Tech
How We Handle Data from 150,000 Power Plants
December 3, 2025

Building a Large-Scale On-Premises Data Processing Architecture
Our team recently built an on-premises system that collects real-time data from more than 150,000 small and mid-sized renewable power plants across the country, and uses this data for power generation forecasting and monitoring. While cloud environments are the industry norm today, designing a large-scale system on-premises was a significant challenge for us due to our client’s strict security policies and data ownership requirements.
Challenges We Needed to Solve
The goals of the project were distilled into two core priorities: stability and scalability.
Reliable Data Ingestion: The 150,000 RTUs (Remote Terminal Units) use different communication networks and protocols such as LoRa, NB-IoT, and HTTPS. We needed to integrate all of them into a single system and ensure zero data loss during ingestion.
Real-time Processing and Scale-Out: The collected data needed to be processed immediately, and all components had to be designed with horizontal scalability in mind to flexibly handle future increases in the number of power plants.
Advanced Analytics Capabilities: Beyond simple data collection, we needed anomaly detection features that combine external weather data with power generation forecasts and comparisons against actual measurements.
Security and High Availability (HA): A high-availability architecture was essential to defend against external attacks and ensure continuous service even if some servers failed.
Technology Stack Selection – Why We Chose These Technologies
<Why We Chose a Reactive Stack>
When handling large-scale IoT data, the first challenge we considered was concurrency. While the traditional servlet-based Spring MVC is a well-proven technology, its thread-based model clearly has limitations for handling connections from 150,000 sites simultaneously.
Therefore, we chose Spring WebFlux. Operating in an asynchronous, non-blocking manner, WebFlux can handle a large number of concurrent connections with a small number of threads.

There were three decisive reasons for choosing WebFlux:
First, its event-loop model allows high concurrency, handling tens of thousands of connections simultaneously.
Second, it supports backpressure through Reactor’s Flux/Mono, automatically balancing speed differences between data producers and consumers.
Third, it offers memory efficiency, operating with fewer resources than a thread-based model.
<Event Processing with Kafka>
Introducing Apache Kafka was one of the most important architectural decisions in this project. We chose Kafka to reliably handle the simultaneous influx of data from 150,000 sites.
Kafka served more than just a simple message queue. It buffered sudden traffic spikes and decoupled the collection system from the processing system, allowing each component to scale independently and respond to failures.
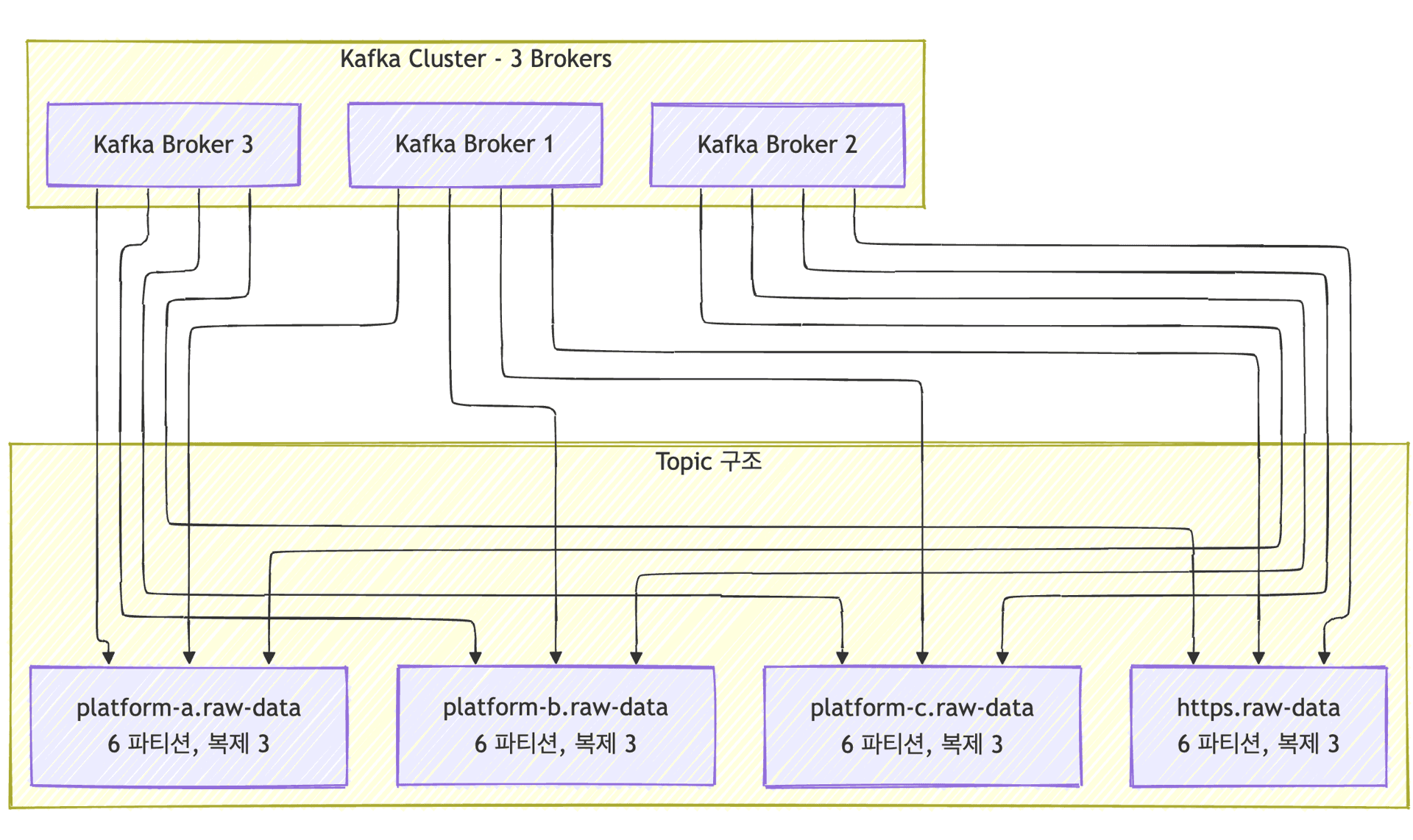
Topic design was carefully planned. Topics were separated by protocol (IoT Platform A, B, C, HTTPS) to allow independent management according to each channel’s characteristics. Each topic consisted of six partitions for parallel processing, and a replication factor of three ensured data safety in case of broker failures. Messages were retained for seven days, providing sufficient recovery time in the event of unexpected issues.
Architecture Design – Data Flow
With the technology stack decided, the next step was figuring out how to combine them. We designed the system into four main areas, following the flow of data.
Data Collection Area
This is the entry point for data sent from RTU devices scattered across power plants nationwide. The data passes through firewalls and L4 switches before reaching the collection servers, where it is processed by protocol and published to Kafka.
<Data Collector>
An asynchronous server based on Spring WebFlux, converting various IoT protocols into a standardized internal format.
Non-blocking message publishing is implemented using reactor-kafka, and Reactor’s backpressure feature regulates the load sent to the Kafka cluster. It is container-based, allowing immediate scaling in response to increased traffic.
<Two-Layer Load Balancing: L4 Switch, Nginx, Docker>
In an on-premises environment without cloud-managed load balancers, we achieved high availability and scalability by layering hardware L4 switches and software load balancers for flexible traffic distribution.
Incoming traffic is first distributed to multiple servers by the L4 switch, and within each server, Nginx distributes requests to collection server instances packaged as Docker containers. The hardware switch handles fast network-level distribution and health checks, while Nginx manages detailed application-level routing.
Nginx uses a Least Connections algorithm, directing requests to the instance with the fewest active connections and automatically excluding failed instances through passive health checks.
Event Hub Area
Although Kafka topic design may seem simple, it requires careful consideration. We separated topics by protocol to isolate channels from affecting each other while ensuring scalability through partitioning.
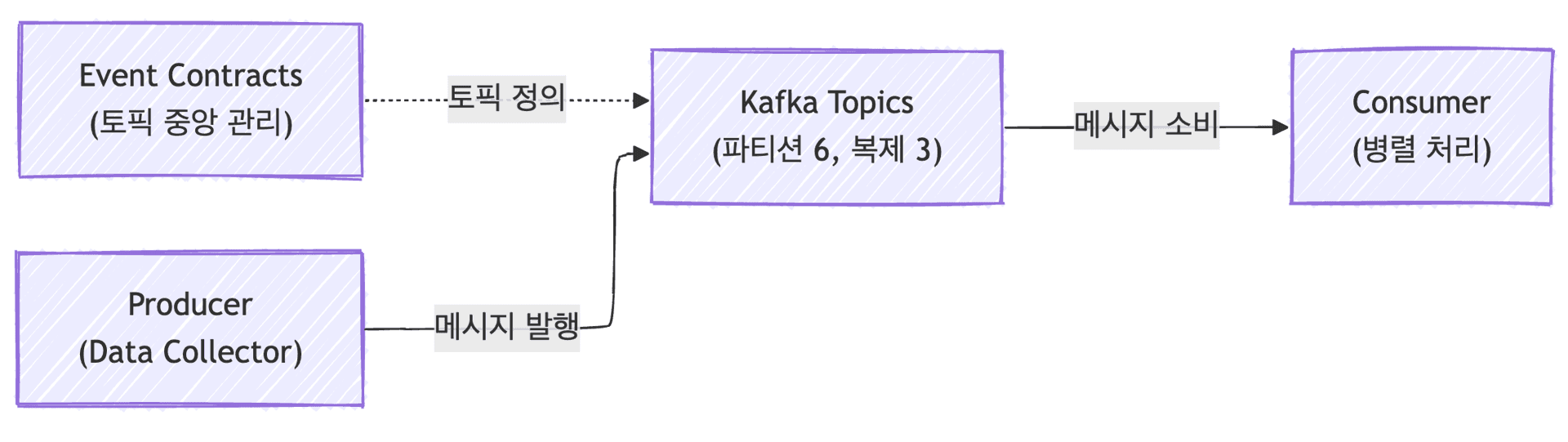
Topic naming followed a consistent convention: {namespace}.collector.{platform}.raw-data, with all topic names centrally managed as constants in the Event Contracts module.
Partitioning strategy was also crucial. Each topic was divided into six partitions to enable parallel processing by consumers. Partition rebalancing ensures automatic load redistribution when consumers are added or removed.
Data Relay and Storage Area
The data accumulated in Kafka had to be safely transferred to the internal database. For security, we placed a relay server in the DMZ to consume Kafka messages and store them in the internal DB.The consumer module consumes Kafka messages and stores them in the database. Our first focus was optimizing batch processing. Messages were not processed individually but batched for DB storage: up to 1,000 messages per batch, or processed when at least 1MB of data was accumulated or 3 seconds had passed. This greatly improved DB insert performance.
To maximize throughput, we actively utilized consumer groups. Six consumers processed six partitions in parallel, each handling messages independently.
Retry and error handling were also important for stability. Temporary errors were retried up to three times at one-second intervals. If batch storage failed, fallback to individual inserts was used to preserve as much data as possible. Data that still failed was stored in a separate error table for future analysis.
Power Generation Forecasting and Analysis Area
Simply storing data alone does not create value. The analysis and forecasting server analyzes and predicts based on the collected data.
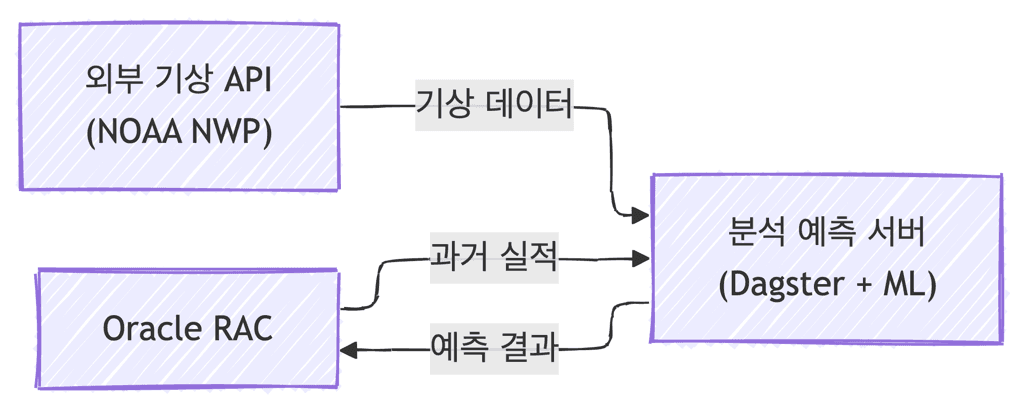
The forecasting server uses Dagster-based workflow orchestration. Dagster manages the scheduling and execution of the data pipeline, integrating data collection, preprocessing, and forecast execution into a single workflow. Pipeline execution history and dependencies are systematically managed.
Integration with external data was essential to improve prediction accuracy. The Python analysis pipeline collects weather forecast data via NOAA NWP (Numerical Weather Prediction model) to capture weather factors affecting solar power generation.
The power generation forecasting model combines historical generation data with weather data to predict future output, and the results are stored in the database for analysis and reporting.
Web Service Provision Area
This area provides web services where users can monitor power plant status and control the system.

The web service is built on a typical 3-tier architecture. The front-end WEB layer handles static resource serving and SSL/TLS termination, and load balances across two servers via L4 switches. Incoming requests are proxied to the WAS servers.
The WAS layer consists of three application servers to ensure high availability. The Business API Service running here is a Spring Boot-based RESTful API server that handles the core business logic of the monitoring service. Continuous uptime was a mandatory requirement. The database is duplicated using an Oracle RAC Active-Active cluster, all layers operate at least two servers, and L4 load balancing is configured. Thanks to the Docker-based setup, the system can recover quickly in the event of a failure.
The batch layer uses Spring Batch to perform large-scale data processing tasks, such as periodic statistics aggregation and report generation.
Collection Server Cluster Performance Validation
To validate the architecture under large-scale traffic conditions, we conducted rigorous load testing. Assuming 150,000 devices send data evenly over 60 seconds, the required throughput would be about 2,500 TPS.
150,000 Requests / 60 Seconds = 2,500 TPS
However, in reality, devices are not perfectly distributed. Traffic spikes often occur when many devices transmit simultaneously. Without client-side throttling, the server may need to handle sudden traffic exceeding 10,000 TPS. We aimed to secure approximately 4–5 times the average capacity to handle such traffic surges.
Load testing with Grafana k6 confirmed that a single node could process 3,000 collection requests per second (3,000 TPS) and the entire cluster could handle 12,000 requests per second (12,000 TPS) without delay. The non-blocking architecture of Spring WebFlux, Kafka’s traffic buffering, and the consumer’s batch insert strategy worked synergistically, ensuring stable processing without data loss even under load exceeding theoretical peak throughput.
Retrospective – Lessons Learned
<Advantages of Asynchronous Non-Blocking>
Applying Spring WebFlux in practice allowed us to experience the benefits of reactive programming in a large-scale IoT environment.
We achieved high throughput with minimal resources and ensured overall system stability through backpressure control.
<Kafka is More Than a Message Queue>
Through Kafka, we realized the true value of an event streaming platform.
Beyond simple message delivery, it reduces coupling between systems, enables failure isolation, and retains data for reprocessing, significantly enhancing overall architectural stability.
<Scalability Must Be Considered from the Start>
By designing a horizontally scalable architecture, we could handle increased traffic simply by adding servers.
Container-based architecture and Kafka’s partitioning mechanism made this possible.
<Flexible Infrastructure is Possible Even On-Premises>
Even without the cloud, we achieved flexible load balancing by layering L4 switches and Nginx.
The key was clearly separating the roles of each layer and managing configurations as code.
Conclusion
Building a system to handle real-time data from 150,000 sites in an on-premises environment was no easy journey.
Instead of relying on the convenience of cloud-managed services, we had to personally decide and implement every step, from hardware selection and network segmentation to defining server roles and configuring redundancy.
However, we learned a lot in the process. Utilizing Spring WebFlux and Kafka to reliably handle large-scale traffic, as well as software load balancing with Nginx and Docker to create a flexible architecture, has become a major asset for our team.
We hope this article provides some guidance for engineers considering large-scale traffic handling in on-premises environments.
