Tech
15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
2025년 12월 10일

15만개 발전소 데이터를 관리하는 아키텍처 설계 #2
: PVlib 벡터라이제이션과 데이터 구조 단순화로 이룬 식스티헤르츠의 스케일업
📂서론 | 15만 개의 발전소, 하나의 계산
식스티헤르츠(60Hertz)는 전국 15만 개 이상의 중소규모 재생에너지 발전소로부터 데이터를 수집하고, 이를 기반으로 발전량을 실시간 예측하는 시스템을 운영합니다. 전력망의 안정성을 지키기 위해, 이 예측값은 빠르고 정확하게 계산되어야 합니다.
대부분의 사람들이 ‘발전량 예측’이라고 하면 머신러닝 모델의 정확도를 떠올립니다. 하지만 예측 대상의 규모가 15만 개 정도 수준이 되면 모델의 정확도 뿐만 아니라 “이 계산을 어떻게 제 시간에 끝낼 것인가”도 중요한 문제가 됩니다. 정확도가 아무리 좋다고 하더라도 문제의 규모가 커졌다고 제시간에 답이 나오지 않는 시스템은 전혀 실용적이지 않겠지요. 이런 측면에서 식스티헤르츠의 기존에 사용하던 시스템(이하 v1)은 하루 발전량 예측 계산에 1시간 이상이 소요되었지만, 다음의 철학을 통해 효율적인 스케일업을 이루어냈습니다.
💡 코드 병렬화보다 중요한 것은, 데이터를 한 번에 계산할 수 있는 단순한 구조로 만드는 것.
v1과 달리, 개선한 시스템(이하 v2)은 데이터를 벡터화하고 구조를 단순화하여 동일한 작업을 단 3~5분 만에 끝냅니다. 본 포스트는 어떻게 식스트헤르츠가 위 성과를 이루어낼 수 있었는지를 데이터 엔지니어링 관점에서 설명하고 있습니다.
📂문제 정의 | 15만 번의 루프, 15만 번의 병목
v1에서의 파이프라인은 Apache Airflow를 기반으로 동작합니다. Airflow란 복잡한 데이터 파이프라인을 스케줄링하고 모니터링하는 워크플로우 관리 플랫폼을 말하며, 이를 이용해 15만 개 발전소들의 발전량 예측 작업을 여러 Task로 나누어 관리해왔습니다.
각 Task는 발전소의 메타 데이터와 기상 데이터를 조합해 python의 태양광 발전 시뮬레이션 라이브러리인 PVlib의 ModelChain API를 반복 호출하는 방식을 통해 이루어집니다. ModelChain은 PVlib에서 제공하고 있는 고수준 API로, 태양광 발전 시스템의 물리적 특성(모듈, 인버터 등)과 기상 데이터를 기반으로 발전량을 계산하는 과정을 캡슐화한 객체입니다. 위 API는 단일 발전소에 대한 시뮬레이션을 쉽게 수행할 수 있도록 설계되었으며, 발전량 예측 과정은 다음과 같이 시각화할 수 있습니다.
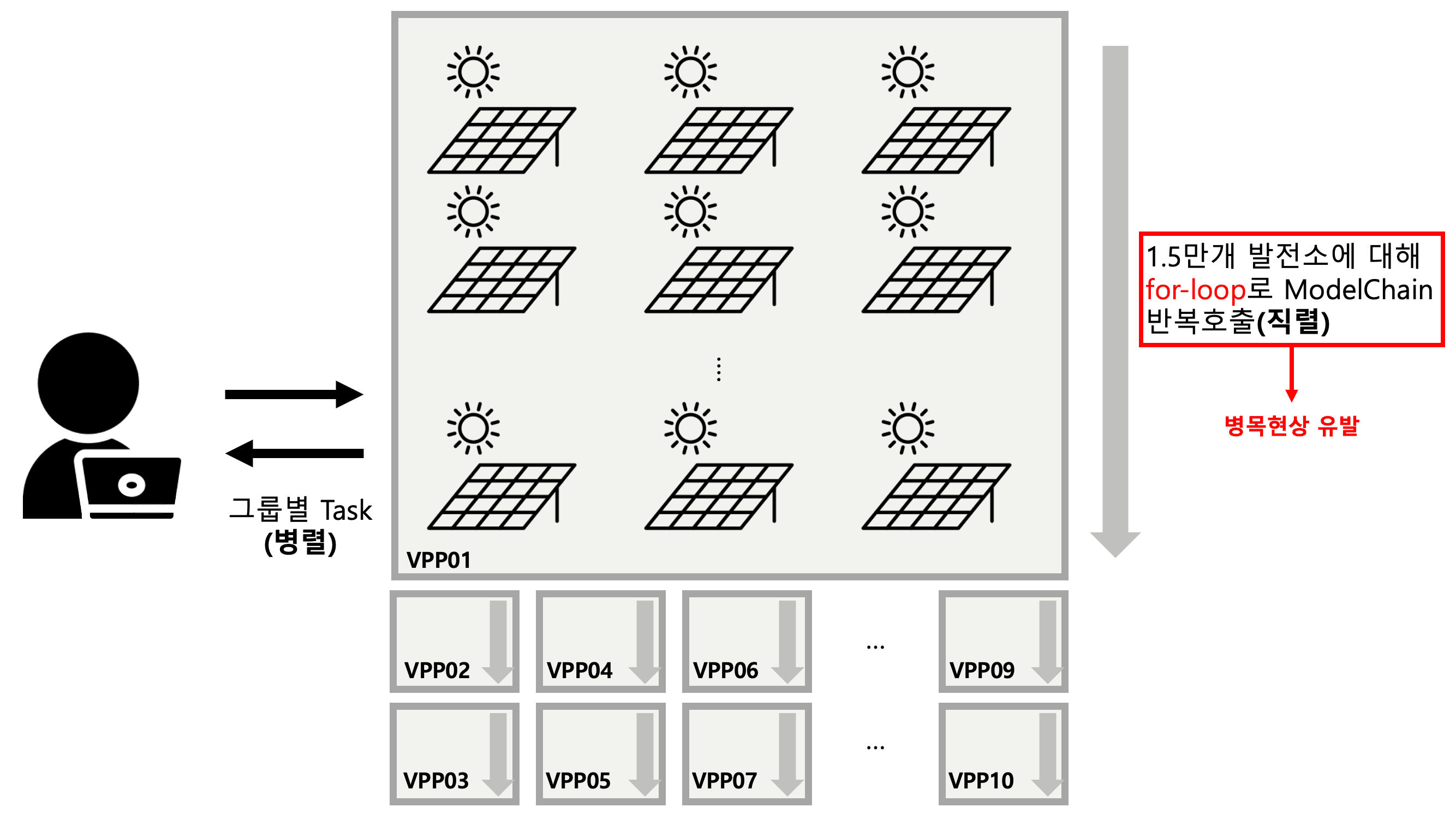
먼저 15만개의 발전소들을 10개의 그룹으로 만들어 각 그룹별로 Task가 병렬로 이루어지도록 합니다. 각 그룹 내에서는 1.5만개 발전소를 for-loop로 순회하며 직렬 형태로 ModelChain을 반복호출하게 됩니다. 즉, 병렬처럼 보여도 실상은 루프의 반복이 전체 시간을 지배했습니다. 위 아키텍쳐에서 병목 현상을 유발한 요인은 다음과 같이 정리할 수 있습니다.
계산 과정에서의 병목
데이터 관점에서 병목
데이터 I/O 관점에서 병목
이제 이 각각의 요인들이 어떻게 병목현상을 야기했는지, 그리고 어떻게 기술적으로 해결했는지 하나씩 살펴보도록 하겠습니다.
a. 계산 과정에서의 병목: 고수준 API인 ModelChain 을 변환하다
PVlib은 태양광 발전 시뮬레이션 표준 라이브러리로, 고수준 API(ModelChain)와 저수준 API 두 가지를 제공합니다. 각각의 API는 아래 표와 같이 정리할 수 있습니다.
고수준 API | 저수준 API | |
적용된 시스템 | v1 | v2 |
특징 | 태양광 발전 시스템 전체를 시뮬레이션 하는데 필요한 세부 단계들을 캡슐화하여 | 시뮬레이션의 각 세부 단계들을 구성하는 |
적합한 문제 | 단일 발전소 발전량 예측에 적합 | 대규모 발전소 발전량 예측에 적합 |
PVlib 내 | ModelChain | pvlib.irradiance |
장점 | 사용이 간편하며, 기본적인 시뮬레이션을 | 세밀한 제어가 가능하고, 대규모 데이터 |
단점 | 내부 로직이 숨겨져 있어 세부적인 제어가 | 사용자가 직접 시뮬레이션의 모든 단계를 |
고수준 API인 ModelChain은 단일 발전소 발전량 예측에 적합하지만, 15만개 발전소를 처리할 때는 15만 번의 객체 생성이 필요하여 지속적인 오버헤드를 유발합니다. 고수준 API 기반의 코드 예시는 다음과 같으며, python-level에서의 for loop을 중점적으로 사용하는 것을 확인할 수 있습니다.
반면 단순한 수학 함수로 구성된 저수준 API는 배열 전체를 한 번에 처리할 수 있어 대규모 데이터 처리에 적합합니다. 아래 코드를 비교해보시면 아시겠지만, python에서의 for-loop문이 완전히 사라진 것을 확인할 수 있습니다. python에서의 for-loop는 다음 단락에서 설명할 벡터화 연산의 이점을 이용할 수 없기 때문에 태생적으로 느릴 수 밖에 없습니다. 1.44억(=15 만개의 발전소 x 96 번)번의 연산이 저수준 API를 통해 벡터라이제이션됨으로써 C-level에서의 벡터화가 적용되어 빠르게 처리됨을 의미합니다.
b. 데이터 관점에서의 병목: 벡터화를 통한 데이터 처리속도 향상
Pandas와 NumPy는 내부적으로 C언어 수준(이하 C-level)의 벡터 연산을 사용하여 빠른 계산 성능을 제공하며, groupby 역시 이에 최적화된 연산입니다. 하지만 v1에서는 발전소들을 묶는 과정에서 agg(list)를 사용해 데이터를 리스트화했습니다. 이로 인해 메모리상에 동일한 변수형이 연속적으로 배치되어야 하는 NumPy 배열의 구조적 장점이 깨지게 되었습니다. 그 결과 배열 내 값들이 불가피하게 object 타입으로 변환되면서 벡터화의 이 점을 완전히 잃게 되었습니다.
데이터가 벡터화로 구성이 되면 다음의 이유로 성능이 매우 빨라지게 됩니다.
먼저 데이터 형식이 동일하면, SIMD(Single Instruction, Multiple Data) 기술을 활용하여 CPU가 단 한 번의 명령어로 여러 데이터(레지스터 단위)를 동시에 처리하여 물리적인 연산 속도를 획기적으로 높입니다.
또한, Python 인터프리터는 동적 타이핑 언어 특성상, 반복문을 돌 때마다 변수의 타입을 확인하고 적절한 연산 함수를 찾는 과정인 Dispatching을 거칩니다. 반면, 벡터화된 NumPy 배열은 생성 시점에서 동일한 변수형이 보장이 되기 대문에 연산을 시작하기 전에 한 번만 타입을 검사하며, 이후에는 별도의 확인작업 없이 기계어 레벨에서 값을 밀어넣기 때문에 오버헤드가 0에 수렴합니다.
마지막으로 데이터가 메모리에 연속적으로 배치되기 때문에 v1처럼 주소(Pointer)를 따라 여기저기 메모리를 찾아다는 비용인 Dereferencing cost가 줄어들고, CPU 캐시 적중률이 극대화되며, 컴파일러가 자동으로 병렬화 최적화를 수행할 수 있습니다.
다음은 v1에서 사용한 예제 코드입니다.
C-level에서의 연산은 데이터가 동일한 타입의 데이터가 연속된 메모리 블록에 저장되어 있을 때 가능합니다. 예를 들어, int64 로 구성된 배열은 실제값들이 빈틈없이 붙어있는 형태이며, 첫 번째 값의 주소만 알면 “여기서 부터 1000개의 값을 더해라”와 같은 명령을 단 한 번의 CPU 명령어로 처리할 수 있습니다.
하지만 object 타입으로 구성된 배열은 데이터가 아닌 데이터의 주소를 저장하게 됩니다. 실제 데이터는 메모리 여기저기에 흩어진 상태이며, 각 데이터의 타입도 제각각일 수 있습니다. 이렇게 되면 C-level 연산이 어려워져 속도가 느린 Python 인터프리터가 개입하게 되고, 이로 인해 비효율적인 연산 방식을 수행하게 됩니다.
v1의 경험이 남긴 교훈은 단순했습니다.
복잡한 병렬 처리로 비효율적인 구조를 보완하려 하지 말라. 데이터를 단순하게 만들어라.
이를 기반으로 새로 개선한 v2의 철학은 세 가지였습니다.
루프 제거: Python for 루프를 없앤다.
벡터화: NumPy 브로드캐스팅을 활용한다.
구조 단순화: 중첩 list 대신 2D long-form 구조 사용.
v1이 “15만 개 발전소 객체”를 다뤘다면, v2는 “15만 개의 발전소 정보가 동일한 형태로 줄지어 저장된 tilt, azimuth 배열”을 다룹니다. 데이터 중심의 설계로 전환하면서 코드 구조가 근본적으로 달라지게 된 것입니다.
c. 데이터 I/O 관점에서의 병목: CPU보다 느린 건 데이터였다
저수준 API를 통해 엄청난 속도의 발전을 이루었지만, 데이터 I/O에서의 문제가 남아있었습니다. 기존 v1 방식은 각 발전소 루프마다 필요한 기상예보데이터(NWP; Numerical Weather Prediction)를 개별 Parquet 파일에서 읽어왔습니다. 15만 개의 발전소가 10개의 Task로 나뉘어져 있어도, 각 Task 내에서는 1.5만 번의 파일 접근을 시도하여, 엄청난 I/O 병목을 유발하였습니다. 쉽게 설명하자면 택배로 보낼 물품 1.5만개를 한 대의 오토바이 퀵서비스로 반복적으로 보내고 받는 것과 다르지 않습니다. v2방식은 1) 인덱스 기반 조회와 2) 대량 데이터 전송(예: fetch_df_all()) 방식을 통해 택배차 한 대가 1000개의 택배를 한꺼번에 운송하는 방식과 비슷하게 문제를 해결했습니다.
먼저 모든 NWP 기상 데이터를 Oracle DB에 저장한 뒤, 15만 개 발전소의 위치 인덱스를 활용해 단일 SQL 쿼리에서 필요한 데이터를 한 번에 조회할 수 있도록 구조를 개선했습니다. 이를 통해 쿼리 단위를 통합해 네트워크 왕복 횟수를 최소화하고 I/O 과정에서의 효율을 크게 높였습니다.
또한, execute() 나 executemany() 등의 대용량 데이터 I/O에 적합하지 않은 표준 Python DB-API 방식 대신, Apache Arrow 기반의 python-oracledb DataFrame API를 사용했습니다. 이 방식은 DB에서 읽어온 대량의 데이터를 즉시 NumPy 배열로 변환하여, Python 객체 생성 오버헤드를 건너뛰고 제로카피에 가까운 메모리 효율을 달성합니다. 위 과정을 시각화하면 다음과 같습니다.
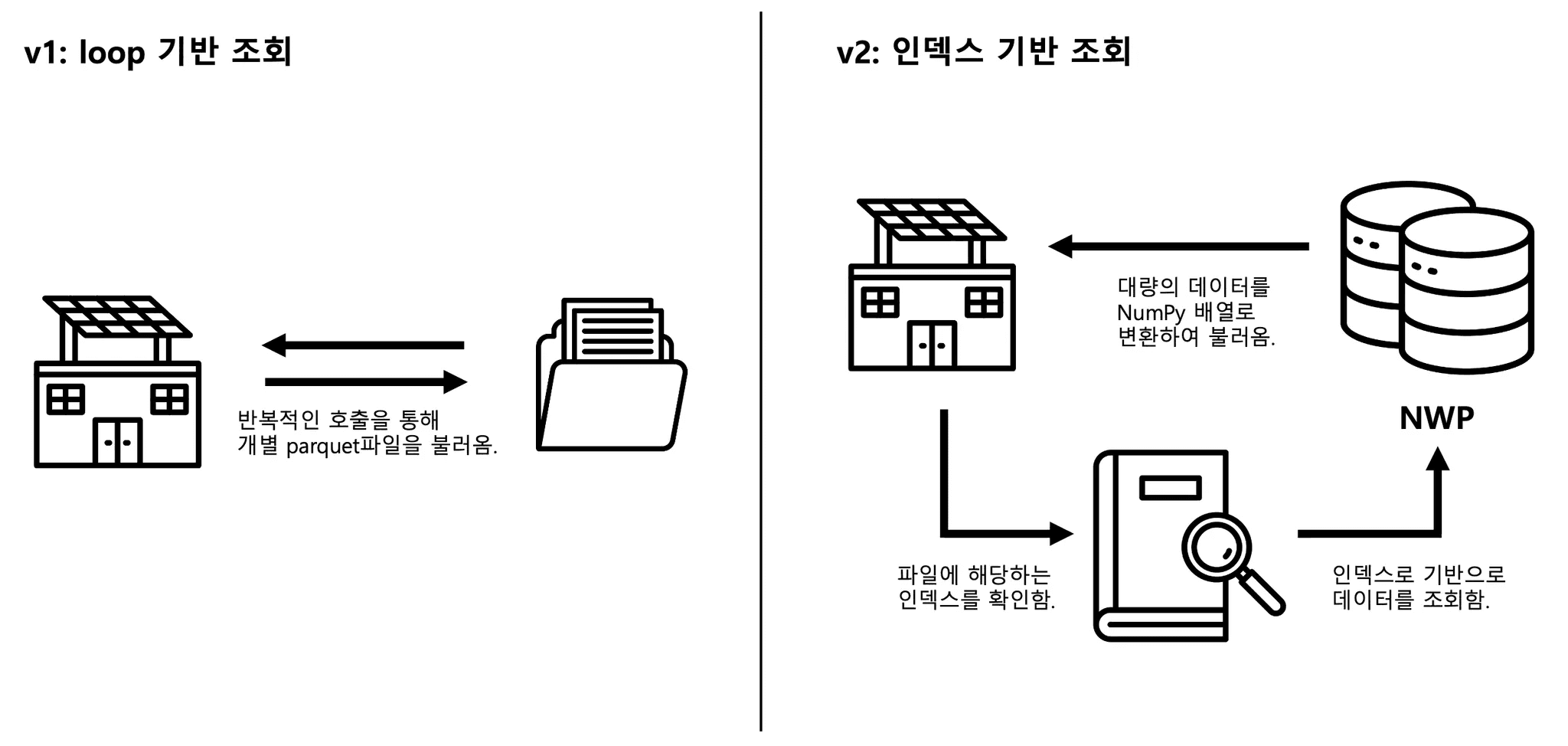
📂숫자로 증명된 구조의 힘
위의 세 병목 현상을 해결하여 v2방식은 데이터 로딩 속도만 수십 배 향상시켰고, 이는 전체 파이프라인 처리 시간 단축에 결정적으로 기여했습니다. 데이터 처리 방식을 v1에서 v2로 바꾸면서, 다음의 성능을 달성했습니다.
구분 | 방식 | 처리 시간 | 코드 라인 수 |
|---|---|---|---|
v1 | 발전소별 Python for-loop | 1시간 이상 | ~1200 |
v2 | 벡터 연산에 최적화된 데이터 구조 | 3분 내외 | ~400 |
v2는 24 코어를 모두 활용하며 3분 만에 계산을 완료함으로써 약 20배의 성능 향상을 달성했습니다. 하지만 여기서 더 주목해야 하는 것은 코드 라인의 수입니다. 복잡한 병렬처리, 예외 처리, 데이터 파편화로 가득했던 1,200개 라인의 코드가, 데이터 구조를 단순화하자 400개 라인의 명료한 벡터 연산 코드로 바뀌었습니다. 성능과 유지보수성, 두 마리 토끼를 모두 잡은 것 입니다.
📂이런 문제를 풀고 싶으시다면..
현장에서는 서비스가 어떻게 돌아가는지 뿐만 아니라 얼마나 잘 돌아가는지도 중요합니다. 그리고 상품화의 대상 및 문제 공간이 확대가 되면서 폭넓은 통찰 또한 필요합니다. 이러한 흐름 속에서 식스티헤르츠는,
단순한 데이터 수집이나 ML 모델을 학습시키는 것이 아닌, 문제의 본질을 이해하는 엔지니어를 원합니다.
15만 개의 수준의 거대한 데이터를 다룰 때 어떤 방식이 더 빠르고 효율적인지, 그 근본적인 원리를 이해하고 최적의 구조를 선택할 수 있는 분을 찾습니다.
단순히 데이터를 불러오는 것에 그치지 않고, 어떻게 하면 불필요한 네트워크 왕복 횟수를 최소화하여 전체 시스템의 속도를 높일 수 있을지 치열하게 고민하는 분을 원합니다.
여러 작업을 동시에 처리하는 방식과 거대한 데이터를 한 번에 계산하는 방식의 차이를 명확히 이해하고, 상황에 맞게 적절한 해결책을 제시할 수 있는 분과 함께하고 싶습니다.
우리는 코드가 '돌아가는 것'에 만족하지 않고, '왜 이렇게 돌아가야만 하는지', 그리고 ‘현재보다 더 효율적인 방법은 없는지’를 끊임없이 질문하는 엔지니어와 함께 스케일업의 한계를 넘고 싶습니다.
계산 최적화는 왜 중요할까요?
빠른 계산은 곧 효율적인 서버 운영을 의미하고, 효율적인 서버 운영은 에너지 절약으로 이어집니다. 1시간 걸리던 작업을 3분으로 줄이면, 그 차이인 57분만큼의 서버 리소스를 아낄 수 있습니다. 이것이 바로 고도화된 IT 기술과 정교한 데이터 아키텍처가 곧 탄소 효율로 이어지는 방식입니다.
식스티헤르츠는 '데이터로 에너지를 절약하는 회사'입니다. 이 거대하고 의미 있는 계산에 동참하고 싶다면, 지금 바로 식스티헤르츠의 문을 두드려 주시기 바랍니다.

——————————————————————————————————————————
📚 이 글이 흥미로우셨다면? 같은 시리즈 글도 읽어보세요!
1. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #1
2. 15만개 발전소 데이터를 관리하는 아키텍처 설계 #2 (방금 읽은 글이에요)
——————————————————————————————————————————
🌟식스티헤르츠와 함께 멋진 개발 여정을 직접 만들어갈 동료를 기다립니다!