계가 탄소중립을 목표로 재생에너지 비중을 확대하고 있지만, 대부분 발전소 입지와 수요가 일치하지 않는 문제가 발생하고 있습니다. 다시 말해 재생에너지는 친환경적이지만 입지가 한정적입니다. 예를 들어, 대규모 태양광 발전소는 햇빛이 좋은 공장 지붕, 임야, 평야 등에 설치가 됩니다. 해상풍력발전단지는 어떨까요? 바람이 좋은 해안이나 산악지대를 선호합니다. 반면에 주요 전력 소비는 대도시나 도심 또는 산업지대에 집중되고 있습니다. 그래서 이러한 격차를 메우고 거리를 잇기 위한 인프라 혁신으로 “에너지고속도로”와 같은 첨단 전력망이 필요합니다.
기술적 핵심
"에너지고속도로"는 기존 송전망과는 다른 기술이 적용됩니다. 매우 긴 거리에서도 전력 손실이 적어야 하며, 대규모 전력을 한 번에 안정적으로 이송할 수 있어야 하기 때문입니다. 그래서 초고압 직류 송전(HVDC)과 같은 핵심 기술이 필요합니다. 또한 단순한 ‘길’이 아닌 스마트하고 유연한 에너지 네트워크를 기반으로 만들어져야 합니다.
주요 특징
장거리 초고압 송전: 태양광 풍력과 같이 먼 거리에 위치한 대규모 재생에너지 발전소에서 도심이나 산업단지로 전력 전송
디지털-스마트 그리드 기술 접목: AI, IoT 기반 실시간 수요관리와 분산자원 통합
지역 간 연계성 강화: 지역 간 전력망을 연결해 수급 안정화
경제-환경적 가치
"에너지고속도로"는 단순한 전력망이 아닙니다. 재생에너지 발전 단가가 낮은 지역에서 전력 조달 시 전력 가격 안정화에 기여하며, 기존의 화력 발전소 대체 및 탄소중립 실현에 기여 가치는 매우 클 것으로 기대됩니다.
단점 및 한계
하지만 초고압 직류(HVDC) 송전망 건설에는 대규모의 투자가 필요합니다. 해저케이블, 변환소(AC—>DC 변환), 관리 시스템 등 발생 비용이 매우 큽니다. 정부 보조나 전기요금 인상과 같은 논쟁도 불가피합니다. 또한 설계, 인허가, 협의, 시공까지 긴 건설 기간이 걸릴 수도 있습니다. 기술 의존성이나 표준 문제나 초기 투자에 더해 운영 유지 비용이나 보안도 큰 문제가 될 수 있습니다. 이렇듯 "에너지고속도로"는 재생에너지 전환의 필수 인프라지만, 비용, 시간, 사회적 합의, 기술 의존 등 해결해야 할 도전 과제가 매우 많습니다.
보이지 않는 혁신의 길
그럼에도 자동차 고속도로가 산업화를 이끌었듯, "에너지고속도로"는 재생에너지 전환을 가능하게 만드는 전략적인 인프라입니다. 발전소는 지방에, 소비는 도시에와 같은 구조적 문제를 해결하며 재생에너지의 불규칙성을 보완할 수 있습니다. 앞으로 우리나라가 이 거대한 보이지 않는 도로를 어떻게 설계하고 구축할지 에너지 전환과 관련한 중요한 과제가 될 것으로 보입니다.
#에너지고속도로 #송전망혁신 #전력망 #탄소중립 #에너지전환 #재생에너지확산 #전력인프라 #HVDC #스마트그리드 #분산에너지
2025년 7월 24일
Insight
식스티헤르츠, 2025년 '혁신 프리미어 1000' 기업 선정
식스티헤르츠가 2025년 '혁신 프리미어 1000' 기업에 선정 되었습니다!
지난 5월 14일, 금융위원회는 산업통상자원부, 과학기술정보통신부, 중소벤처기업부 등 13개 부처와 함께 2025년 제1차 ‘혁신 프리미어 1000’ 기업으로 총 509개의 중소·중견기업을 선정했다고 발표했습니다. (참조: 대한민국정책브리핑, 중소·중견기업 509개, '혁신 프리미어 1000' 선정)
이 프로그램은 기술 혁신을 통해 신제품 개발, 신규 시장 개척, 부가가치 창출, 고용 확대에 기여할 수 있는 유망 기업을 발굴·지원하기 위한 정부의 중점 정책 중 하나입니다.
식스티헤르츠는 이번 선정을 통해 AI 기반 재생에너지 발전 예측 및 제어 기술의 혁신성과 성장 가능성을 정부로부터 공식적으로 인정받았습니다. 이는 기술력은 물론, 지속가능한 에너지 전환을 이끄는 기업으로서의 경쟁력과 비전을 입증하는 중요한 이정표가 되었습니다.
식스티헤르츠의 주요 기술은 소규모 재생에너지 자원을 통합 관리하는 가상발전소(VPP) 통합 소프트웨어와 AI를 활용한 발전량 예측 기술을 기반으로, 재생에너지의 불확실성을 줄이고 전력 운영의 효율성을 높이는 데 중점을 두고 있습니다. 이러한 기술력은 재생에너지 생태계 고도화에 기여하며, 이번 평가에서 높은 점수를 받은 핵심 요인으로 분석됩니다.
이번 선정을 계기로 식스티헤르츠는 정책금융기관의 맞춤형 지원과 부처별 특화 사업의 혜택을 바탕으로, 기술 중심의 에너지 전환은 물론 글로벌 시장 진출에도 더욱 박차를 가할 계획입니다.
[회사 소개]
식스티헤르츠는 2021년, 전국 13만 개의 태양광·풍력·에너지저장장치(ESS)를 연결한 ‘대한민국 가상발전소’를 공개하며 주목을 받았습니다. 이후 약 8만 개의 재생에너지 발전소(총 18GW)의 위치와 발전량을 AI로 시각화한 ‘햇빛바람지도’를 무료로 제공하는 등, 에너지 데이터 기반 서비스를 지속 확장하고 있습니다.
2023년: 자체 개발한 에너지관리시스템(EMS)으로 CES 혁신상 수상
2024년: IPEF(인도·태평양 경제 프레임워크) 선정 아시아·태평양 100대 기후테크 기업
앞으로도 식스티헤르츠는 기술을 통해 더 많은 사람들이 지속가능한 에너지 전환에 참여할 수 있도록 혁신을 이어가겠습니다.
👉 홈페이지 바로가기
#식스티헤르츠 #재생에너지 #에너지전환 #가상발전소 #인공지능 #RE100 #탄소중립 #기술혁신 #혁신프리미어1000 #선정
2025년 5월 19일
Insight
작은 변화, 큰 영향
안녕하세요,
에너지 IT 소셜벤처 식스티헤르츠입니다.
지난 4월 23일부터 25일까지 서울 양재동 aT센터에서 열린 '2025 자동차부품산업 ESG·탄소중립 박람회'에서 식스티헤르츠 부스를 방문해주신 모든 분들께 진심으로 감사드립니다.
이번 박람회에서 식스티헤르츠는 기업의 지속가능경영을 실현할 수 있도록 돕는 다양한 에너지 IT 솔루션을 제1 전시장 제조혁신관(현대차-기아 제조솔루션본부 협력관) 및 제2전시장 재생에너지관(현대건설-현대차증권 협력관)을 통해 아래와 같이 소개했습니다.
태양광 발전소 구축 및 운영 솔루션
전력 통합관리 모니터링 시스템(EMS)
온사이트 PPA 및 RE100 달성 컨설팅
V2G 에너지 신산업 생태계 구축
수요반응(DR)을 통한 전력 효율화
특히, 박람회 기간 제조 산업을 포함한 많은 방문객들이 공장 지붕이나 주차장 등 유휴 부지를 활용한 태양광 구축 사례에 많은 관심을 보여주셨으며, 재생에너지 전환을 통한 비용 절감 방안에 대한 깊이 있는 상담도 적극적으로 요청해 주셨습니다.
예를 들어, 약 3,000평 규모의 공장에 1MW급 태양광 발전소를 도입하면 연간 약 3,000만원의 전기료 절감, 에너지 관련 부가 수익 창출, 그리고 604톤 규모의 온실가스 감축 효과를 기대할 수 있습니다.
이를 위해 식스티헤르츠의 고객 환경 맞춤형 토탈 솔루션을 도입 시 ESG 경영을 더욱 효율적이고 체계적으로 실현할 수 있습니다.
[고객 맞춤형 솔루션]
태양광 설비 도입
실시간 발전량 모니터링
RE100 성과 분석
[태양광 도입 및 모니터링 솔루션 구축 최신 사례]
인천 남동 스마트그린산업단지 에너지 자급자족 인프라 구축 및 운영사업
태양광 패널부터 인버터, 모니터링 솔루션의 통합 구축
고객의 전기 사용량에 따른 과금 정산서 발행 (임대형 발전소 대상)
실시간 출력 제어 및 스마트 O&M을 통한 발전량 오차율 및 고장 예측 감지
현대자동차 국내외 공장 태양광 모니터링 시스템 구축
현대자동차 국내 주요 공장 다수 온-프레미스 태양광 모니터링 스마트 O&M 시스템 구축 (5MW~9MW)
현대자동차 미국 북미 공장 온-프레미스 태양광 모니터링 시스템 구축
앞으로도 식스티헤르츠는 탄소중립과 에너지 전환을 선도하는 신뢰받는 파트너로서, 귀사의 지속가능한 성장을 적극 지원하겠습니다.
지속가능한 미래를 함께 만들어가길 기대합니다!
👉 식스티헤르츠 솔루션 자세히 보기
#식스티헤르츠 #ESG #RE100 #탄소중립 #탄소저감 #자동차부품산업 #지속가능 #재생에너지 #태양광 #EMS #PPA #REC #V2G #DR
2025년 4월 30일
Tech
가상발전소(VPP) 통합 솔루션
분산에너지 자원의 특징
전세계적으로 탄소중립이 주요 화두가 되면서, 탄소중립 달성 수단으로 분산에너지에 대한 관심이 증대되고 있습니다. 분산에너지는 전통적인 중앙집중식 발전소를 통한 전력 수급 시스템에 대비되는 개념으로, 에너지의 사용지역 인근에서 생산되는 에너지를 말합니다. 기본적으로 분산에너지는 규모가 작고 에너지 사용지역 인근에 위치한다는 특징을 가지고 있습니다.
분산에너지 자원의 확대
분산에너지는 기존의 대단위 발전소 및 송전선을 건설하는 방식보다 용이하며, 송 · 배전망을 신규로 건설하기 위해 투입되는 인프라 건축비용과 운영비용을 크게 절감할 수 있다는 장점이 있습니다. 특히 분산에너지 자원들은 친환경 재생에너지로 온실가스나 탄소배출 감소에 기여하는 바가 크다고 여겨집니다. 하지만 분산에너지 자원 중 태양광과 풍력은 일조량과 풍량에 의존하기 때문에 변동성이 생길 수 있고, 이로 인해 전력계통의 안전성을 저해할 수 있습니다. 우리나라도 태양광 중심으로 재생에너지 비중을 확대하고 있어서 변동성 문제를 완화하거나 발전 효율을 높일 수 있는 방안에 대한 관심 및 관련 정책 등이 확대되고 있습니다.
분산에너지 자원의 효율적 관리 운영을 위한 솔루션
위에서 언급한 재생에너지 비중이 확대되면서 발전 효율 증대, 발전량 예측 및 관리 등 관련 분야의 기술 개발 및 도입이 활발히 진행되고 있는 가운데, 식스티헤르츠에서 출시한 Energy Scrum은 분산에너지 자원을 효율적으로 관리 및 운영하는데 최적화된 에너지 관리 시스템입니다. Energy Scrum을 통하면 PV, ESS, 연료 전지, EV 충전기 등 다양한 분산자원을 AI를 기반으로 전체 에너지 공급과 수요를 정확하게 예측하여 하나의 통합된 시각으로 확인 및 관리할 수 있습니다.
사용자 친화적으로 설계된 에너지 관리 시스템
Energy Scrum은 일부 번거로운 프로세스를 최소화하여 분산자원을 조율할 수 있도록, 사용자가 사용자별 운영 시나리오를 적용하여 친환경 전기 사용을 극대화하는 것과 같은 목표를 달성할 수 있도록 지원합니다. 예를 들어 Energy Scrum을 오래된 주유소에 적용시 친환경 에너지 스테이션으로 전환할 수 있습니다.
AI 기반 기술 혁신으로 고도화
Energy Scrum은 다양한 분산자원을 연결하고 클라우드 기반 시스템에서 방대한 양의 비정형 데이터를 관리할 수 있는 OpenAPI 서비스를 제공합니다. 분산자원과 지역 IoT 센서, 기상 위성과 같은 외부 소스의 정보를 결합하여 AI 모델을 점진적으로 훈련하고, 데이터와 학습을 축적하여 전체 에너지 공급과 수요에 대한 보다 정확한 예측을 제공합니다. 또한 예측된 에너지 정보를 활용하여 사용자의 요구에 맞는 다양한 모드(예: 친환경 전기 사용량 극대화 모드)를 제공합니다. 따라서 사용자는 목표를 달성하기 위해 원하는 방식으로 분산자원을 조정할 수 있습니다.
신재생에너지 시장을 겨냥한 차별화
Energy Scrum의 차별화된 강점은 대부분의 발전사들이 사용하고 있는 모니터링 솔루션에 비해 제조사를 포함한 다양한 고객의 니즈에 맞춤형으로 설계가 가능하며, 태양광 풍력 뿐 만이 아닌 다양한 분산에너지 자원들을 효율적으로 관리할 수 있다는 것입니다. 특히 관리 및 운영의 영역을 넘어 발전소유주들의 시장을 연결하여 재생에너지의 활성화와 수익을 만들 수 있는 생태계를 구축하는 통합 플랫폼으로 구현되었다는 점입니다. 예를 들어 V2G (Vehicle-to-grid, 전기자동차를 전력망과 연결해 배터리의 남은 전력을 이용) 기술을 적용 및 전기차를 에너지 저장 장치로 활용하는 시장을 연결하여 주행 중 남은 전력을 건물에 공급하거나 판매할 수 있는 플랫폼으로 활성화할 수 있습니다.
CES 2023 혁신상 수상
식스티헤르츠의 에너지관리시스템 Energy Scrum은 세계 최대 IT 전시회 ‘CES 2023’에서 지속 가능성, 에코 디자인 및 스마트 에너지 분야에서 혁신상을 수상한 바 있습니다. 친환경 분산전원이 전 세계적으로 빠르게 확대됨에 따라 이를 통합적으로 관리할 수 있는 시스템 수요가 지속적으로 증가하고 있는 가운데, 식스티헤르츠의 기술력이 집약된 Energy Scrum은 첨단 에너지 관리시스템으로 재생에너지 관리의 새로운 지평을 열었다는 평가를 받았습니다. 특히 기존 태양광 중심의 가상발전소 개념을 넘어, 풍력과 에너지저장장치(ESS)까지 통합 관리하는 종합 솔루션으로서 재생에너지의 효율적인 운영을 통해 재생에너지 확산에 기여할 수 있기를 기대합니다.
#식스티헤르츠 #재생에너지 #에너지관리시스템 #EMS #VPP #ESS
2025년 4월 25일
Impact
기술로 그리는 지속가능한 에너지 전환
전 세계적으로 RE100과 탄소중립이 기업의 새로운 기준이 되어가고 있는 지금, ‘재생에너지를 더 쉽게, 더 효과적으로’ 쓰기 위한 기술이 필요합니다. 식스티헤르츠는 이러한 전환을 현실로 만들고 있는 에너지 IT 소셜벤처입니다. 인공지능, 빅데이터, 클라우드 기술을 바탕으로 분산된 재생에너지 자원의 가치를 극대화하며, 사회와 환경에 긍정적인 변화를 만들어가고 있습니다.
수치로 증명된 임팩트
지난 해 기준 식스티헤르츠는 8개 기업을 대상으로 재생에너지 구독 서비스를 운영하며 총 11,901MWh의 재생에너지 사용을 이끌어냈습니다. 이를 통해 약 5,089tCO2e의 탄소배출을 저감하는 성과를 달성했으며, 이는 탄소중립 실현을 위한 의미 있는 진전이었습니다. 뿐만 아니라, 소셜벤처 및 중소기업을 위한 소규모 REC 구매 지원, 월별 리포팅 시스템 운영 등을 통해 에너지 접근성과 투명성도 높이고 있습니다.
기술로 완성하는 에너지 전환
식스티헤르츠는 기후, 수요, 공급의 불확실성 속에서도 전력망을 안정적으로 운영할 수 있도록 최신 기술을 적용한 다양한 솔루션을 개발 및 운영하고 있습니다.
☀️ 햇빛바람지도
국내 유일의 재생에너지 발전량 예측 공개 서비스로, 전국의 태양광/풍력 발전소 발전량을 AI 기반으로 예측 및 시각화하여 일 발전량 및 내일 발전량 예측치를 제공합니다. 재생에너지 발전량에 영향을 미치는 기상정보와 발전량을 함께 볼 수 있습니다.
🔋 에너지스크럼
태양광 발전소, ESS, EV 충전소 등 분산 전원을 통합 관리하고, 실시간 예측을 통해 공급과 소비의 균형을 맞춥니다. 클라우드 기반으로 보안성과 확장성까지 갖췄으며, 실제 전력거래소와 연계해 수요자 중심의 운영 최적화를 고도화하고 있습니다.
사회적 가치와 지속가능성
식스티헤르츠는 단순히 기술을 제공하는 기업을 넘어, 지속가능한 비즈니스 생태계를 만드는 파트너입니다.
RE100 기업 지원: 탄소중립 목표를 가진 기업에게 손쉬운 전력 전환을 위한 구독형 서비스를 제공합니다.
소상공인 재생에너지 전환 지원: 재정적 부담이 큰 초기 기업에게도 100% 재생에너지 사용 기회를 제공합니다.
사회적 성과 측정: 정량/정성 지표 기반의 프로젝트 영향 분석을 수행합니다.
햇빛발전소 기증: 에너지 취약계층 지원 및 지역사회 환원을 위한 프로젝트를 확산해 갑니다.
확장하는 비전
식스티헤르츠는 앞으로 다음과 같은 방향으로 에너지 혁신을 이어가기 위한 플랜을 실천하고 있습니다.
글로벌 플랫폼 확대
국내에서 검증된 기술을 아시아-태평양 지역으로 확장
지역 간 재생에너지 거래를 위한 인프라 확보
RE100 시뮬레이션 서비스 고도화
기업 맞춤형 컨설팅 제공
더 많은 기업의 참여를 유도
V2G 기술을 활용한 에너지 효율화
EV를 에너지 네트워크의 한 축으로 활용
분산 전원의 활용도를 높이는 차세대 전략
지속가능한 에너지 생태계를 위한 여정
식스티헤르츠는 단순한 에너지 기술기업을 넘어, 재생에너지 전환을 앞당기며, 기업과 사회가 함께 탄소중립을 향해 나아갈 수 있도록 다음 세대를 위한 기술과 협력의 터전을 마련하고 있습니다. 앞으로도 식스티헤르츠는 지속가능한 미래를 위한 실질적 변화를 만들어갈 것입니다.
#식스티헤르츠 #소셜벤처 #SDG #재생에너지 #RE100 #탄소중립 #탄소배출 #햇빛발전소
2025년 4월 24일
People & Culture
식스티헤르츠(60Hertz)를 소개합니다
일상을 지키는 특별한 기술을 만드는 팀
전력망을 안정적으로 관리하는 것은 매우 중요합니다.
전력망이 안정적으로 유지되지 않을 경우, 대규모 정전(black out)과 같은 국가적 재난 사태로 이어질 수 있기 때문입니다. 전력의 공급과 수요가 일치할 때, 대한민국의 전력망은 ‘60Hertz’라는 주파수를 유지합니다.
그래서 식스티헤르츠(60Hertz)는 우리의 안온한 일상을 지키는 균형을 의미합니다.
식스티헤르츠는 우리의 일상을 지키는 특별한 기술을 만듭니다. 🙂
다음 세대를 위한 에너지 기업
“우리가 기후위기를 막을 수 있는 마지막 세대이다”
우리 식스티헤르츠 구성원이 공유하는 세계관입니다.
지구 평균 온도가 매년 상승하고 있는 지금, 이를 해결할 중요한 열쇠는 ‘에너지 전환’입니다. 우리는 IT 기술을 통해 더 효율적이고 지속가능한 에너지 생태계를 구현하여 재생에너지 확산에 기여하고자 합니다.
기술로 이루어낸 작은 변화들이 모여, 다음 세대를 위한 큰 변화를 만들어 갈 수 있다고 믿습니다.🙏
식스티헤르츠와 함께해주세요!
사람들의 일상을 지키고 기후위기를 막기 위해 노력하는 식스티헤르츠 여정에 함께해주세요.🚀
우리는 지속가능한 미래를 위해 끊임없이 학습하고 함께 성장합니다.
변화를 두려워하지 않고 새로운 기술과 지식을 습득하고, 솔직하게 의견을 나누고, 서로에게 최고의 동료가 되고자 노력합니다.
식스티헤르츠의 세계관에 공감한다면 주저하지 말고 알려주세요. 우리는 내일을 향해 함께 달릴 동료를 기다립니다.🏃➡️
자세히 알아보기
👉 Embedded firmware Engineer (임베디드 펌웨어 개발, EE)
👉 Sales(영업 기획)
👉 Project Manager
👉 R&D 정부 과제 기획/관리
2025년 4월 23일
Insight
식스티헤르츠 홈페이지가 새로워졌습니다!
안녕하세요,
에너지 IT 소셜벤처 식스티헤르츠(60Hertz) 입니다. 🚀
오늘은 여러분께 새로워진 식스티헤르츠 공식 홈페이지 소식을 전해드립니다.
✨ 무엇이 달라졌을까요?
더 빠르고 직관적인 사용자 경험
복잡하지 않은 구조, 깔끔한 디자인, 그리고 모바일에서도 최적화된 화면으로 누구나 편리하게 정보를 확인하실 수 있습니다.
서비스 중심의 콘텐츠 구성
재생에너지 생산-관리-유통의 전반적인 Life cycle 솔루션을 제공하는 식스티헤르츠의 주요 기술과 서비스를 한눈에 확인할 수 있도록 정리했습니다.
글로벌 확장을 위한 다국어 지원
글로벌 파트너들과의 소통 강화를 위해 영문 페이지를 확장하였습니다.
🌍 왜 지금, 홈페이지를 개편했을까요?
식스티헤르츠는 국내를 넘어 베트남, 미국, 독일 등 글로벌 시장 진출을 본격화하고 있으며
에너지 전환, 탄소중립, 기후테크 등 빠르게 변화하는 흐름 속에서 식스티헤르츠의 기술과 철학을 더 많은 분들과 나누고 싶었습니다.
👀 지금 바로 방문해보세요!
새로워진 홈페이지에서 식스티헤르츠가 어떻게 기술로 기후 위기에 답하고 있는지 직접 확인해 보세요.
👉 https://60hz.io
여러분의 방문을 환영합니다!
앞으로도 더욱 투명하고, 혁신적이며, 사회적 가치를 실현하는 식스티헤르츠가 되겠습니다.
고맙습니다.
식스티헤르츠팀 드림
2025년 4월 21일
All
Tech
Insight
People & Culture
Impact
Tech
[개발자 인터뷰 ①] “기술에 얽매이지 않고 현실 문제 해결에 집중하는 실용적인 개발을 하고 싶어요.” / Tech Lead 최성원 님
본인 소개 부탁드립니다.
안녕하세요. 개발 조직을 리드하고 있는 최성원입니다.
입사한 지는 약 3년 정도 되었고, 서비스 개발을 중심으로 다양한 업무를 수행해왔어요. 특히 기술과 비즈니스를 함께 이해하는 경험을 통해 개발자의 시선에서 서비스의 방향과 가치를 고민하고 있습니다.
식스티헤르츠 합류 전 성원님의 커리어를 소개해주세요.
2009년쯤, 아이폰이 막 출시되면서 ‘앱스토어’라는 새로운 플랫폼이 등장했어요. 대학 선배와 함께 “우리도 직접 앱을 만들어보자”는 이야기를 하게 됐고, ‘쓰임epub’라는 회사를 창업해서 저는 CTO 역할로 합류했어요. 사회적으로 의미 있게 쓰이는 서비스를 만들면 좋겠다는 마음을 담은 회사였죠.
이후 회사가 점차 커지면서 한 콘텐츠 회사로 합류하게 되었는데, 그 회사가 지금의 카카오엔터테인먼트에요. 처음에는 iOS 개발자로 시작했고, 이후 웹 개발로 영역을 넓혀 2017년부터는 프론트엔드 개발자로 일을 하였지요. 카카오엔터테인먼트에서의 재직 기간은 약 10년 정도였는데, 그 중 3년 정도는 팀장을 맡아 개발 조직을 이끌었어요.
식스티헤르츠 합류 스토리도 궁금해요.
식스티헤르츠에서 먼저 제안을 주셨고, 당시 저는 카카오엔터테인먼트에서 팀장으로 일하며 큰 프로젝트를 맡고 있어서 처음 제안은 고사했어요. 그런데 신기하게도, 그 프로젝트가 마무리될 즈음 다시 연락이 왔어요. (웃음)
그 시점에 제가 고민하던 게 하나 있었어요. 기술이 상향 평준화되면서, 사람들이 플랫폼을 선택하는 기준이 ‘기술’보다는 ‘콘텐츠’나 ‘도메인 가치’로 옮겨가고 있다는 느낌이었거든요. 점점 내가 기술로 만들어낼 수 있는 임팩트가 줄어든다는 생각도 들었고요. 그때 식스티헤르츠의 ‘재생에너지’라는 도메인이 새롭고 매력적으로 다가왔어요. 아직 제가 경험해보지 못한 분야였고, 성장 가능성과 사회적 임팩트가 분명한 영역이라고 느껴졌기 때문이죠.
재생에너지 도메인은 실제로 와서 보니 어땠나요?
기존에 경험했던 콘텐츠 플랫폼과는 정말 달랐어요. 솔직히 말하면, 기술 환경만 놓고 보면 다소 낙후되어 있다고 말할 수 있고, 최신 기술과 트렌드 자체를 즐기는 개발자라면 처음엔 아쉬울 수도 있는 환경이었던 것이죠.
그런데 저는 결국 중요한 건 내가 가진 기술을 어디에, 어떻게 쓰느냐라고 생각해요. 그래서 그러한 환경이 제약으로 느껴지지는 않았어요. 특히 요즘은 AI 기술이 빠르게 발전하면서, 특정 기술의 난이도보다는 전체 구조를 이해하고 문제를 정의하는 역량이 더 중요해지고 있잖아요. 그런 점에서 보면 이러한 환경이 오히려 시대와 잘 맞는다고 느끼기도 해요. 특정 기술 스택이나 환경에 얽매이지 않고, 현실의 문제 해결에 집중하고 싶은 개발자라면 충분히 의미 있는 도메인이라고 생각해요.
방금 살짝 말씀하신 것 같은데 성원님은 어떤 개발자라고 생각하시나요?
“기술의 깊이보다 문제 해결의 깊이를 더 중요하게 생각합니다.”
저는 고객의 문제를 해결하고, 실제로 결과를 만들어내는 걸 좋아하는 개발자입니다. 팀에서도 늘 “우리는 실용적으로 가자”라는 이야기를 자주 해요.
예전에 학부 시절 근로장학생으로 일하면서 표절 검사용 텍스트 분절 프로그램을 만들어달라는 요청을 받은 적이 있어요. 당시 저는 윈도우 프로그램을 만들 줄 몰랐고, 그래서 콘솔 프로그램으로 간단히 구현했는데 그걸 오랫동안 잘 쓰시더라고요. 만약 그때 “이건 제가 못 해요”, “이 기술은 몰라요”라고 했다면 문제는 해결되지 않았겠죠. 저는 요구사항의 본질에 집중해서, 가능한 방식으로 빠르게 문제를 해결한 거예요.
고객은 ‘왜 필요한지’보다는 ‘무엇이 필요한지’만 이야기하는 경우가 많아요. 그럴 때 개발자가 한 발 더 나서서 문제를 정의하고, 현실적인 해결책을 제안해야 한다고 생각해요. 재생에너지 분야에서도 기본적인 태도는 크게 다르지 않다고 봐요.
성원님과 함께 일하는 식스티헤르츠 개발자들은 어떤 분들인가요?
사업에 관심이 많은 개발자들이 꽤 있어요. 개발자 입장에서는 사업의 전체 맥락을 모르면 혼란스러울 수 있는데, 이를 개발자의 언어로 설명해주는 경우는 많지 않거든요. 저는 개발과 사업 양쪽을 경험해왔기 때문에 제가 개발자의 시선에서 사업 이야기를 공유하면 팀원들이 정말 흥미롭게 듣고 또 서로 의견을 주고받고 있어요.
아 테크 리드들이요? 테크 리드 분들도 정말 자랑스럽죠. 기본적인 개발 역량도 뛰어나지만, 문제가 생기면 어떻게든 파고들어 해결하려는 사람들이에요. 답이 바로 보이지 않아도 결국 답을 만들어내는 사람들, 그래서 신뢰할 수 있는 사람들! 이러한 서로간의 신뢰가 우리팀의 가장 큰 강점이라고 생각해요.
개발팀의 조직 분위기는 어떤가요?
새로운 개발자가 들어오면 항상 하는 이야기가 있어요. “코드와 너무 사랑에 빠지지 말자.”
그래서 ‘코드가 곧 나다’라는 분위기는 없어요. 코드 리뷰에서도 직급과 상관없이 누구나 합리적인 의견을 낼 수 있고, 의견이 갈리면 다른 사람을 더 참여시켜 논의하죠. 그래도 판단이 어려우면, 굳이 내 의견을 끝까지 관철하기보다는 동료의 의견을 존중하자고 이야기해요. 결과가 비슷하다면 팀워크가 더 중요하니까요. 덕분에 지금까지 서로간의 관계로 인한 문제는 거의 없었어요.
앞으로 우리 개발팀이 어떤 팀이 되었으면 하나요?
AI 활용을 더 적극적으로 장려하고 싶어요. 이미 회사 차원에서 여러 도구를 지원하고 있고, 내부적으로도 AI를 활용해 산출물을 만드는 도구를 개발하고 있는데, 앞으로는 이런 흐름을 더 자연스럽게 조직문화에 반영하고 싶어요.
또 하나는 예측 가능한 팀이 되는 것이에요. 회사도 팀도 빠르게 성장하다 보니 조직 안정화가 숙제였는데, 이제는 성과와 결과를 조금 더 예측할 수 있는 팀이 되고 싶어요.
어떤 분이 팀에 합류하면 좋을까요?
고객이 진짜로 해결하고 싶은 문제가 무엇인지 질문하고, 본질을 파악하려는 분이었으면 좋겠어요. “이건 내 문제가 아니다”가 아니라, “내가 해결해보자”라고 생각하는 사람. 스스로를 문제 해결사라고 생각하고, 안 되는 이유를 찾기보다는 어떻게든 해결하려고 노력하는 분과 함께하고 싶어요.
마지막으로, 관심 있는 분들을 위해 성원님은 면접에서 어떤 걸 가장 중요하게 보시는지 알려주세요.
저는 정답이 없는 질문을 많이 해요. 예를 들면 개발자로서의 커리어 방향 같은 질문이요. 저는 개발을 하나의 도구라고 생각하기 때문에, 반드시 정해진 목표가 있어야 한다고 보지는 않아요. 다만 그 사람이 어디까지 바라보며 일하는지, 어떤 고민을 하고 있는지를 알고 싶어요. 그래서 특정한 답을 기대하기보다는, 평소 생각을 솔직하게 이야기해주시는 게 가장 좋아요.
—-------------------
식스티헤르츠는 지금 성장의 다음 단계를 함께 만들어갈 동료를 찾고 있습니다.
“내가 가진 기술로 세상의 문제를 해결하고 싶다면, 식스티헤르츠에 지원하세요.”
🌟 식스티헤르츠 채용공고 보러가기 (click!)
🌟 이메일 지원: recruit@60hz.io
2025년 12월 29일
Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
: PVlib 벡터라이제이션과 데이터 구조 단순화로 이룬 식스티헤르츠의 스케일업
📂서론 | 15만 개의 발전소, 하나의 계산
식스티헤르츠(60Hertz)는 전국 15만 개 이상의 중소규모 재생에너지 발전소로부터 데이터를 수집하고, 이를 기반으로 발전량을 실시간 예측하는 시스템을 운영합니다. 전력망의 안정성을 지키기 위해, 이 예측값은 빠르고 정확하게 계산되어야 합니다.
대부분의 사람들이 ‘발전량 예측’이라고 하면 머신러닝 모델의 정확도를 떠올립니다. 하지만 예측 대상의 규모가 15만 개 정도 수준이 되면 모델의 정확도 뿐만 아니라 “이 계산을 어떻게 제 시간에 끝낼 것인가”도 중요한 문제가 됩니다. 정확도가 아무리 좋다고 하더라도 문제의 규모가 커졌다고 제시간에 답이 나오지 않는 시스템은 전혀 실용적이지 않겠지요. 이런 측면에서 식스티헤르츠의 기존에 사용하던 시스템(이하 v1)은 하루 발전량 예측 계산에 1시간 이상이 소요되었지만, 다음의 철학을 통해 효율적인 스케일업을 이루어냈습니다.
💡 코드 병렬화보다 중요한 것은, 데이터를 한 번에 계산할 수 있는 단순한 구조로 만드는 것.
v1과 달리, 개선한 시스템(이하 v2)은 데이터를 벡터화하고 구조를 단순화하여 동일한 작업을 단 3~5분 만에 끝냅니다. 본 포스트는 어떻게 식스트헤르츠가 위 성과를 이루어낼 수 있었는지를 데이터 엔지니어링 관점에서 설명하고 있습니다.
📂문제 정의 | 15만 번의 루프, 15만 번의 병목
v1에서의 파이프라인은 Apache Airflow를 기반으로 동작합니다. Airflow란 복잡한 데이터 파이프라인을 스케줄링하고 모니터링하는 워크플로우 관리 플랫폼을 말하며, 이를 이용해 15만 개 발전소들의 발전량 예측 작업을 여러 Task로 나누어 관리해왔습니다.
각 Task는 발전소의 메타 데이터와 기상 데이터를 조합해 python의 태양광 발전 시뮬레이션 라이브러리인 PVlib의 ModelChain API를 반복 호출하는 방식을 통해 이루어집니다. ModelChain은 PVlib에서 제공하고 있는 고수준 API로, 태양광 발전 시스템의 물리적 특성(모듈, 인버터 등)과 기상 데이터를 기반으로 발전량을 계산하는 과정을 캡슐화한 객체입니다. 위 API는 단일 발전소에 대한 시뮬레이션을 쉽게 수행할 수 있도록 설계되었으며, 발전량 예측 과정은 다음과 같이 시각화할 수 있습니다.
먼저 15만개의 발전소들을 10개의 그룹으로 만들어 각 그룹별로 Task가 병렬로 이루어지도록 합니다. 각 그룹 내에서는 1.5만개 발전소를 for-loop로 순회하며 직렬 형태로 ModelChain을 반복호출하게 됩니다. 즉, 병렬처럼 보여도 실상은 루프의 반복이 전체 시간을 지배했습니다. 위 아키텍쳐에서 병목 현상을 유발한 요인은 다음과 같이 정리할 수 있습니다.
계산 과정에서의 병목
데이터 관점에서 병목
데이터 I/O 관점에서 병목
이제 이 각각의 요인들이 어떻게 병목현상을 야기했는지, 그리고 어떻게 기술적으로 해결했는지 하나씩 살펴보도록 하겠습니다.
a. 계산 과정에서의 병목: 고수준 API인 ModelChain 을 변환하다
PVlib은 태양광 발전 시뮬레이션 표준 라이브러리로, 고수준 API(ModelChain)와 저수준 API 두 가지를 제공합니다. 각각의 API는 아래 표와 같이 정리할 수 있습니다.
고수준 API | 저수준 API | |
적용된 시스템 | v1 | v2 |
특징 | 태양광 발전 시스템 전체를 시뮬레이션 하는데 필요한 세부 단계들을 캡슐화하여 | 시뮬레이션의 각 세부 단계들을 구성하는 |
적합한 문제 | 단일 발전소 발전량 예측에 적합 | 대규모 발전소 발전량 예측에 적합 |
PVlib 내 | ModelChain | pvlib.irradiance |
장점 | 사용이 간편하며, 기본적인 시뮬레이션을 | 세밀한 제어가 가능하고, 대규모 데이터 |
단점 | 내부 로직이 숨겨져 있어 세부적인 제어가 | 사용자가 직접 시뮬레이션의 모든 단계를 |
고수준 API인 ModelChain은 단일 발전소 발전량 예측에 적합하지만, 15만개 발전소를 처리할 때는 15만 번의 객체 생성이 필요하여 지속적인 오버헤드를 유발합니다. 고수준 API 기반의 코드 예시는 다음과 같으며, python-level에서의 for loop을 중점적으로 사용하는 것을 확인할 수 있습니다.
results_v1 = [] for plant in plant_meta: mc = pvlib.modelchain.ModelChain(plant.system, plant.location) weather = weather_data_map[plant.id] mc.run_model(weather) results_v1.append(mc.results.ac)
반면 단순한 수학 함수로 구성된 저수준 API는 배열 전체를 한 번에 처리할 수 있어 대규모 데이터 처리에 적합합니다. 아래 코드를 비교해보시면 아시겠지만, python에서의 for-loop문이 완전히 사라진 것을 확인할 수 있습니다. python에서의 for-loop는 다음 단락에서 설명할 벡터화 연산의 이점을 이용할 수 없기 때문에 태생적으로 느릴 수 밖에 없습니다. 1.44억(=15 만개의 발전소 x 96 번)번의 연산이 저수준 API를 통해 벡터라이제이션됨으로써 C-level에서의 벡터화가 적용되어 빠르게 처리됨을 의미합니다.
tilt = plant_meta['tilt'].to_numpy() azimuth = plant_meta['azimuth'].to_numpy() dni = weather_data['dni'].reshape(150000, 96) ghi = weather_data['ghi'].reshape(150000, 96) tilt_b = tilt[:, np.newaxis] azimuth_b = azimuth[:, np.newaxis] total_irrad = pvlib.irradiance.get_total_irradiance( surface_tilt=tilt_b, surface_azimuth=azimuth_b, dni=dni, ghi=ghi ) final_ac_power = pvlib.pvsystem.sapm( effective_irradiance=total_irrad )
b. 데이터 관점에서의 병목: 벡터화를 통한 데이터 처리속도 향상
Pandas와 NumPy는 내부적으로 C언어 수준(이하 C-level)의 벡터 연산을 사용하여 빠른 계산 성능을 제공하며, groupby 역시 이에 최적화된 연산입니다. 하지만 v1에서는 발전소들을 묶는 과정에서 agg(list)를 사용해 데이터를 리스트화했습니다. 이로 인해 메모리상에 동일한 변수형이 연속적으로 배치되어야 하는 NumPy 배열의 구조적 장점이 깨지게 되었습니다. 그 결과 배열 내 값들이 불가피하게 object 타입으로 변환되면서 벡터화의 이 점을 완전히 잃게 되었습니다.
데이터가 벡터화로 구성이 되면 다음의 이유로 성능이 매우 빨라지게 됩니다.
먼저 데이터 형식이 동일하면, SIMD(Single Instruction, Multiple Data) 기술을 활용하여 CPU가 단 한 번의 명령어로 여러 데이터(레지스터 단위)를 동시에 처리하여 물리적인 연산 속도를 획기적으로 높입니다.
또한, Python 인터프리터는 동적 타이핑 언어 특성상, 반복문을 돌 때마다 변수의 타입을 확인하고 적절한 연산 함수를 찾는 과정인 Dispatching을 거칩니다. 반면, 벡터화된 NumPy 배열은 생성 시점에서 동일한 변수형이 보장이 되기 대문에 연산을 시작하기 전에 한 번만 타입을 검사하며, 이후에는 별도의 확인작업 없이 기계어 레벨에서 값을 밀어넣기 때문에 오버헤드가 0에 수렴합니다.
마지막으로 데이터가 메모리에 연속적으로 배치되기 때문에 v1처럼 주소(Pointer)를 따라 여기저기 메모리를 찾아다는 비용인 Dereferencing cost가 줄어들고, CPU 캐시 적중률이 극대화되며, 컴파일러가 자동으로 병렬화 최적화를 수행할 수 있습니다.
다음은 v1에서 사용한 예제 코드입니다.
# v1: C-level 연산을 포기하게 만드는 코드 grouped = df.groupby('plant_id')['ghi'].agg(list) print(grouped.dtype) # dtype('O') → object 타입
C-level에서의 연산은 데이터가 동일한 타입의 데이터가 연속된 메모리 블록에 저장되어 있을 때 가능합니다. 예를 들어, int64 로 구성된 배열은 실제값들이 빈틈없이 붙어있는 형태이며, 첫 번째 값의 주소만 알면 “여기서 부터 1000개의 값을 더해라”와 같은 명령을 단 한 번의 CPU 명령어로 처리할 수 있습니다.
하지만 object 타입으로 구성된 배열은 데이터가 아닌 데이터의 주소를 저장하게 됩니다. 실제 데이터는 메모리 여기저기에 흩어진 상태이며, 각 데이터의 타입도 제각각일 수 있습니다. 이렇게 되면 C-level 연산이 어려워져 속도가 느린 Python 인터프리터가 개입하게 되고, 이로 인해 비효율적인 연산 방식을 수행하게 됩니다.
v1의 경험이 남긴 교훈은 단순했습니다.
복잡한 병렬 처리로 비효율적인 구조를 보완하려 하지 말라. 데이터를 단순하게 만들어라.
이를 기반으로 새로 개선한 v2의 철학은 세 가지였습니다.
루프 제거: Python for 루프를 없앤다.
벡터화: NumPy 브로드캐스팅을 활용한다.
구조 단순화: 중첩 list 대신 2D long-form 구조 사용.
v1이 “15만 개 발전소 객체”를 다뤘다면, v2는 “15만 개의 발전소 정보가 동일한 형태로 줄지어 저장된 tilt, azimuth 배열”을 다룹니다. 데이터 중심의 설계로 전환하면서 코드 구조가 근본적으로 달라지게 된 것입니다.
c. 데이터 I/O 관점에서의 병목: CPU보다 느린 건 데이터였다
저수준 API를 통해 엄청난 속도의 발전을 이루었지만, 데이터 I/O에서의 문제가 남아있었습니다. 기존 v1 방식은 각 발전소 루프마다 필요한 기상예보데이터(NWP; Numerical Weather Prediction)를 개별 Parquet 파일에서 읽어왔습니다. 15만 개의 발전소가 10개의 Task로 나뉘어져 있어도, 각 Task 내에서는 1.5만 번의 파일 접근을 시도하여, 엄청난 I/O 병목을 유발하였습니다. 쉽게 설명하자면 택배로 보낼 물품 1.5만개를 한 대의 오토바이 퀵서비스로 반복적으로 보내고 받는 것과 다르지 않습니다. v2방식은 1) 인덱스 기반 조회와 2) 대량 데이터 전송(예: fetch_df_all()) 방식을 통해 택배차 한 대가 1000개의 택배를 한꺼번에 운송하는 방식과 비슷하게 문제를 해결했습니다.
먼저 모든 NWP 기상 데이터를 Oracle DB에 저장한 뒤, 15만 개 발전소의 위치 인덱스를 활용해 단일 SQL 쿼리에서 필요한 데이터를 한 번에 조회할 수 있도록 구조를 개선했습니다. 이를 통해 쿼리 단위를 통합해 네트워크 왕복 횟수를 최소화하고 I/O 과정에서의 효율을 크게 높였습니다.
또한, execute() 나 executemany() 등의 대용량 데이터 I/O에 적합하지 않은 표준 Python DB-API 방식 대신, Apache Arrow 기반의 python-oracledb DataFrame API를 사용했습니다. 이 방식은 DB에서 읽어온 대량의 데이터를 즉시 NumPy 배열로 변환하여, Python 객체 생성 오버헤드를 건너뛰고 제로카피에 가까운 메모리 효율을 달성합니다. 위 과정을 시각화하면 다음과 같습니다.
📂숫자로 증명된 구조의 힘
위의 세 병목 현상을 해결하여 v2방식은 데이터 로딩 속도만 수십 배 향상시켰고, 이는 전체 파이프라인 처리 시간 단축에 결정적으로 기여했습니다. 데이터 처리 방식을 v1에서 v2로 바꾸면서, 다음의 성능을 달성했습니다.
구분 | 방식 | 처리 시간 | 코드 라인 수 |
|---|---|---|---|
v1 | 발전소별 Python for-loop | 1시간 이상 | ~1200 |
v2 | 벡터 연산에 최적화된 데이터 구조 | 3분 내외 | ~400 |
v2는 24 코어를 모두 활용하며 3분 만에 계산을 완료함으로써 약 20배의 성능 향상을 달성했습니다. 하지만 여기서 더 주목해야 하는 것은 코드 라인의 수입니다. 복잡한 병렬처리, 예외 처리, 데이터 파편화로 가득했던 1,200개 라인의 코드가, 데이터 구조를 단순화하자 400개 라인의 명료한 벡터 연산 코드로 바뀌었습니다. 성능과 유지보수성, 두 마리 토끼를 모두 잡은 것 입니다.
📂이런 문제를 풀고 싶으시다면..
현장에서는 서비스가 어떻게 돌아가는지 뿐만 아니라 얼마나 잘 돌아가는지도 중요합니다. 그리고 상품화의 대상 및 문제 공간이 확대가 되면서 폭넓은 통찰 또한 필요합니다. 이러한 흐름 속에서 식스티헤르츠는,
단순한 데이터 수집이나 ML 모델을 학습시키는 것이 아닌, 문제의 본질을 이해하는 엔지니어를 원합니다.
15만 개의 수준의 거대한 데이터를 다룰 때 어떤 방식이 더 빠르고 효율적인지, 그 근본적인 원리를 이해하고 최적의 구조를 선택할 수 있는 분을 찾습니다.
단순히 데이터를 불러오는 것에 그치지 않고, 어떻게 하면 불필요한 네트워크 왕복 횟수를 최소화하여 전체 시스템의 속도를 높일 수 있을지 치열하게 고민하는 분을 원합니다.
여러 작업을 동시에 처리하는 방식과 거대한 데이터를 한 번에 계산하는 방식의 차이를 명확히 이해하고, 상황에 맞게 적절한 해결책을 제시할 수 있는 분과 함께하고 싶습니다.
우리는 코드가 '돌아가는 것'에 만족하지 않고, '왜 이렇게 돌아가야만 하는지', 그리고 ‘현재보다 더 효율적인 방법은 없는지’를 끊임없이 질문하는 엔지니어와 함께 스케일업의 한계를 넘고 싶습니다.
계산 최적화는 왜 중요할까요?
빠른 계산은 곧 효율적인 서버 운영을 의미하고, 효율적인 서버 운영은 에너지 절약으로 이어집니다. 1시간 걸리던 작업을 3분으로 줄이면, 그 차이인 57분만큼의 서버 리소스를 아낄 수 있습니다. 이것이 바로 고도화된 IT 기술과 정교한 데이터 아키텍처가 곧 탄소 효율로 이어지는 방식입니다.
식스티헤르츠는 '데이터로 에너지를 절약하는 회사'입니다. 이 거대하고 의미 있는 계산에 동참하고 싶다면, 지금 바로 식스티헤르츠의 문을 두드려 주시기 바랍니다.
——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2 (방금 읽은 글이에요)
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 12월 10일
Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
: 온프레미스 대규모 데이터 처리 아키텍처 구축기
저희 팀은 최근 전국 15만 개소 이상의 중소규모 재생에너지 발전소로부터 실시간으로 데이터를 수집하고, 이를 기반으로 발전량을 예측하고 모니터링하는 시스템을 온프레미스(On-premises) 환경에 성공적으로 구축했습니다. 클라우드 환경이 대세인 요즘, 고객사의 보안 정책과 데이터 소유권 문제로 인해 온프레미스 환경에 대규모 시스템을 설계하는 것은 저희에게도 큰 과제였습니다.
해결해야 할 과제들
프로젝트의 목표는 안정성과 확장성 두 가지로 압축되었습니다.
안정적인 데이터 수집
15만 개의 RTU(Remote Terminal Unit)는 LoRa, NB-IoT, HTTPS 등 서로 다른 통신망과 프로토콜을 사용합니다. 이를 단일 시스템으로 통합하여 데이터 유실 없이 수집해야 했습니다.
실시간 처리와 스케일 아웃
수집된 데이터는 즉시 처리되어야 하며, 향후 발전소 증가에 유연하게 대응할 수 있도록 모든 컴포넌트는 수평 확장(Scale-out)이 가능한 구조로 설계되어야 했습니다.
복합 분석 기능
단순 수집을 넘어, 외부 기상 데이터와 결합한 발전량 예측 및 실측치 비교를 통한 이상 감지 기능이 요구되었습니다.
보안 및 고가용성(HA)
외부 공격 방어는 물론, 일부 서버 장애 시에도 서비스 연속성을 보장하는 고가용성 아키텍처가 필수였습니다.
기술 스택 선정 - 왜 이 기술들을 선택했을까?
리액티브 스택을 선택한 이유
대규모 IoT 데이터 처리를 앞두고 가장 먼저 고민한 것은 동시성 처리 방식이었습니다. 전통적인 서블릿 기반의 Spring MVC도 충분히 검증된 기술이지만, 15만 개소에서 동시에 쏟아지는 연결을 처리하기에는 스레드 모델의 한계가 명확해 보였습니다.
그래서 저희는 Spring WebFlux를 선택했습니다. 비동기-논블로킹(Asynchronous Non-blocking) 방식으로 동작하는 WebFlux는 적은 수의 스레드로도 대량의 동시 연결을 처리할 수 있었습니다.
WebFlux를 선택한 결정적인 이유는 세 가지였습니다.
이벤트 루프 방식으로 수만 개의 연결을 동시에 처리할 수 있는 높은 동시성.
Reactor의 Flux/Mono를 통해 데이터 생산자와 소비자 간 속도 차이를 자동으로 조절하는 백프레셔(Backpressure) 지원.
스레드 기반 모델보다 더 적은 리소스로 동작하는 메모리 효율성이었습니다.
Kafka를 통한 이벤트 처리
Apache Kafka를 도입한 것은 이번 프로젝트에서 가장 중요한 아키텍처 결정 중 하나였습니다. 15만 개소에서 동시에 쏟아지는 데이터를 안정적으로 받아내기 위해 Kafka를 선택했습니다.
Kafka는 단순한 메시지 큐 이상의 역할을 담당했습니다. 순간적으로 폭증하는 트래픽을 버퍼링하고, 수집 시스템과 처리 시스템을 분리(Decoupling)함으로써 각 컴포넌트가 독립적으로 확장되고 장애에 대응할 수 있게 해줬습니다.
또한, 토픽 설계는 신중하게 진행했습니다. IoT Platform A, B, C, HTTPS 등 프로토콜별로 토픽을 분리해 각 채널의 특성에 맞게 독립적으로 관리할 수 있도록 했습니다. 각 토픽은 6개의 파티션으로 구성하여 병렬 처리 능력을 확보했고, 복제 계수를 3으로 설정하여 브로커 장애 시에도 데이터를 안전하게 보호했습니다. 메시지는 7일간 보관되도록 설정하여, 만약의 장애 상황에서도 충분한 복구 시간을 확보했습니다.
아키텍처 설계 - 데이터는 어떻게 흐르는가?
기술 스택을 정했으니, 이제 이것들을 어떻게 조합할 것인지 고민할 차례였습니다. 저희는 데이터의 흐름을 따라 시스템을 크게 4개 영역으로 나누어 설계했습니다.
1. 데이터 수집 영역
전국 각지에 흩어진 발전소의 RTU 장비에서 보낸 데이터가 시스템으로 유입되는 진입점입니다. 방화벽과 L4 스위치를 거쳐 수집 서버로 전달된 데이터는, 여기서 프로토콜별로 정제되어 Kafka로 발행됩니다.
Data Collector
Spring WebFlux 기반의 비동기 서버로, 다양한 IoT 프로토콜을 표준화된 내부 포맷으로 변환합니다.
reactor-kafka를 사용하여 논블로킹 메시지 발행을 구현했으며, Reactor의 백프레셔 기능을 통해 Kafka 클러스터로 가는 부하를 조절합니다. 컨테이너 기반으로 설계되어 트래픽 증가 시 즉각적인 확장이 가능합니다.
2계층 로드밸런싱: L4 스위치와 Nginx, Docker
클라우드의 관리형 로드밸런서가 없는 온프레미스 환경에서 고가용성과 확장성을 확보하기 위해, 하드웨어 L4 스위치와 소프트웨어 로드밸런서를 계층화하여 유연한 트래픽 분산을 구현했습니다. 외부에서 들어오는 트래픽은 먼저 L4 스위치가 여러 대의 서버로 분산하고, 각 서버 내부에서는 Nginx가 Docker 컨테이너로 패키징된 수집 서버 인스턴스들에게 요청을 분배합니다.
하드웨어 스위치가 네트워크 레벨의 빠른 분산과 헬스체크를 담당하고, Nginx가 애플리케이션 레벨의 세밀한 라우팅을 담당하는 역할 분리가 핵심입니다.
Nginx는 Least Connections 방식으로 현재 활성 연결 수가 가장 적은 인스턴스에 요청을 전달하며, Passive Health Check를 통해 실패한 인스턴스를 자동으로 제외합니다.
upstream collector_api_server1 { least_conn; server collector-api-1:8081 max_fails=3 fail_timeout=30s; server collector-api-2:8081 max_fails=3 fail_timeout
Nginx 설정은 코드로 관리되어 버전 관리가 가능하고, 컨테이너 스케일 아웃 시 설정만 변경하면 됩니다. 이 패턴은 WEB/WAS 서버에도 동일하게 적용했습니다.
2. 이벤트 허브 영역
Kafka 토픽 설계는 단순해 보이지만, 실제로는 많은 고민이 필요한 부분입니다. 저희는 프로토콜별로 토픽을 분리하여 각 채널이 서로 영향을 주지 않도록 격리성을 확보하면서도, 파티셔닝을 통해 확장성도 함께 확보했습니다.
토픽 네이밍은 일관된 컨벤션을 따랐습니다. {namespace}.collector.{platform}.raw-data 형태로 명명하고, Event Contracts 모듈에서 모든 토픽 이름을 상수로 중앙 관리했습니다.
파티셔닝 전략도 중요했습니다. 각 토픽을 6개 파티션으로 나누어 컨슈머가 병렬로 처리할 수 있도록 했습니다. 파티션 리밸런싱 기능 덕분에 컨슈머가 추가되거나 제거될 때도 부하가 자동으로 재분배됩니다.
3. 데이터 중계 및 저장 영역
Kafka에 쌓인 데이터를 이제 안전하게 내부망의 데이터베이스로 옮겨야 합니다. 보안을 위해 DMZ에 중계 서버를 두고, 여기서 Kafka 메시지를 소비해 내부망 DB에 저장하는 구조로 설계했습니다.
컨슈머 처리 로직
컨슈머 모듈은 Kafka 메시지를 소비하여 DB에 저장하는 역할을 합니다. 가장 먼저 집중한 부분은 배치 처리 최적화였습니다. 메시지를 개별적으로 처리하지 않고 배치(Batch) 단위로 묶어서 DB에 저장하도록 했는데, 최대 1,000개 메시지를 한 번에 가져오며 최소 1MB 데이터가 모이거나 3초가 경과하면 배치 처리를 수행합니다. 이 방식으로 DB Insert 성능을 크게 향상시킬 수 있었습니다.
처리량을 극대화하기 위해 컨슈머 그룹도 적극 활용했습니다. 6개의 파티션을 6개의 컨슈머가 병렬로 소비하며, 각 컨슈머는 독립적으로 메시지를 처리합니다.
안정성을 위한 재시도 및 에러 핸들링도 중요했습니다. 일시적인 오류 시에는 1초 간격으로 최대 3번 재시도하며, 배치 저장 실패 시에는 개별 저장으로 fallback하여 가능한 많은 데이터를 보존하도록 했습니다. 그래도 실패하는 데이터는 별도의 오류 테이블에 저장하여 추후 분석할 수 있도록 했습니다.
4. 발전량 예측 및 분석 영역
단순히 데이터를 쌓는 것만으로는 가치를 만들기 어렵습니다. 분석 예측 서버는 수집된 데이터를 분석하고 예측하는 역할을 합니다.
분석 예측 서버는 Dagster 기반 워크플로우 오케스트레이션을 사용합니다. Dagster를 활용해 데이터 파이프라인의 스케줄링과 실행을 관리하며, 데이터 수집, 전처리, 예측 실행을 하나의 워크플로우로 통합했습니다. 파이프라인 실행 이력과 의존성도 체계적으로 관리했습니다.
예측 정확도를 높이기 위해서는 외부 데이터 연동이 필수적이었습니다. Python 분석 파이프라인이 NOAA NWP(수치예보모델)를 통해 기상 예보 데이터를 수집하며, 태양광 발전에 영향을 미치는 기상 요소를 확보했습니다. 발전량 예측 모델은 과거 발전 실적 데이터와 기상 데이터를 결합하여 미래 발전량을 예측하고, 그 결과는 데이터베이스에 저장되어 분석 및 리포팅에 활용됩니다.
5. 웹 서비스 제공 영역
사용자들이 발전소 상태를 모니터링하고 시스템을 제어하는 웹 서비스 영역입니다.
웹 서비스는 전형적인 3-Tier 아키텍처로 구성했습니다. 가장 앞단의 WEB 계층에서는 정적 리소스 서빙과 SSL/TLS 터미네이션을 담당하며, L4 스위치를 통해 2대의 서버로 로드 밸런싱합니다. 들어온 요청은 WAS 서버로 프록시됩니다.
WAS 계층은 3대의 Application Server로 구성되어 고가용성을 확보했습니다. 여기서 동작하는 Business API Service는 Spring Boot 기반의 RESTful API 서버로, 모니터링 서비스의 핵심 비즈니스 로직을 처리합니다. 무중단 서비스는 필수 요구사항이었습니다. Oracle RAC Active-Active 클러스터로 DB를 이중화하고, 모든 계층에서 최소 2대 이상의 서버를 운영하며 L4 로드 밸런싱을 구성했습니다. Docker 기반 구성 덕분에 장애 발생 시에도 빠르게 복구할 수 있습니다.
배치 계층은 Spring Batch를 활용해 정기적인 통계 집계와 리포트 생성 같은 대용량 데이터 처리 작업을 수행합니다.
수집 서버 클러스터 성능 검증: 12,000 TPS 달성
아키텍처 설계가 실제 대규모 트래픽 환경에서 유효한지 검증하기 위해 강도 높은 부하 테스트를 수행했습니다. 단순 산술 계산으로 접근하면 15만 개의 장비가 60초 동안 균등하게 데이터를 전송한다고 가정했을 때, 필요한 처리량은 약 2,500 TPS입니다.
150,000 Requests / 60 Seconds = 2,500 TPS
하지만 실제 환경에서는 장비들이 완벽하게 분산되지 않습니다. 많은 설비들이 동시에 데이터를 전송하는 트래픽 스파이크가 빈번하게 발생하기 때문입니다. 클라이언트 측에 지연 로직이 없다면 서버는 순간적으로 10,000 TPS 이상의 폭주 트래픽을 감당해야 할 수도 있습니다. 저희는 이러한 트래픽 서지(Surge)를 고려하여, 평균 대비 약 4~5배의 예비 용량을 확보하는 것을 목표로 삼았습니다.
Grafana k6를 이용한 부하 테스트 결과 단일 노드 기준 초당 3,000건의 수집 요청(3,000 TPS), 전체 클러스터 기준 초당 12,000건(12,000 TPS)의 수집 요청을 지연 없이 안정적으로 처리하는 것을 확인했습니다. Spring WebFlux의 Non-blocking 구조와 Kafka를 통한 트래픽 버퍼링, 그리고 컨슈머의 Batch Insert 전략이 유기적으로 동작하여, 이론적 피크치를 상회하는 부하 상황에서도 데이터 유실 없이 안정적인 처리가 가능함을 증명했습니다.
회고 - 우리가 배운 것들
비동기-논블로킹의 이점
Spring WebFlux를 실전에 적용하면서 대규모 IoT 환경에서 리액티브 프로그래밍의 장점을 확인할 수 있었습니다. 적은 리소스로 높은 처리량을 달성하는 것은 물론, 백프레셔 제어를 통해 시스템 전체의 안정성을 확보할 수 있었습니다.
Kafka는 단순한 메시지 큐가 아니다
Kafka를 도입하면서 이벤트 스트리밍 플랫폼의 진가를 알게 되었습니다. 단순히 메시지를 전달하는 것을 넘어, 시스템 간 결합도를 낮추고 장애 격리를 가능하게 하며, 데이터를 일정 기간 보관해 재처리를 가능하게 하는 등 아키텍처 전반의 안정성을 높이는 중요한 컴포넌트였습니다.
확장성은 처음부터 고려해야 한다
수평 확장이 가능한 구조로 설계한 덕분에, 트래픽이 증가해도 서버를 추가하는 것만으로 대응할 수 있었습니다. 컨테이너 기반 아키텍처와 Kafka의 파티셔닝 메커니즘이 이를 가능하게 했습니다.
온프레미스에서도 유연한 인프라 구성이 가능하다
클라우드 없이도 L4 스위치와 Nginx를 계층화하여 충분히 유연한 로드밸런싱을 구현할 수 있었습니다. 중요한 것은 각 계층의 역할을 명확히 분리하고, 설정을 코드로 관리하는 것이었습니다.
마무리하며
온프레미스 환경에서 15만 개소의 실시간 데이터를 처리하는 시스템을 구축하는 여정은 쉽지 않았습니다. 클라우드 매니지드 서비스가 제공하는 편리함 대신, 하드웨어 선정부터 네트워크 망 분리, 각 서버의 역할 정의와 이중화 구성까지 모든 단계를 저희 손으로 직접 결정하고 구축해야 했습니다.
하지만 그만큼 배운 것도 많았습니다. 대규모 트래픽을 안정적으로 처리하기 위한 Spring WebFlux와 Kafka의 활용, 그리고 Nginx와 Docker를 활용한 소프트웨어 로드밸런싱을 통해 유연한 아키텍처를 구성해 본 것은 저희 팀의 큰 자산으로 남게 되었습니다.
이 글이 온프레미스 환경에서 대규모 트래픽 처리를 고민하는 엔지니어분들에게 작은 도움이 되기를 바랍니다.
——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1 (방금 읽은 글이에요)
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 12월 3일
Tech
단일책임원칙(SRP)을 충족하는 React 개발
혹시 SOLID 원칙에 대해 들어보셨나요?
개발을 접하신 분이라면 자세히는 몰라도 한 번쯤 이름은 들어보셨을 거예요.
SOLID 원칙은 객체지향 설계에서 지켜야 할 다섯 가지 소프트웨어 개발 원칙(SRP, OCP, LSP, ISP, DIP)을 말합니다.
SRP (Single Responsibility Principle): 단일 책임 원칙
OCP (Open Closed Principle): 개방 폐쇄 원칙
LSP (Liskov Substitution Principle): 리스코프 치환 원칙
ISP (Interface Segregation Principle): 인터페이스 분리 원칙
DIP (Dependency Inversion Principle): 의존 역전 원칙
이런 원칙들을 지키면 좋은 객체지향 설계에 가까워질 수 있습니다.
그런데 프론트엔드 개발자, 특히 React를 사용하는 분들이라면 이런 생각이 들 수도 있습니다.
“객체지향 원칙을 함수 기반 React에 어떻게 적용하지?”
식스티헤르츠는 관리자 도구, 대시보드, 사용자 웹 서비스 등 다양한 영역에서 React를 활용하고 있습니다.
React는 빠르고 선언적인 개발을 가능하게 하지만, 동시에 SOLID 같은 설계 원칙을 놓치기 쉬운 환경이기도 합니다.특히 일정에 쫓기다 보면 "일단 되게 만들고 나중에 리팩토링하자"는 생각으로 컴포넌트 하나에 API 호출, 상태 관리, 비즈니스 로직, UI 렌더링을 모두 집어넣게 됩니다. 당장은 빠르게 느껴지지만, 시간이 지나면 그 '나중'은 오지 않고 코드는 점점 더 복잡해집니다. 결국 새로운 기능을 추가할 때마다 기존 코드를 건드리기 두려워지고, 수정 대신 코드를 추가하는 방식으로 문제를 회피하게 되죠.
사실 저는 주니어 개발자 시절부터 꽤 오랫동안 설계 원칙에 갇혀 있었습니다. 하나의 원칙을 프로젝트에 적용하면 그것을 엄격하게 지키려고만 했지, '왜 지켜야 하는가'에 대해서는 제대로 생각하지 못했어요. 그러다 보니 오히려 원칙을 지키는 게 불편해지고, 어느 순간부터는 원칙을 의도적으로 멀리하게 됐습니다. 코드를 작성하는 데 불편하고 시간도 오래 걸렸거든요. 막상 코드를 작성하고 나면 그렇게 마음에 들지도 않았어요.
하지만 원칙을 멀리한 채 개발하다 보니, 오히려 다시 원칙을 찾게 되는 상황들이 생겼습니다. 왜일까요? 개발 원칙에는 좋은 소프트웨어를 만들기 위한 개발 철학이 담겨있기 때문입니다. 나보다 먼저 이 길을 걸은 개발자들의 고민과 해결 방법들이 개발 원칙으로 만들어진 것이죠. 구체적인 지침 자체는 내 상황에 맞지 않을 수 있어도, 그 지침이 만들어지기까지의 철학은 어떤 소프트웨어 개발에도 유효할 수 있습니다. 한 발 물러서서 개발 원칙을 바라보니, 필요한 시점에 필요한 철학을 적절히 적용할 수 있게 되었습니다.이 글에서는 그런 문제의식에서 출발해, SOLID의 첫 번째 원칙인 SRP(단일 책임 원칙)를 React 코드에 어떻게 적용할 수 있는지 살펴보려 합니다
단일 책임 원칙의 철학
단일 책임 원칙(SRP)의 핵심은 간단합니다. "하나의 모듈(클래스, 함수, 컴포넌트)은 하나의 책임만 가져야 한다." 여기서 '책임'이란 '변경의 이유'를 의미합니다. 로버트 C. 마틴은 이를 "하나의 모듈은 하나의, 오직 하나의 액터(사용자)에 대해서만 책임져야 한다"고 표현했습니다.
왜 이게 중요할까요? 여러 책임이 하나의 모듈에 섞여 있으면, 한 가지를 수정할 때 다른 것까지 영향을 받게 됩니다. 책임이 명확하게 분리되어 있으면 변경의 파급 효과를 최소화할 수 있고, 코드를 이해하고 테스트하기도 훨씬 쉬워집니다.
실생활에서의 단일 책임 원칙
우리가 개발 과정을 설명할 때 자동차를 예시로 자주 사용합니다. 자동차는 각 책임 단위인 부품으로 잘 분리되어 있습니다. 에어컨이 고장나면 에어컨만 수리하면 되고, 브레이크가 고장나면 브레이크만 교체하면 됩니다. 각 부품에 문제가 생겼을 때 해당 부품만 손보면 되는 구조죠.
그렇다면 단일 책임 원칙을 지키지 못해 에어컨, 브레이크, 엔진이 하나의 통합 모듈로 결합되어 있다면 어떻게 될까요? 에어컨 필터만 교체하려 해도 전체 모듈을 분해해야 합니다. 작업 중 실수로 브레이크 라인을 건드려 브레이크액이 샐 수도 있고, 엔진 배선을 잘못 만져 시동이 걸리지 않을 수도 있습니다. 단순한 에어컨 필터 교체가 브레이크나 엔진 같은 핵심 기능에 문제를 일으킬 위험이 생기는 거죠. 당연히 수리 시간도 길어지고, 비용도 훨씬 비싸집니다.
여기에 에어컨 부품이 개선되어 새로운 에어컨 부품이 개발되었다고 해볼까요? 별도 모듈로 사용하고 있다면 브레이크와 엔진은 기존 부품을 그대로 사용하면 되는데, 모듈이 결합되어 있기 때문에 새 에어컨 부품을 사용하기 위해서는 새 에어컨, 브레이크, 엔진이 결합된 새로운 모듈을 만들어 사용해야 합니다. 기존 모듈은 더이상 사용할 수 없어지겠죠.
소프트웨어 개발도 마찬가지입니다. 단일 책임 원칙을 지키지 못한다면 동일한 문제가 발생합니다.
작은 수정에도 큰 비용이 발생합니다 (유지보수 비용 증가)
코드 수정 중 예상치 못한 사이드 이펙트가 발생합니다
수정이 두려워 코드를 수정하기보다는 코드를 추가하게 되고, 코드가 점점 복잡해집니다
코드 재사용이 어려워집니다. (여러 책임이 얽혀있기 때문에)
결국 단일 책임 원칙은 유지보수 비용을 줄이면서, 자연스럽게 재사용성도 높여주는 중요한 원칙입니다. React에서는 컴포넌트 재사용 빈도가 높기 때문에 단일 책임 원칙을 지키면 재사용성 측면에서 큰 이점을 만들어낼 수 있습니다.
React 개발에서 SOLID 원칙을 놓치기 쉬운 이유
식스티헤르츠는 React를 주로 관리자 도구와 대시보드, 그리고 사용자 대면 웹 서비스 개발에 사용하고 있습니다. 개발 업무 중 웹 개발이 차지하는 비중이 많기 때문에 javascript를 적극적으로 활용하게 되고, 속도와 유지보수성을 모두 살리기 위해 선언적 개발을 가능하게 만들어주는 React를 주로 활용하고 있습니다. 여러 상황에서 React는 훌륭한 선택이지만, 동시에 SOLID 원칙 같은 설계 원칙을 간과하게 만드는 특성도 가지고 있습니다.
JavaScript와 React는 강력한 자유도를 제공합니다. 함수 안에서 무엇이든 할 수 있으며, 컴포넌트 하나에 로직과 UI를 모두 담을 수 있습니다. 이런 자유로움 덕분에 빠르게 기능을 구현할 수 있지만, 역설적으로 '잘못된 설계'도 쉽게 만들어집니다. Java나 C# 같은 언어에서는 클래스 구조와 타입 시스템이 어느 정도 설계를 강제하지만, React에서는 모든 것이 '함수'이기 때문에 책임의 경계가 흐려지기 쉽습니다.
특히 일정에 쫓기다 보면 "일단 되게 만들고 나중에 리팩토링하자"는 생각으로 컴포넌트 하나에 API 호출, 상태 관리, 비즈니스 로직, UI 렌더링을 모두 집어넣게 됩니다. 당장은 빠르게 느껴지지만, 시간이 지나면 그 '나중'은 오지 않고 코드는 점점 더 복잡해집니다. 결국 새로운 기능을 추가할 때마다 기존 코드를 건드리기 두려워지고, 수정 대신 코드를 추가하는 방식으로 문제를 회피하게 되죠.
React 개발에서 '책임'이란?
React 개발은 결국 함수 개발이라고 할 수 있습니다. 비즈니스 로직은 말할 것도 없이 함수로 개발하고 UI조차도 함수로 개발하는 특징을 갖고 있죠. 그리고 함수가 하는 일이 곧 책임입니다. 그래서 React에서의 책임은 ‘함수가 어떤 비즈니스 로직을 수행하는가' 뿐만 아니라 ‘어떤 UI를 어떻게 그려내는가’를 포함한다고 할 수 있습니다.
React에서 단일 책임 원칙 지키기
1. 비즈니스 로직과 UI 분리
가장 먼저 책임을 분리할 수 있는 지점은 비즈니스 로직과 UI를 분리하는 것입니다. React는 비즈니스 로직과 UI를 모두 함수로 표현하기에 이를 합쳐서 사용하게 되는 경우가 많습니다.
// 책임이 섞여있는 컴포넌트 function MyProfile() { const [myInfo, setMyInfo] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/me') .then(res => res.json()) .then(data => setMyInfo(data)) .finally(() => setLoading(false)); }, []); if (loading) return <Spinner />; return ( <div className="profile"> <img src={myInfo?.avatar} /> <h1>{myInfo?.name}</h1> <p>{myInfo?.email}</p> </div> ); }
간단하게 예를 들어 위와 같은 `MyProfile` 컴포넌트가 있다고 해보겠습니다. 언뜻 보기에는 내 정보를 화면에 보여주는 단일 책임 컴포넌트처럼 오해하기 쉽습니다. 하지만 이 컴포넌트는 '내 정보를 호출하는 로직'과 '프로필 UI 렌더링 로직' 두 가지가 강하게 결합되어 있습니다.
이렇게 되면 어떤 문제가 발생할까요?
가장 먼저 발생하는 문제는 재사용이 어려워진다는 것입니다. 동일한 UI를 사용하는 화면이 있는데 내 정보가 아니라 다른 사용자의 프로필을 보여줘야 한다고 가정해볼까요? 현재 `MyProfile` 은 내 정보를 화면에 그려주는 역할을 하기 때문에 이 코드를 재사용할 수 없습니다. 그럼 아래와 같은 컴포넌트를 새로 만들어야 할 겁니다.
function UserProfile({ userId }) { const [user, setUser] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch(`/api/user/${userId}`) .then(res => res.json()) .then(data => setUser(data)) .finally(() => setLoading(false)); }, [userId]); if (loading) return <Spinner />; return ( <div className="profile"> <img src={user?.avatar} /> <h1>{user?.name}</h1> <p>{user?.email}</p> </div> ); }
컴포넌트를 분석해보니 '유저 정보를 호출하는 로직'과 '프로필 UI 렌더링 로직'이 결합되어 있네요. 뭔가 이상함을 느끼셨나요? 같은 '프로필 UI 렌더링' 책임이 두 컴포넌트에 중복되어 존재합니다. 단지 두 개가 아닙니다. 앞으로 동일한 UI를 사용할 때마다 매번 새로운 컴포넌트를 만들어야 하고, 앞으로 몇 개가 더 생성될지 모릅니다.
이는 결국 유지보수의 문제로 이어집니다. "프로필 UI에서 email이 없으면 '-'를 보여주세요" 같은 간단한 수정에도 수많은 컴포넌트들을 일일이 찾아서 수정해야 하고, 누락되는 부분이 생길 가능성이 큽니다.
반대로 다른 컴포넌트에서 유저정보를 가져다 사용하는 것 처럼 비즈니스 로직이 재사용되는 경우에도 매번 동일한 코드를 작성해줘야 하겠죠.
이처럼 비즈니스 로직과 UI의 결합은 언뜻 보면 자연스러워 보여도 실제로는 서로 다른 책임의 결합으로 이루어져 있음을 이해해야 합니다.
그럼 어떻게 수정하면 좋을까요? 처음 이야기했던 대로 비즈니스 로직과 UI를 분리하면 됩니다. 비즈니스 로직은 Custom Hook으로, UI는 별도 컴포넌트로 분리해보겠습니다.
// 내 정보를 가져오는 책임 담당 function useMyInfo() { const [myInfo, setMyInfo] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/me') .then(res => res.json()) .then(data => setMyInfo(data)) .finally(() => setLoading(false)); }, []); return { myInfo, loading }; } // 유저 정보를 가져오는 책임 담당 function useUser(userId) { const [user, setUser] = useState(null); const [loading, setLoading] = useState(false); useEffect(() => { if (!userId) return; setLoading(true); fetch(`/api/user/${userId}`) .then(res => res.json()) .then(data => setUser(data)) .finally(() => setLoading(false)); }, [userId]); return { user, loading }; } // UI를 렌더링하는 책임 담당 function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile"> <img src={avatar} alt={name} /> <h1>{name}</h1> <p>{email || "-"}</p> // 수정사항 반영 </div> ); }
이제 책임을 나누었으니 완성된 함수를 사용해보겠습니다.
function MyProfile(){ const { myInfo, loading } = useMyInfo(); return ( <ProfileCard loading={loading} avatar={myInfo?.avatar} name={myInfo?.name} email={myInfo?.email} /> ) } function UserProfile({ userId }){ const { user, loading } = useUser(userId); return ( <ProfileCard loading={loading} avatar={user?.avatar} name={user?.name} email={user?.email} /> ) } // 다른곳에서 비즈니스 로직 재사용 function Header(){ const { myInfo, loading } = useMyInfo(); return <UserSummary userLevel={myInfo?.level} name={myInfo?.name} /> }
어떠신가요? 이제 ProfileCard는 UI의 변경에만 대응하면 되는 단일 책임을 가진 컴포넌트가 되었습니다. 이렇게 비즈니스 로직과 UI를 분리하게 되면 여러 가지 장점이 따라옵니다.
재사용성 향상
ProfileCard는 어디서든 사용 가능합니다.
새로운 페이지에서 프로필을 보여줘야 한다면? ProfileCard 만 재사용하면 됩니다.
내 정보를 가져오는 비즈니스 로직이 필요하면 UseMyInfo 를 재사용하면 됩니다.
유지보수 용이
UseMyInfo, UseUser : "데이터를 어떻게 가져올 것인가"에 대한 책임
ProfileCard : "프로필을 어떻게 보여줄 것인가"에 대한 책임
MyProfile, UserProfile : "어떤 데이터를 어떤 UI로 조합할 것인가"에 대한 책임
각 모듈이 하나의 명확한 책임만 가지고 있어서, 변경의 이유도 하나씩만 가집니다. 유지보수 시점에 어떤 책임을 수정할지 확인하고 수정하면 됩니다.
병렬 개발이 가능하다
API 서버 개발이 늦어지는 상황에서도 UI를 완성할 수 있고, 추후 비즈니스 로직 작성이 UI 컴포넌트를 수정하지 않습니다.
반대로 디자인이 늦어지는 상황에서도 비즈니스 로직을 먼저 작성할 수 있습니다.
각각의 책임을 쉽게 테스트할 수 있다.
// Hook 테스트 test('useMyInfo는 내 정보를 가져온다', async () => { const { result } = renderHook(() => useMyInfo()); await waitFor(() => { expect(result.current.myInfo).toBeDefined(); }); }); // UI 테스트 (혹은 스토리북 테스트) test('ProfileCard는 사용자 정보를 표시한다', () => { render(<ProfileCard avatar="/avatar.png" name="홍길동" email="hong@example.com" />); expect(screen.getByText('홍길동')).toBeInTheDocument(); });
2. UI 세분화
비즈니스 로직을 분리했다면, 이제 UI 자체도 더 작은 책임으로 나눌 수 있습니다. 앞서 만든 ProfileCard 를 다시 살펴볼까요?
function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile"> <img src={avatar} alt={name} /> <h1>{name}</h1> <p>{email || '-'}</p> </div> ); }
이 컴포넌트는 '프로필 카드를 렌더링한다'는 하나의 책임을 가진 것처럼 보입니다. 실제로 어떤 상황에서는 하나의 책임이 맞을 수 있습니다. 하지만 조금 더 들여다보면 상황에 따라 여러 UI 요소들이 섞여 있다고 할 수 있습니다.
아바타 이미지 표시
사용자 이름 표시
이메일 표시
전체 레이아웃 구성
만약 다음과 같은 요구사항이 생긴다면 어떨까요?
"댓글 섹션에서도 사용자 아바타와 이름을 보여주세요"
"헤더에 아바타만 동그랗게 표시해주세요"
"사용자 정보 편집 폼에서 이메일 입력란 스타일을 프로필과 동일하게 해주세요"
현재 구조에서는 이런 작은 UI 요소들을 재사용하기 어렵습니다. 책임을 분리한 순간 ProfileCard 에 이미 여러 책임들이 섞여있기 때문이죠. 그래서 ProfileCard 에서 코드를 복사해와서 사용하거나 새로 작성해야 할 겁니다. 이는 디자인팀도 Figma를 사용해 디자인 요소를 컴포넌트화하는 현재 시점에서, 비즈니스 로직과 UI의 결합과 마찬가지로 유지보수 문제를 발생시킬 수 있습니다.
UI 컴포넌트도 비즈니스 로직처럼 작은 책임 단위로 나눌 수 있습니다. ProfileCard 를 실제로 책임 단위로 쪼개보겠습니다.
// 아바타 이미지 표시 책임 function Avatar({ src, alt, size = 'medium' }) { const sizeClasses = { small: 'w-8 h-8', medium: 'w-16 h-16', large: 'w-24 h-24' }; return ( <img src={src} alt={alt} className={`rounded-full ${sizeClasses[size]}`} /> ); } // 사용자 이름/이메일 표시 책임 function UserInfo({ name, email }) { return ( <div className="user-info"> <h3 className="text-xl font-semibold">{name}</h3> <p className="text-sm text-gray-600">{email || '-'}</p> </div> ); } // 프로필 카드 레이아웃 구성 책임 function ProfileCard({ avatar, name, email, loading }) { if (loading) return <Spinner />; return ( <div className="profile-card"> <Avatar src={avatar} alt={name} size="large" /> <UserInfo name={name} email={email} /> </div> ); }
이제 각 요소를 독립적으로 재사용할 수 있습니다.
// 댓글 섹션 - 작은 아바타와 이름만 function Comment({ author, content }) { return ( <div className="comment"> <Avatar src={author.avatar} alt={author.name} size="small" /> <div> <h4>{author.name}</h4> <p>{content}</p> </div> </div> ); } // 헤더 - 아바타만 function Header() { const { myInfo } = useMyInfo(); return ( <header> <Logo /> <Avatar src={myInfo?.avatar} alt={myInfo?.name} size="small" /> </header> ); } // 사용자 목록 - 아바타와 정보를 함께 function UserListItem({ user }) { return ( <li className="flex items-center gap-3"> <Avatar src={user.avatar} alt={user.name} size="medium" /> <UserInfo name={user.name} email={user.email} /> </li> ); }
이렇게 UI 로직도 책임 단위로 분리하게 되면 재사용성과 유지보수성을 더 좋게 만들 수 있습니다. 이렇게 UI 요소를 책임 단위로 분리하는 대표적인 패턴이 Atomic Design Pattern입니다.
주의해야 할 점은 반드시 모든 UI를 작은 컴포넌트 단위로 쪼갤 필요는 없다는 것입니다. 책임의 단위는 각 회사마다 다르고, 개발자마다 느끼는 책임의 범위도 다릅니다. 중요한 것은 실제로 재사용되는 단위, 독립적으로 변경되는 단위를 기준으로 적합한 책임의 단위를 찾아내고 관리하는 것입니다. 모든 요소를 강박적으로 쪼갤 필요는 없습니다.
3. 비즈니스 로직 세분화
비즈니스 로직과 UI를 분리했다고 해서 끝이 아닙니다. 비즈니스 로직 자체도 여러 책임으로 나눌 수 있습니다. Custom Hook 안에서도 여러 가지 일을 한꺼번에 처리하고 있다면, 그것 역시 단일 책임 원칙을 위반하는 것입니다.
예를 들어 장바구니 기능을 개발한다고 가정해봅시다.
// 여러 책임이 섞여있는 Hook function useCart() { const [items, setItems] = useState([]); const [loading, setLoading] = useState(false); // 장바구니 데이터 조회 useEffect(() => { setLoading(true); fetch('/api/cart') .then(res => res.json()) .then(data => setItems(data)) .finally(() => setLoading(false)); }, []); // 가격 계산 const totalPrice = items.reduce((sum, item) => sum + item.price * item.quantity, 0); const discount = totalPrice >= 50000 ? totalPrice * 0.1 : 0; const shippingFee = totalPrice >= 30000 ? 0 : 3000; const finalPrice = totalPrice - discount + shippingFee; // 상품 추가/삭제 const addItem = (product) => setItems(prev => [...prev, product]); const removeItem = (id) => setItems(prev => prev.filter(item => item.id !== id)); return { items, loading, totalPrice, discount, finalPrice, addItem, removeItem };
이 Hook은 다음과 같은 여러 책임을 가지고 있습니다
장바구니 데이터 가져오기
가격 계산 (총액, 할인, 배송비)
장바구니 아이템 관리
이렇게 되면 어떤 문제가 발생할까요?
주문 페이지에서 가격 계산만 필요한데, useCart 를 사용하면 불필요한 장바구니 데이터 fetching까지 실행됩니다
가격을 계산하는 코드는 외부 의존성이 없는 순수 함수 성격의 코드인데, 이를 테스트하기 위해서는 API mocking까지 해야합니다.
그럼 어떻게 책임단위로 분리할 수 있을까요?
// 가격 계산 로직만 담당 function calculatePrice(items) { const totalPrice = items.reduce((sum, item) => sum + item.price * item.quantity, 0); const discount = totalPrice >= 50000 ? totalPrice * 0.1 : 0; const shippingFee = totalPrice >= 30000 ? 0 : 3000; const finalPrice = totalPrice - discount + shippingFee; return { totalPrice, discount, shippingFee, finalPrice }; } // 장바구니 데이터 조회만 담당 function useCartData() { const [items, setItems] = useState([]); const [loading, setLoading] = useState(false); useEffect(() => { setLoading(true); fetch('/api/cart') .then(res => res.json()) .then(data => setItems(data)) .finally(() => setLoading(false)); }, []); return { items, setItems, loading }; } // 필요한 것들을 조합 function useCart() { const { items, setItems, loading } = useCartData(); const priceInfo = calculatePrice(items); const addItem = (product) => setItems(prev => [...prev, product]); const removeItem = (id) => setItems(prev => prev.filter(item => item.id !== id)); return { items, loading, ...priceInfo, addItem, removeItem }; }
로직을 분리하면 이제 필요한 곳에서 조립해 사용할 수도 있고, 각 모듈을 독립적으로 재사용 할 수도 있습니다. 테스트하기도 훨씬 수월해졌죠.
// 주문 페이지 - 가격 계산만 재사용 function OrderSummary({ orderItems }) { const { totalPrice, discount, finalPrice } = calculatePrice(orderItems); return ( <div> <p>총 금액: {totalPrice}원</p> <p>할인: -{discount}원</p> <p>최종 금액: {finalPrice}원</p> </div> ); } // 장바구니 페이지 - 전체 기능 사용 function CartPage() { const { items, finalPrice, addItem, removeItem } = useCart(); // ... } // 가격 계산 테스트 test('5만원 이상 구매시 10% 할인이 적용된다', () => { const items = [{ price: 50000, quantity: 1 }]; const result = calculatePrice(items); expect(result.discount).toBe(5000); });
이렇게 비즈니스 로직을 적당한 책임 단위로 분리해 재사용성을 높이고 유지보수를 용이하게 만들었습니다. 비즈니스 로직도 UI 로직과 마찬가지로 억지로 작은 단위로 분리하려고 힘쓸 필요는 없습니다. 우선 적당한 책임 단위로 만들고, 책임 분리가 필요한 시점에 분리해도 괜찮습니다. 가장 중요한건 분리가 필요하다고 느끼는 시점에는 반드시 분리를 해 주는 것이라고 생각합니다.
마치며
간단하게 단일 책임 원칙이 React에 어떤식으로 적용될 수 있는지 살펴봤습니다. 사실 위에 적은 이점 외에도 책임을 분리하면 좋은 점이 하나 더 있다고 생각합니다. 바로 AI에게 일을 맡길 때 굉장히 좋은 결과물로 나올 때가 많다는 것입니다. 이것저것 여러 책임을 부여한 컴포넌트를 AI에 만들어달라고 했을 때와 책임단위로 일을 분리한 뒤 한 개씩 AI에 만들어달라고 했을 때, 후자가 훨씬 더 좋은 결과물을 만들어 낼 때가 많았습니다. AI 생성물을 관리하는 입장에서도 후자가 훨씬 유리하겠죠.
단일 책임 원칙은 객체지향의 전유물이 아닙니다. SOLID 원칙도 그렇고 다른 개발원칙도 그렇습니다. React 개발에서도, 아니 어떤 개발에서도 적용할 수 있는 철학입니다. 중요한 건 원칙을 맹목적으로 따르는 게 아니라, 그 이면의 철학을 이해하고 상황에 맞게 적용하는 것입니다.
여러분의 컴포넌트는 너무 많은 책임을 떠안고 있진 않나요? 컴포넌트가 힘들어하고 관리자도 힘들어하고 있진 않은지요? 한 번 돌아보는 시간을 가져보시면 유익한 시간이 되리라 확신합니다.
결국 좋은 설계는 원칙을 맹목적으로 따르는 것이 아니라, 원칙을 ‘이해한 뒤 선택적으로 적용하는 것’에서 시작됩니다.
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!
→ 식스티헤르츠 채용공고 보러가기 (click!)
2025년 11월 14일
Insight
재생에너지의 심장, ESS, 그리고 전기차
재생에너지는 이제 우리 삶의 일부가 되었습니다. 건물 옥상 곳곳에 설치된 소규모 태양광 발전기를 볼 수도 있고 고속도로를 달리다 보면 광활한 임야에 설치된 대규모 태양광 발전소를 볼 수 있습니다. 바닷가를 지나다 보면 하늘 높이 뻗어있는 풍력발전기도 볼 수 있죠. 재생에너지 발전은 발전기의 이름에서 짐작할 수 있듯이 태양광이나 바람같은 자연에너지를 사용해 전기를 발전하는 것을 말합니다. 그래서 재생에너지 발전에 대해 잘 모르는 분들이라도 친환경적이고 경제적일 것 같다는 느낌을 받는 분이 많을 것 같아요. 실제로 재생에너지 발전은 발전소가 한 번 설치되고 난 이후부터는 발전비용이 거의 들지 않고 환경도 훼손하지 않습니다.
듣기만 해도 매력적입니다. 점점 비싸지는 전기요금에 대비하기도 좋고 친환경적인 전기 발전이라면 하지 않을 이유가 없을 것 같아요. 그런데, 여러분은 재생에너지를 사용하고 계신가요? 기업들은 재생에너지를 사용하고 있을까요? 아마 사용하고 계시는 분들도 일부 있겠지만, 대부분은 그렇지 않을 것이라고 생각합니다. 그럼 이렇게 좋은 재생에너지를 왜 적극적으로 사용하지 못하는 걸까요? 무조건 많이 설치해서 전국에서 사용하는 전기를 모두 재생에너지로 발전해서 사용할 수는 없는 걸까요? 이렇게 하지 못하는 가장 큰 이유 중 하나는 재생에너지의 불확실성에 있습니다.
전기의 특징과 재생에너지의 한계
전기는 기본적으로 저장이 어렵고 생산과 동시에 소비되어야 합니다. 여러분이 집에서 전기를 사용하려고 전등을 켜는 순간 불이 바로 들어오는 것에서 알 수 있는 것처럼 전기는 계속해서 생산되어 우리에게 전달되고 바로 사용됩니다. 그래서 항상 적정량의 전기가 생산되고 적정량의 전기가 소비되어야 전력망이 안정된 상태로 운영될 수 있습니다. 이때 우리나라 전력망의 표준 주파수가 60Hz이며, 이를 안정적으로 유지해야 합니다(저희 회사명 식스티헤르츠도 바로 이 주파수를 의미합니다). 전기 생산량이 소비량보다 많으면 주파수가 높아져 전기설비에 문제가 발생할 수 있고, 전기 생산량이 소비량보다 적어지면 정전이 발생할 수 있습니다. 그래서 KPX(한국전력거래소)는 전력망을 안정시키기 위해 많은 노력을 하고 있습니다.
그런데 재생에너지는 어떤 특징을 가지고 있을까요? 자연에너지를 활용하는 만큼 전기의 발전량도 자연에 달려있을 수밖에 없습니다. 구름이 잔뜩 낀 날은 태양광 발전이 어렵고 바람 한 점 없는 날에는 풍력 발전이 어려울 거예요. 반면에 햇빛이 좋은 날에는 태양광 발전이 엄청나게 잘 되겠죠. 당장 한 가구를 위한 재생에너지 발전시설이 있다 하더라도 재생에너지만으로 전기를 충당하는 것은 불가능에 가깝다는 이야기가 됩니다.
예시를 들어보면, 한여름 오후 6시에 에어컨이 한창 가동되어 전력 소비가 많은 시기에 해가 지기 시작해 전력 공급이 점점 줄게 되면 정상적으로 소비 전력을 공급하지 못하는 상황이 올 거예요. 혹은, 전기를 쓰지 않는데도 태양광 발전이 너무 잘 되어 문제를 일으킬 수도 있게 되겠죠.
그렇다면 이런 재생에너지가 국가 전력망에 대규모로 연결되면 어떻게 될까요? 재생에너지 발전시설은 때로는 과도하게, 때로는 부족하게 계통에 전기를 공급하게 되고 이는 전력망을 불안정하게 만드는 위험 요소가 될 거예요. 이처럼 재생에너지의 불확실성과 간헐성은 전력망 안정성에 큰 도전 과제가 되고 있습니다.
재생에너지의 심장, ESS
그렇다면 재생에너지의 이런 한계를 어떻게 해결할 수 있을까요? 바로 여기서 ESS(Energy Storage System, 에너지저장시스템)가 등장합니다. ESS를 가장 쉽게 설명하자면 '거대한 배터리'라고 생각하시면 됩니다. 여러분이 스마트폰을 충전해두고 필요할 때 사용하는 것처럼, ESS도 전력을 저장해두었다가 필요할 때 꺼내 쓸 수 있게 해주는 시스템입니다.
예를 들어 볼까요? 한여름 낮 12시, 태양이 쨍쨍 내리쬐어 태양광 발전이 최대로 이루어지고 있습니다. 하지만 이 시간에는 대부분의 사람들이 외출해 있어서 전력 사용량이 많지 않아요. 이때 남는 전력을 ESS가 배터리에 저장해둡니다. 그리고 저녁 6시가 되면 사람들이 집에 돌아와 에어컨을 틀고 밥을 짓기 시작하면서 전력 사용량이 급증하죠. 하지만 태양은 이미 지기 시작해서 태양광 발전량은 줄어들고 있습니다. 바로 이때 ESS가 낮에 저장해둔 전력을 꺼내서 공급하는 거예요.
마치 우리 몸의 심장이 혈액을 온몸으로 순환시켜 생명을 유지하듯이, ESS는 에너지를 저장하고 공급하며 재생에너지 시스템의 생명력을 유지하는 핵심 역할을 합니다. 그래서 ESS를 '재생에너지의 심장'이라고 칭했습니다. ESS는 이렇게 재생에너지의 한계점을 보완하고 안정적인 전력공급을 할 수 있게 만들어 줍니다.
식스티헤르츠와 ESS
그럼 식스티헤르츠는 여기서 어떤 역할을 할까요? ESS는 위에 말씀드린 것처럼 재생에너지 생태계에서 아주 중요한 역할을 하지만, 자세하게 들여다 보면 단순한 거대 배터리에 불과합니다. 저장하면 저장이 되고, 방전하면 방전이 되는 게 전부인 것이죠.
여기서 식스티헤르츠가 '재생에너지의 뇌' 역할을 수행합니다. 식스티헤르츠는 ESS를 관리할 수 있는 소프트웨어를 개발해 ESS가 더 효율적으로 재생에너지를 활용할 수 있도록 돕습니다. 단순히 충방전 on/off만 하던 ESS를 더 다양한 상황에 맞춰 정밀하게 제어하는 것이죠. 구체적으로 몇 가지 예시를 들어보겠습니다.
1. 잔여 재생에너지 발전량 저장
태양광 발전량과 가구 소비량을 예측한 뒤 잉여 발전량이 예측되면 잉여 발전량은 ESS로 저장될 수 있도록 실시간으로 제어합니다. 저장된 전력은 필요한 때 방전해서 사용할 수 있게 되어, 재생에너지를 유연하게 활용할 수 있게 도와줍니다.
2. 전력 부하시간대별 요금 최적화
우리나라의 일부 전력 사용자들은 계절별/시간별로 전기요금이 경부하/중간부하/최대부하로 요금 체계가 나뉘어져 있습니다. 경부하 시간대에 사용하는 전기요금이 가장 저렴하고 최대부하 시간대에 사용하는 전기요금이 가장 비쌉니다.
그래서 경부하 시간대에는 ESS를 최대로 충전하고, 더 비싼 전기요금 시간대에 ESS를 방전해 전기요금을 절감할 수 있는 알고리즘을 개발해 운용하고 있습니다. 여기에 태양광 예측기술이 결합되어 경부하 시간대에 재생에너지만으로 ESS를 가득 충전할 수 없는 경우 부족한 전력은 계통을 통해 구매해 축적해 더 효율적으로 동작할 수 있도록 돕습니다.
3. DR 제도 대응
앞서 KPX에서 안정적인 전력망 유지를 위한 노력을 하고 있다고 말씀드렸는데요. 여러가지 방법 중 하나로 전력 사용을 조절하는 방법이 있습니다. KPX에서 전력이 부족한 시간대에는 전력 사용을 줄이라는 요청을 보내고, 전력이 남을 것 같은 시간대에는 전력 사용을 늘리라는 요청을 보내게 됩니다.
전력 사용을 줄이는 요청을 보내 전력망을 안정시키는 제도를 일반적인 DR(Demand Response)라고 부르고 전력 사용을 늘리는 요청을 보내 전력망을 안정시키는 제도를 플러스 DR이라고 부릅니다. 이런 DR 제도에 참여하게 되면 그에 응하는 보상을 받을 수 있고, ESS는 이런 제도에 참여하기에 최적화된 시스템입니다. DR에 적극 대응할 수 있도록 소프트웨어로 ESS를 제어할 수 있습니다.
전기차, 움직이는 ESS
그럼 전기차는 뜬금없이 왜 언급되었을까요? 전기차는 왜 전기차일까요? 전기로 동작하는 차량이기 때문에 전기차라고 부르겠지요. 전기로 운행이 가능하려면 무엇이 필요할까요? 바로 전기를 저장할 수 있는 배터리가 필요합니다. 그래야 전원 공급에서 멀어진 채로 장거리를 운전할 수 있겠죠. 그래서 전기차에도 모두 전기배터리가 있고 충전/방전을 할 수 있습니다. 최근에는 V2L(Vehicle to Load)라는 기술이 널리 퍼져 실제로 전기차에서 전기를 공급받아 캠핑이나 비상상황에 활용할 수 있게 되었습니다.
이제 왜 전기차가 언급되었는지 조금 감이 오시나요?
전기차는 이동이 가능하다.
전기차는 전기를 저장할 수 있다.
요약하면 전기차는 결국 움직일 수 있는 ESS라고 볼 수 있습니다. 이렇게 전기차를 계통과 연결해 전기차를 충전하는 것 뿐만 아니라 전기차를 방전시켜 전력망에 보낼 수 있는 기술을 V2G(Vehicle-to-Grid)라고 부릅니다.
사실 일반적인 ESS는 굉장히 비싸고 거대해서 일반 가정에서 활용하기 쉬운 시스템은 아닙니다. 그에 비해 전기차는 이제 널리 보급되어 쉽게 볼 수 있죠. 그래서 저희는 전기차를 ESS처럼 활용해 일반 가구의 재생에너지 활용도를 높이는 방안을 고민하고 소프트웨어로 해결할 수 있는 기술을 개발하고 있습니다. 언젠가는 전기차 차주들이 계통망을 안정화시키는데 가장 큰 역할을 할 것이라고 확신합니다.
함께 만들어갈 미래
식스티헤르츠에서는 이처럼 다양한 상황에 다양한 방법으로 재생에너지를 활용하는 소프트웨어를 개발해 운영하고 있습니다. 현재 전력시장과 재생에너지 생태계를 분석해 그에 맞는 알고리즘을 개발하고, 이를 적절하게 시각화해서 고객들이 사용하기 편하고 이해하기 쉬운 형태로 서비스를 만들어 나가고 있습니다.
재생에너지, V2G에 관심이 있으시다면 식스티헤르츠의 행보를 관심있게 지켜봐주시면 감사하겠습니다. 더 나아가 이런 기술 개발에 함께 참여하고 싶은 소프트웨어 엔지니어분들의 많은 관심 부탁드립니다.
By 방경민 ㅣ TVPP/FE Leader ㅣ 60Hertz
🔗 채용 페이지 바로가기!
#재생에너지 #에너지저장장치 #ESS #DR #전기차 #V2G #스마트그리드 #탄소중립 #에너지전환 #에너지혁신 #가상발전소 #태양광 #풍력 #전력망안정화 #식스티헤르츠 #에너지소프트웨어
2025년 9월 23일
Insight
재생에너지 혁신의 현장, 기후산업국제박람회 2025 참여 소식
식스티헤르츠가 지난 8월 27일부터 29일까지 부산 벡스코에서 열린 세계기후산업박람회(WCE 2025)에 참가했습니다. 이번 행사는 산업통상자원부, 국제에너지기구(IEA), 세계은행(WB)이 공동 주최한 글로벌 에너지·기후 대표 박람회로, 약 560개 국내외 선도 기업이 참여해 미래 에너지 혁신 기술을 선보이는 자리였습니다.
WCE 2025, “Energy for AI & AI for Energy”
올해 WCE의 주제는 “Energy for AI & AI for Energy” 였습니다. AI가 어떻게 지속 가능하고 안전하며 효율적인 글로벌 에너지 시스템을 만들어가는지, 또 인공지능이 에너지 수요 급증과 공급 안정화 문제를 어떻게 해결할 수 있는지가 주요 의제로 다뤄졌습니다. 전시장에서는 청정에너지, 에너지·AI, 미래교통, 환경, 해양, 기상 등 다양한 분야의 혁신 기술이 전시되었으며, 글로벌 리더십·에너지&AI·기후 등 3개의 서밋과 12개의 전문 회의 등이 함께 열렸습니다.
제1전시장 현장
이번 기후산업국제박람회 2025의 제1전시장에는 SK, 현대차, 삼성전자, 한화큐셀, 두산에너빌리티, 포스코, 효성중공업, 고려아연 등 국내 주요 기업들이 대거 참여해 미래 에너지 전환을 위한 다양한 기술과 솔루션을 선보였습니다. 특히, 청정에너지와 스마트그리드, 수소경제 등 첨단 분야의 전시가 활발히 이루어지며, 전력망 혁신과 탄소중립 실현을 위한 산업계의 방향성을 엿볼 수 있었습니다. 많은 참관객들이 최신 기술을 직접 체험하며, 기업 부스에서 관계자들과 활발히 교류하는 모습이 인상적이었습니다.
식스티헤르츠 부스 & 주요 성과
식스티헤르츠는 이번 박람회에서 대한민국 에너지대전 혁신상 특별관과 전력거래소(KPX) 부스를 통해 AI 기반 에너지 통합 관리 솔루션을 소개했습니다. 3일간 운영된 부스에는 공공기관, 대기업, 금융권 등 다양한 이해관계자가 방문하여 깊은 관심을 보였습니다.
특히 해외 재생에너지 사업 협력 가능성 논의, 에너지케어 및 모니터링 솔루션 문의, PPA 사무위탁과 신규 서비스 모델에 대해 의견을 나누는 등 다양한 후속 협업 기회가 마련될 것으로 기대됩니다.
KPX와 함께한 CMV 소개
전력거래소(KPX)와의 파트너십 프로젝트인 CMV(Cloud Motion Vector)도 전시 현장에서 소개되었습니다. 그래픽과 영상을 통해 방문객들에게 구름이동기반 초단기 발전량 예측 시스템으로 새로운 전력시장 시각화 도구를 선보였습니다.
혁신상·IR·세미나 참여 소식
이번 기후산업국제박람회 2025에서 식스티헤르츠는 기후·에너지 혁신상 시상식에서 산업통상자원부 장관상을 수상하며, 자사의 기술력과 성과를 공식적으로 인정받는 뜻깊은 성과를 거두었습니다. 또한 전시 기간 동안 IR 기업 소개 발표와 중부발전 주최 미니 세미나에 참여해, 에너지 전환을 위한 비전과 혁신적인 솔루션을 공유했습니다.
현장 반응 & 설문 결과
혁신상 특별관에서 진행한 설문조사에는 약 80여명이 참여했으며, 응답자의 다수는 제조업, 에너지·전력, 공공 부문 종사자였습니다. 응답자들은 ▲에너지 절감 및 수익성 개선 효과 ▲AI 활용 가능성 ▲파트너십 기회 등에 높은 관심을 보였습니다.
식스티헤르츠가 만든 의미
이번 WCE 2025 참가를 통해 식스티헤르츠는 국내외 주요 기관 및 기업과의 협력 가능성을 확인하고, AI 기반 에너지 혁신 솔루션의 시장성과 필요성을 다시 한번 입증했습니다. 앞으로도 재생에너지 확산과 효율적 관리, 그리고 탄소중립 실현을 위해 글로벌 파트너십을 확대해 나갈 예정입니다.
#기후산업국제박람회2025 #기후산업박람회 #기후에너지혁신상 #산업통상자원부 #한국에너지공단 #장관상표창 #재생에너지전환 #AI에너지
2025년 9월 9일
Impact
SOVAC과 함께하는 사회적가치 페스타 현장 스케치
식스티헤르츠는 지난 8월 25일(월)부터 26일(화)까지 삼성동 COEX Hall C에서 열린 제2회 대한민국 사회적가치 페스타에 참가해, 다양한 기관 및 기업들과 지속가능한 미래를 위한 협력 방안을 함께 고민하며 뜻깊은 시간을 보냈습니다.
대한민국 사회적 가치 페스타란? 🎊
대한상공회의소가 주최하고, SOVAC, SK텔레콤, 현대해상, 카카오임팩트, KOICA 등 여러 기관이 함께 주관하며 기후위기, 지역소멸, 미래세대, 디지털 격차 등 복합적인 사회문제를 민관 협력으로 해결하기 위해 마련된 국내 최대 규모의 사회적 가치 축제입니다. 올해 행사에는 13,000여 명의 참관객과 300여 개 기관·기업이 함께하며 다양한 강연과 전시를 통해 “지속가능한 미래를 설계(Designing the Sustainable Future)”라는 주제를 나눴습니다.
식스티헤르츠의 전시 부스 ☀️
식스티헤르츠는 이번 페스타에서 SOVAC “혁신의 길_기후위기 극복” 존에 전시 부스를 마련하고, 자사의 AI 기반 재생에너지 발전량 예측 및 관리 기술을 중심으로 다양한 에너지 자원을 통합적으로 운영할 수 있는 솔루션을 소개했습니다. 이를 통해 기후위기 대응과 안정적인 전력 운영, 그리고 탄소중립 실현을 돕고 있습니다. 이틀간의 현장은 다양한 공공기관, 대기업, 소셜벤처, 금융기관, 그리고 업계 전문가분들을 만나 식스티헤르츠의 기술과 비전을 공유할 수 있었던 뜻 깊은 자리였습니다. 특히, 에너지 전환 솔루션에 대한 많은 관심과 다양한 협력 가능성을 확인할 수 있는 시간이었습니다.
퀴즈 이벤트와 현장 🎁
식스티헤르츠는 부스를 찾아주신 분들을 위해 "도전, 식스티!" 퀴즈 이벤트도 함께 진행했습니다. 방문객들이 식스티헤르츠를 한층 더 이해하고 기억할 수 있는 퀴즈로, 재생에너지, 탄소중립 등에 관심을 보이며 현장 분위기를 더욱 뜨겁게 만들어 주었습니다. 또한 퀴즈를 모두 맞힌 정답자에게는 소정의 기념품을 드려서 현장 분위기도 더욱 활기찼습니다.
현장에서 만난 소중한 인연들 🤝
이번 페스타에서는 공공 및 민간을 포함해 다양한 소셜벤처 파트너사와의 만남을 통해 식스티헤르츠의 활동 영역을 넓히고, 새로운 협력의 기회를 모색할 수 있었습니다. 많은 분들께서 관심을 가지고 찾아주셔서 재생에너지 확산을 위한 사회적 가치 창출 활동에 대한 공감과 응원을 느낄 수 있었습니다. 🙏
앞으로의 계획 🗓️
이번 페스타는 단순한 전시회를 넘어, 재생에너지와 기후테크 분야의 리더로서 식스티헤르츠가 나아갈 방향을 다시 한번 확인하는 소중한 시간이었습니다. 앞으로도 현장에서 만난 소중한 인연들을 바탕으로 협업을 이어가며, 더 많은 기업과 기관이 지속가능한 에너지 전환에 동참할 수 있도록 최선을 다하겠습니다.
마무리하며 🚀
SOVAC과 함께하는 대한민국 사회적가치 페스타는 ‘함께 만드는 지속가능한 미래’라는 비전을 공유하는 자리였습니다. 식스티헤르츠도 이 여정의 한 축으로서, 기후위기 대응과 사회적 가치 확산을 위한 노력을 계속 이어가겠습니다.
함께해 주신 모든 분들께 진심으로 감사드립니다! 🌏💚
#식스티헤르츠 #SOVAC #사회적가치페스타 #재생에너지 #에너지전환 #AI기반솔루션 #기후테크 #지속가능한미래 #사회적가치 #소셜벤처
2025년 8월 28일
Insight
에너지고속도로란?
최근 뉴스에서 “에너지고속도로”라는 표현을 자주 접할 수 있습니다. 특히 “에너지고속도로” 구축이 정책적 화두로 떠오르기도 했는데요. 이름만 들으면 도로나 교통망이 떠오를 수도 있지만, 사실은 전기를 장거리-대규모로 효율적으로 이동시키기 위한 첨단 송전 인프라를 가리키는 비유적인 표현입니다. 이번 블로그 글에서는 “에너지고속도로”와 함께 관련된 주요 키워드를 살펴보도록 하겠습니다.
왜 ‘고속도로’라는 표현을 쓰나요?
자동차 고속도로가 사람과 물자를 빠르고 효율적으로 이동시키듯, "에너지고속도로"는 발전된 전기를 멀리 있는 소비지로 신속하고 효율적으로 ‘운송’하는 첨단 전력망을 의미합니다.
왜 이런 개념이 필요할까요?
전 세계가 탄소중립을 목표로 재생에너지 비중을 확대하고 있지만, 대부분 발전소 입지와 수요가 일치하지 않는 문제가 발생하고 있습니다. 다시 말해 재생에너지는 친환경적이지만 입지가 한정적입니다. 예를 들어, 대규모 태양광 발전소는 햇빛이 좋은 공장 지붕, 임야, 평야 등에 설치가 됩니다. 해상풍력발전단지는 어떨까요? 바람이 좋은 해안이나 산악지대를 선호합니다. 반면에 주요 전력 소비는 대도시나 도심 또는 산업지대에 집중되고 있습니다. 그래서 이러한 격차를 메우고 거리를 잇기 위한 인프라 혁신으로 “에너지고속도로”와 같은 첨단 전력망이 필요합니다.
기술적 핵심
"에너지고속도로"는 기존 송전망과는 다른 기술이 적용됩니다. 매우 긴 거리에서도 전력 손실이 적어야 하며, 대규모 전력을 한 번에 안정적으로 이송할 수 있어야 하기 때문입니다. 그래서 초고압 직류 송전(HVDC)과 같은 핵심 기술이 필요합니다. 또한 단순한 ‘길’이 아닌 스마트하고 유연한 에너지 네트워크를 기반으로 만들어져야 합니다.
주요 특징
장거리 초고압 송전: 태양광 풍력과 같이 먼 거리에 위치한 대규모 재생에너지 발전소에서 도심이나 산업단지로 전력 전송
디지털-스마트 그리드 기술 접목: AI, IoT 기반 실시간 수요관리와 분산자원 통합
지역 간 연계성 강화: 지역 간 전력망을 연결해 수급 안정화
경제-환경적 가치
"에너지고속도로"는 단순한 전력망이 아닙니다. 재생에너지 발전 단가가 낮은 지역에서 전력 조달 시 전력 가격 안정화에 기여하며, 기존의 화력 발전소 대체 및 탄소중립 실현에 기여 가치는 매우 클 것으로 기대됩니다.
단점 및 한계
하지만 초고압 직류(HVDC) 송전망 건설에는 대규모의 투자가 필요합니다. 해저케이블, 변환소(AC—>DC 변환), 관리 시스템 등 발생 비용이 매우 큽니다. 정부 보조나 전기요금 인상과 같은 논쟁도 불가피합니다. 또한 설계, 인허가, 협의, 시공까지 긴 건설 기간이 걸릴 수도 있습니다. 기술 의존성이나 표준 문제나 초기 투자에 더해 운영 유지 비용이나 보안도 큰 문제가 될 수 있습니다. 이렇듯 "에너지고속도로"는 재생에너지 전환의 필수 인프라지만, 비용, 시간, 사회적 합의, 기술 의존 등 해결해야 할 도전 과제가 매우 많습니다.
보이지 않는 혁신의 길
그럼에도 자동차 고속도로가 산업화를 이끌었듯, "에너지고속도로"는 재생에너지 전환을 가능하게 만드는 전략적인 인프라입니다. 발전소는 지방에, 소비는 도시에와 같은 구조적 문제를 해결하며 재생에너지의 불규칙성을 보완할 수 있습니다. 앞으로 우리나라가 이 거대한 보이지 않는 도로를 어떻게 설계하고 구축할지 에너지 전환과 관련한 중요한 과제가 될 것으로 보입니다.
#에너지고속도로 #송전망혁신 #전력망 #탄소중립 #에너지전환 #재생에너지확산 #전력인프라 #HVDC #스마트그리드 #분산에너지
2025년 7월 24일
Insight
식스티헤르츠, 2025년 '혁신 프리미어 1000' 기업 선정
식스티헤르츠가 2025년 '혁신 프리미어 1000' 기업에 선정 되었습니다!
지난 5월 14일, 금융위원회는 산업통상자원부, 과학기술정보통신부, 중소벤처기업부 등 13개 부처와 함께 2025년 제1차 ‘혁신 프리미어 1000’ 기업으로 총 509개의 중소·중견기업을 선정했다고 발표했습니다. (참조: 대한민국정책브리핑, 중소·중견기업 509개, '혁신 프리미어 1000' 선정)
이 프로그램은 기술 혁신을 통해 신제품 개발, 신규 시장 개척, 부가가치 창출, 고용 확대에 기여할 수 있는 유망 기업을 발굴·지원하기 위한 정부의 중점 정책 중 하나입니다.
식스티헤르츠는 이번 선정을 통해 AI 기반 재생에너지 발전 예측 및 제어 기술의 혁신성과 성장 가능성을 정부로부터 공식적으로 인정받았습니다. 이는 기술력은 물론, 지속가능한 에너지 전환을 이끄는 기업으로서의 경쟁력과 비전을 입증하는 중요한 이정표가 되었습니다.
식스티헤르츠의 주요 기술은 소규모 재생에너지 자원을 통합 관리하는 가상발전소(VPP) 통합 소프트웨어와 AI를 활용한 발전량 예측 기술을 기반으로, 재생에너지의 불확실성을 줄이고 전력 운영의 효율성을 높이는 데 중점을 두고 있습니다. 이러한 기술력은 재생에너지 생태계 고도화에 기여하며, 이번 평가에서 높은 점수를 받은 핵심 요인으로 분석됩니다.
이번 선정을 계기로 식스티헤르츠는 정책금융기관의 맞춤형 지원과 부처별 특화 사업의 혜택을 바탕으로, 기술 중심의 에너지 전환은 물론 글로벌 시장 진출에도 더욱 박차를 가할 계획입니다.
[회사 소개]
식스티헤르츠는 2021년, 전국 13만 개의 태양광·풍력·에너지저장장치(ESS)를 연결한 ‘대한민국 가상발전소’를 공개하며 주목을 받았습니다. 이후 약 8만 개의 재생에너지 발전소(총 18GW)의 위치와 발전량을 AI로 시각화한 ‘햇빛바람지도’를 무료로 제공하는 등, 에너지 데이터 기반 서비스를 지속 확장하고 있습니다.
2023년: 자체 개발한 에너지관리시스템(EMS)으로 CES 혁신상 수상
2024년: IPEF(인도·태평양 경제 프레임워크) 선정 아시아·태평양 100대 기후테크 기업
앞으로도 식스티헤르츠는 기술을 통해 더 많은 사람들이 지속가능한 에너지 전환에 참여할 수 있도록 혁신을 이어가겠습니다.
👉 홈페이지 바로가기
#식스티헤르츠 #재생에너지 #에너지전환 #가상발전소 #인공지능 #RE100 #탄소중립 #기술혁신 #혁신프리미어1000 #선정
2025년 5월 19일
Insight
작은 변화, 큰 영향
안녕하세요,
에너지 IT 소셜벤처 식스티헤르츠입니다.
지난 4월 23일부터 25일까지 서울 양재동 aT센터에서 열린 '2025 자동차부품산업 ESG·탄소중립 박람회'에서 식스티헤르츠 부스를 방문해주신 모든 분들께 진심으로 감사드립니다.
이번 박람회에서 식스티헤르츠는 기업의 지속가능경영을 실현할 수 있도록 돕는 다양한 에너지 IT 솔루션을 제1 전시장 제조혁신관(현대차-기아 제조솔루션본부 협력관) 및 제2전시장 재생에너지관(현대건설-현대차증권 협력관)을 통해 아래와 같이 소개했습니다.
태양광 발전소 구축 및 운영 솔루션
전력 통합관리 모니터링 시스템(EMS)
온사이트 PPA 및 RE100 달성 컨설팅
V2G 에너지 신산업 생태계 구축
수요반응(DR)을 통한 전력 효율화
특히, 박람회 기간 제조 산업을 포함한 많은 방문객들이 공장 지붕이나 주차장 등 유휴 부지를 활용한 태양광 구축 사례에 많은 관심을 보여주셨으며, 재생에너지 전환을 통한 비용 절감 방안에 대한 깊이 있는 상담도 적극적으로 요청해 주셨습니다.
예를 들어, 약 3,000평 규모의 공장에 1MW급 태양광 발전소를 도입하면 연간 약 3,000만원의 전기료 절감, 에너지 관련 부가 수익 창출, 그리고 604톤 규모의 온실가스 감축 효과를 기대할 수 있습니다.
이를 위해 식스티헤르츠의 고객 환경 맞춤형 토탈 솔루션을 도입 시 ESG 경영을 더욱 효율적이고 체계적으로 실현할 수 있습니다.
[고객 맞춤형 솔루션]
태양광 설비 도입
실시간 발전량 모니터링
RE100 성과 분석
[태양광 도입 및 모니터링 솔루션 구축 최신 사례]
인천 남동 스마트그린산업단지 에너지 자급자족 인프라 구축 및 운영사업
태양광 패널부터 인버터, 모니터링 솔루션의 통합 구축
고객의 전기 사용량에 따른 과금 정산서 발행 (임대형 발전소 대상)
실시간 출력 제어 및 스마트 O&M을 통한 발전량 오차율 및 고장 예측 감지
현대자동차 국내외 공장 태양광 모니터링 시스템 구축
현대자동차 국내 주요 공장 다수 온-프레미스 태양광 모니터링 스마트 O&M 시스템 구축 (5MW~9MW)
현대자동차 미국 북미 공장 온-프레미스 태양광 모니터링 시스템 구축
앞으로도 식스티헤르츠는 탄소중립과 에너지 전환을 선도하는 신뢰받는 파트너로서, 귀사의 지속가능한 성장을 적극 지원하겠습니다.
지속가능한 미래를 함께 만들어가길 기대합니다!
👉 식스티헤르츠 솔루션 자세히 보기
#식스티헤르츠 #ESG #RE100 #탄소중립 #탄소저감 #자동차부품산업 #지속가능 #재생에너지 #태양광 #EMS #PPA #REC #V2G #DR
2025년 4월 30일
Tech
가상발전소(VPP) 통합 솔루션
분산에너지 자원의 특징
전세계적으로 탄소중립이 주요 화두가 되면서, 탄소중립 달성 수단으로 분산에너지에 대한 관심이 증대되고 있습니다. 분산에너지는 전통적인 중앙집중식 발전소를 통한 전력 수급 시스템에 대비되는 개념으로, 에너지의 사용지역 인근에서 생산되는 에너지를 말합니다. 기본적으로 분산에너지는 규모가 작고 에너지 사용지역 인근에 위치한다는 특징을 가지고 있습니다.
분산에너지 자원의 확대
분산에너지는 기존의 대단위 발전소 및 송전선을 건설하는 방식보다 용이하며, 송 · 배전망을 신규로 건설하기 위해 투입되는 인프라 건축비용과 운영비용을 크게 절감할 수 있다는 장점이 있습니다. 특히 분산에너지 자원들은 친환경 재생에너지로 온실가스나 탄소배출 감소에 기여하는 바가 크다고 여겨집니다. 하지만 분산에너지 자원 중 태양광과 풍력은 일조량과 풍량에 의존하기 때문에 변동성이 생길 수 있고, 이로 인해 전력계통의 안전성을 저해할 수 있습니다. 우리나라도 태양광 중심으로 재생에너지 비중을 확대하고 있어서 변동성 문제를 완화하거나 발전 효율을 높일 수 있는 방안에 대한 관심 및 관련 정책 등이 확대되고 있습니다.
분산에너지 자원의 효율적 관리 운영을 위한 솔루션
위에서 언급한 재생에너지 비중이 확대되면서 발전 효율 증대, 발전량 예측 및 관리 등 관련 분야의 기술 개발 및 도입이 활발히 진행되고 있는 가운데, 식스티헤르츠에서 출시한 Energy Scrum은 분산에너지 자원을 효율적으로 관리 및 운영하는데 최적화된 에너지 관리 시스템입니다. Energy Scrum을 통하면 PV, ESS, 연료 전지, EV 충전기 등 다양한 분산자원을 AI를 기반으로 전체 에너지 공급과 수요를 정확하게 예측하여 하나의 통합된 시각으로 확인 및 관리할 수 있습니다.
사용자 친화적으로 설계된 에너지 관리 시스템
Energy Scrum은 일부 번거로운 프로세스를 최소화하여 분산자원을 조율할 수 있도록, 사용자가 사용자별 운영 시나리오를 적용하여 친환경 전기 사용을 극대화하는 것과 같은 목표를 달성할 수 있도록 지원합니다. 예를 들어 Energy Scrum을 오래된 주유소에 적용시 친환경 에너지 스테이션으로 전환할 수 있습니다.
AI 기반 기술 혁신으로 고도화
Energy Scrum은 다양한 분산자원을 연결하고 클라우드 기반 시스템에서 방대한 양의 비정형 데이터를 관리할 수 있는 OpenAPI 서비스를 제공합니다. 분산자원과 지역 IoT 센서, 기상 위성과 같은 외부 소스의 정보를 결합하여 AI 모델을 점진적으로 훈련하고, 데이터와 학습을 축적하여 전체 에너지 공급과 수요에 대한 보다 정확한 예측을 제공합니다. 또한 예측된 에너지 정보를 활용하여 사용자의 요구에 맞는 다양한 모드(예: 친환경 전기 사용량 극대화 모드)를 제공합니다. 따라서 사용자는 목표를 달성하기 위해 원하는 방식으로 분산자원을 조정할 수 있습니다.
신재생에너지 시장을 겨냥한 차별화
Energy Scrum의 차별화된 강점은 대부분의 발전사들이 사용하고 있는 모니터링 솔루션에 비해 제조사를 포함한 다양한 고객의 니즈에 맞춤형으로 설계가 가능하며, 태양광 풍력 뿐 만이 아닌 다양한 분산에너지 자원들을 효율적으로 관리할 수 있다는 것입니다. 특히 관리 및 운영의 영역을 넘어 발전소유주들의 시장을 연결하여 재생에너지의 활성화와 수익을 만들 수 있는 생태계를 구축하는 통합 플랫폼으로 구현되었다는 점입니다. 예를 들어 V2G (Vehicle-to-grid, 전기자동차를 전력망과 연결해 배터리의 남은 전력을 이용) 기술을 적용 및 전기차를 에너지 저장 장치로 활용하는 시장을 연결하여 주행 중 남은 전력을 건물에 공급하거나 판매할 수 있는 플랫폼으로 활성화할 수 있습니다.
CES 2023 혁신상 수상
식스티헤르츠의 에너지관리시스템 Energy Scrum은 세계 최대 IT 전시회 ‘CES 2023’에서 지속 가능성, 에코 디자인 및 스마트 에너지 분야에서 혁신상을 수상한 바 있습니다. 친환경 분산전원이 전 세계적으로 빠르게 확대됨에 따라 이를 통합적으로 관리할 수 있는 시스템 수요가 지속적으로 증가하고 있는 가운데, 식스티헤르츠의 기술력이 집약된 Energy Scrum은 첨단 에너지 관리시스템으로 재생에너지 관리의 새로운 지평을 열었다는 평가를 받았습니다. 특히 기존 태양광 중심의 가상발전소 개념을 넘어, 풍력과 에너지저장장치(ESS)까지 통합 관리하는 종합 솔루션으로서 재생에너지의 효율적인 운영을 통해 재생에너지 확산에 기여할 수 있기를 기대합니다.
#식스티헤르츠 #재생에너지 #에너지관리시스템 #EMS #VPP #ESS
2025년 4월 25일
Impact
기술로 그리는 지속가능한 에너지 전환
전 세계적으로 RE100과 탄소중립이 기업의 새로운 기준이 되어가고 있는 지금, ‘재생에너지를 더 쉽게, 더 효과적으로’ 쓰기 위한 기술이 필요합니다. 식스티헤르츠는 이러한 전환을 현실로 만들고 있는 에너지 IT 소셜벤처입니다. 인공지능, 빅데이터, 클라우드 기술을 바탕으로 분산된 재생에너지 자원의 가치를 극대화하며, 사회와 환경에 긍정적인 변화를 만들어가고 있습니다.
수치로 증명된 임팩트
지난 해 기준 식스티헤르츠는 8개 기업을 대상으로 재생에너지 구독 서비스를 운영하며 총 11,901MWh의 재생에너지 사용을 이끌어냈습니다. 이를 통해 약 5,089tCO2e의 탄소배출을 저감하는 성과를 달성했으며, 이는 탄소중립 실현을 위한 의미 있는 진전이었습니다. 뿐만 아니라, 소셜벤처 및 중소기업을 위한 소규모 REC 구매 지원, 월별 리포팅 시스템 운영 등을 통해 에너지 접근성과 투명성도 높이고 있습니다.
기술로 완성하는 에너지 전환
식스티헤르츠는 기후, 수요, 공급의 불확실성 속에서도 전력망을 안정적으로 운영할 수 있도록 최신 기술을 적용한 다양한 솔루션을 개발 및 운영하고 있습니다.
☀️ 햇빛바람지도
국내 유일의 재생에너지 발전량 예측 공개 서비스로, 전국의 태양광/풍력 발전소 발전량을 AI 기반으로 예측 및 시각화하여 일 발전량 및 내일 발전량 예측치를 제공합니다. 재생에너지 발전량에 영향을 미치는 기상정보와 발전량을 함께 볼 수 있습니다.
🔋 에너지스크럼
태양광 발전소, ESS, EV 충전소 등 분산 전원을 통합 관리하고, 실시간 예측을 통해 공급과 소비의 균형을 맞춥니다. 클라우드 기반으로 보안성과 확장성까지 갖췄으며, 실제 전력거래소와 연계해 수요자 중심의 운영 최적화를 고도화하고 있습니다.
사회적 가치와 지속가능성
식스티헤르츠는 단순히 기술을 제공하는 기업을 넘어, 지속가능한 비즈니스 생태계를 만드는 파트너입니다.
RE100 기업 지원: 탄소중립 목표를 가진 기업에게 손쉬운 전력 전환을 위한 구독형 서비스를 제공합니다.
소상공인 재생에너지 전환 지원: 재정적 부담이 큰 초기 기업에게도 100% 재생에너지 사용 기회를 제공합니다.
사회적 성과 측정: 정량/정성 지표 기반의 프로젝트 영향 분석을 수행합니다.
햇빛발전소 기증: 에너지 취약계층 지원 및 지역사회 환원을 위한 프로젝트를 확산해 갑니다.
확장하는 비전
식스티헤르츠는 앞으로 다음과 같은 방향으로 에너지 혁신을 이어가기 위한 플랜을 실천하고 있습니다.
글로벌 플랫폼 확대
국내에서 검증된 기술을 아시아-태평양 지역으로 확장
지역 간 재생에너지 거래를 위한 인프라 확보
RE100 시뮬레이션 서비스 고도화
기업 맞춤형 컨설팅 제공
더 많은 기업의 참여를 유도
V2G 기술을 활용한 에너지 효율화
EV를 에너지 네트워크의 한 축으로 활용
분산 전원의 활용도를 높이는 차세대 전략
지속가능한 에너지 생태계를 위한 여정
식스티헤르츠는 단순한 에너지 기술기업을 넘어, 재생에너지 전환을 앞당기며, 기업과 사회가 함께 탄소중립을 향해 나아갈 수 있도록 다음 세대를 위한 기술과 협력의 터전을 마련하고 있습니다. 앞으로도 식스티헤르츠는 지속가능한 미래를 위한 실질적 변화를 만들어갈 것입니다.
#식스티헤르츠 #소셜벤처 #SDG #재생에너지 #RE100 #탄소중립 #탄소배출 #햇빛발전소
2025년 4월 24일
People & Culture
식스티헤르츠(60Hertz)를 소개합니다
일상을 지키는 특별한 기술을 만드는 팀
전력망을 안정적으로 관리하는 것은 매우 중요합니다.
전력망이 안정적으로 유지되지 않을 경우, 대규모 정전(black out)과 같은 국가적 재난 사태로 이어질 수 있기 때문입니다. 전력의 공급과 수요가 일치할 때, 대한민국의 전력망은 ‘60Hertz’라는 주파수를 유지합니다.
그래서 식스티헤르츠(60Hertz)는 우리의 안온한 일상을 지키는 균형을 의미합니다.
식스티헤르츠는 우리의 일상을 지키는 특별한 기술을 만듭니다. 🙂
다음 세대를 위한 에너지 기업
“우리가 기후위기를 막을 수 있는 마지막 세대이다”
우리 식스티헤르츠 구성원이 공유하는 세계관입니다.
지구 평균 온도가 매년 상승하고 있는 지금, 이를 해결할 중요한 열쇠는 ‘에너지 전환’입니다. 우리는 IT 기술을 통해 더 효율적이고 지속가능한 에너지 생태계를 구현하여 재생에너지 확산에 기여하고자 합니다.
기술로 이루어낸 작은 변화들이 모여, 다음 세대를 위한 큰 변화를 만들어 갈 수 있다고 믿습니다.🙏
식스티헤르츠와 함께해주세요!
사람들의 일상을 지키고 기후위기를 막기 위해 노력하는 식스티헤르츠 여정에 함께해주세요.🚀
우리는 지속가능한 미래를 위해 끊임없이 학습하고 함께 성장합니다.
변화를 두려워하지 않고 새로운 기술과 지식을 습득하고, 솔직하게 의견을 나누고, 서로에게 최고의 동료가 되고자 노력합니다.
식스티헤르츠의 세계관에 공감한다면 주저하지 말고 알려주세요. 우리는 내일을 향해 함께 달릴 동료를 기다립니다.🏃➡️
자세히 알아보기
👉 Embedded firmware Engineer (임베디드 펌웨어 개발, EE)
👉 Sales(영업 기획)
👉 Project Manager
👉 R&D 정부 과제 기획/관리
2025년 4월 23일
Insight
식스티헤르츠 홈페이지가 새로워졌습니다!
안녕하세요,
에너지 IT 소셜벤처 식스티헤르츠(60Hertz) 입니다. 🚀
오늘은 여러분께 새로워진 식스티헤르츠 공식 홈페이지 소식을 전해드립니다.
✨ 무엇이 달라졌을까요?
더 빠르고 직관적인 사용자 경험
복잡하지 않은 구조, 깔끔한 디자인, 그리고 모바일에서도 최적화된 화면으로 누구나 편리하게 정보를 확인하실 수 있습니다.
서비스 중심의 콘텐츠 구성
재생에너지 생산-관리-유통의 전반적인 Life cycle 솔루션을 제공하는 식스티헤르츠의 주요 기술과 서비스를 한눈에 확인할 수 있도록 정리했습니다.
글로벌 확장을 위한 다국어 지원
글로벌 파트너들과의 소통 강화를 위해 영문 페이지를 확장하였습니다.
🌍 왜 지금, 홈페이지를 개편했을까요?
식스티헤르츠는 국내를 넘어 베트남, 미국, 독일 등 글로벌 시장 진출을 본격화하고 있으며
에너지 전환, 탄소중립, 기후테크 등 빠르게 변화하는 흐름 속에서 식스티헤르츠의 기술과 철학을 더 많은 분들과 나누고 싶었습니다.
👀 지금 바로 방문해보세요!
새로워진 홈페이지에서 식스티헤르츠가 어떻게 기술로 기후 위기에 답하고 있는지 직접 확인해 보세요.
👉 https://60hz.io
여러분의 방문을 환영합니다!
앞으로도 더욱 투명하고, 혁신적이며, 사회적 가치를 실현하는 식스티헤르츠가 되겠습니다.
고맙습니다.
식스티헤르츠팀 드림
2025년 4월 21일